AutoAugment 톺아보기
AutoAugment
Abstract
수동으로 설계되는 data augmentation을 자동으로 검색하기 위해서 AutoAugment를 제안했다.
여러가지 sub policies로 구성된 설계 공간을 탐색하고 각 미니 배치의 각각 이미지에 대해 랜덤으로 선택되었다.
sub policies는 Rotation, Translation, shearing 과 같은 처리 방법 과 적용되는 확률,크기 로 구성된다.
검색알고리즘을 사용한다.
Introduction
data augmentation은 data domain의 불일치에 대하여 모델을 학습시키기 위해 사용한다. 객체 분류는 종종 수평으로 뒤집거나 변환하는 것에 영향을 받지 않는다.
현재 머신러닝과 컴퓨터 비전의 커다란 초점은 더 나은 네트워크 구조를 설계하는 것이다. 더 많은 불변량을 포함하는 더 나은 data augmentation을 찾는데는 관심이 별로 없었다.
ImageNet에서 도입 된 image augmentation은 표준으로 남아있다. 특정 데이터 셋에 대해서 data augmentation이 발견 된 경우에도 다른 데이터 셋으로 효과적으로 전송되지 않는다.
예를 들어서 CIFAR10에서의 수평으로 뒤집어서 변환하는 작업은 효과적이지만 MNIST에서는 그렇지 않다. 이러한 데이터 셋에는 서로 다른 대칭이 있기 때문이다.
이 논문에서는 목표 데이터 세트에 대한 효과적인 data augmentation을 찾는 프로세스를 자동화하는 것이 목표다. 이 논문의 각 보강 정책은 가능한 augmentation 작업(Translation, Rotation, Color normalization 그리고 적용될 확률과 적용되는 크기)의 몇가지의 선택과 순서를 표현한다. 탐색알고리즘으로 강화학습 을 사용한다.
- 최상의 data augmentation을 찾을 수 있다.
- 학습 된 보강 정책을 새로운 데이터 셋에 전송 할 수 있다.
Related Work
image augmentation은 수동으로 설계되었고 데이터 셋 별로 최상의 성능을 가진다.
- MNIST :
Elastic Distortions(탄성 왜곡),Scale,Translation,Rotation을 보통 사용한다. - CIFAR10 :
Random Cropping,Image Mirroring,Color Shifting,Whitening을 보통 사용한다.
위와 같은 방법은 수동으로 설계되므로 전문 지식과 시간이 필요하다. 그래서 data augmentation을 찾기위한 자동화 방법을 소개한다. 이 논문은 데이터에서 모델의 구조를 발견하기 위해 강화 학습이 사용 된 구조를 검색하는데에서 영감을 얻었다고 한다.
- Smart Augmentation : 동일한 클래스에서 두 개 이상의 샘플을 병합해서 자동으로 데이터를 생성하는 네트워크를 제안했다.
- Tran et al. : 훈련 데이터로부터 학습한 분포에 기초하여 데이터를 생성하기 위해 베이지안 접근법을 사용했다.
- DeVries와 Taylor : 학습 된 형상 공간에서 간단한 변형을 사용해 data augmentation을 하였다.
- GAN을 자주 사용하였다.
AutoAugment
- Searching for best Augmentation policies Directly on the Dataset of Interest
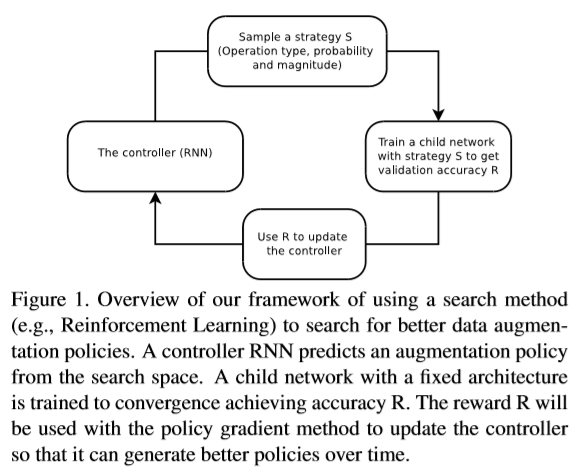
최상의 보강 정책을 찾는 문제를 개별 탐색 문제로 공식화한다. 이 방법은 탐색 알고리즘 과 탐색 공간 이라는 두 가지 구성 요소로 구성된다.
탐색 알고리즘은 어떤 이미지 처리 작업을 사용할지, 각 배치에서 작업을 사용할 확률 및 작업의 크기에 대한 정보가 있는 보강 정책 S를 샘플링한다. AutoAugment의 핵심은 보강 정책 S가 고정 아키텍처로 신경망을 훈련시키는데 사용될 것이고 검증 정확도 R이 컨트롤러(RNN)를 업데이트 하기 위해 다시 전송 될 것이다. 컨트롤러(RNN)은 경사 방법으로 업데이트 된다.
NASNet
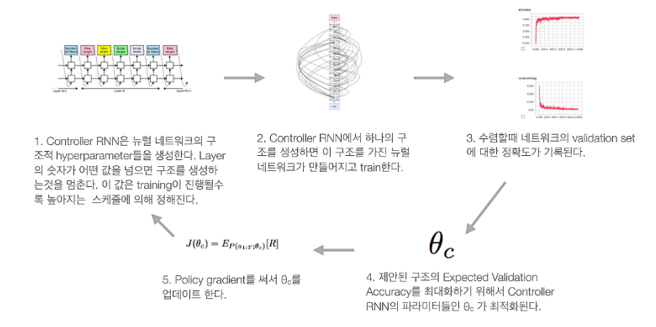
위 그림을 이해하기 위해서는 NAS와 NASNet을 알아야한다. NAS는 딥러닝 모델의 구조를 학습해서 구조를 생성하는 모델이다.
출처 : https://www.youtube.com/watch?v=XP3vyVrrt3Q
NAS는 파라미터를 하나하나씩 전부다 찾아주고 네트워크를 만들고 훈련하는데 직렬적인 구조를 갖기 때문에 시간이 너무 오래걸린다는 단점이 있다. 그래서 아래 NASNet 논문에서는 새롭게 구조를 개선하였다.
1
2
3
B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le.
Learning transferable architectures for scalable image recognition.
In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017.

이전 같은 경우 각 모델 layer에 해당하는 파라미터 값을 하나하나씩 전부 찾아준거라면 이번 같은 경우는 연산 을 어떤 것을 사용할지 찾아주는 구조다.
사용하는 연산은
1
2
3
4
5
6
7
8
9
10
11
12
13
identity
1x3 + 3x1 conv
1x7 + 7x1 conv
3x3 dilated conv
3x3 average pooling
3x3 max pooling
5x5 max pooling
7x7 max pooling
1x1 conv
3x3 conv
3x3 depthwise-separable conv
5x5 depthwise-separable conv
7x7 depthwise-separable conv
2개의 input layer를 선택하고 연산 중 하나를 선택해서 ADD, Concat 중 하나를 선택해 결합한다.

위 그림은 가장 성능이 좋은 NAS의 구조다. 이렇게 B개의 블럭이 모여서 하나의 Convolution Cell을 만드는데 이 Cell들이 모여서 네트워크를 만든다. Convolution Cell에는 Normal Cell, Reduction Cell 이렇게 두가지 Cell이 있다.
- Normal Cell : 입출력의 가로 세로 크기가 같은 Cell
- Reduction Cell : 출력이 입력의 절반의 크기를 같는 Cell
이렇게 B개의 블럭을 모아서 Reduction Cell과 Normal Cell을 생성하고
위와 같은 구조로 만들어 준다.
controller RNN of AutoAugment
최종적으로 AutoAugment의 RNN controller는 아래와 같은 구조를 가진다.
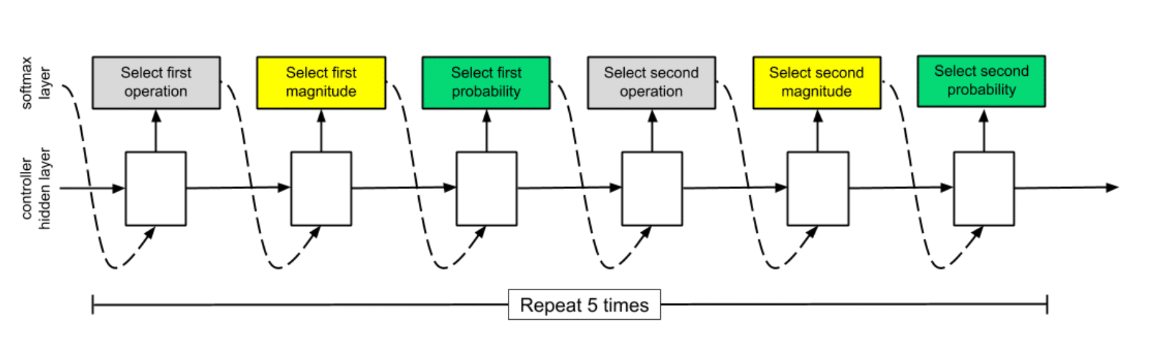
search space detail
보강 정책은 5개의 하위 정책으로 구성되며 각 하위 정책은 2개의 보강 방법으로 구성되어 순서대로 적용된다. 그리고 수치 두가지를 나타낸다.
- 보강 방법이 적용될 확률
- 보강 방법에 대한 하이퍼 파라미터

위 그림은 탐색 공간에 5개의 하위 정책이 포함 된 정책의 예를 보여준다. 첫번째 하위 정책은 ShearX를 순차적으로 적용한 다음 Invert를 적용한다. ShearX의 확률은 0.9며 적용시에 10 ~ 7의 크기를 가진다. 그런 다음 0.8의 확률로 Invert를 적용한다.
1
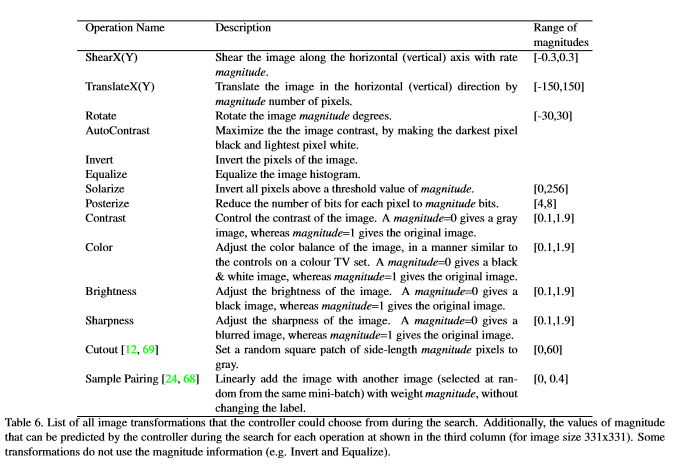
ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness, Cutout, Sample Pairing
탐색 공간에는 총 16개의 작업이 있다. 탐색 알고리즘을 사용해서 크기를 찾을 수 있도록 크기 범위를 10개의 값(균일한 간격)으로 이산화한다. 11개의 값으로 적용 할 확률도 이산화한다. 즉, \((16*10*12)^{2}\) 에서의 탐색 문제다. 그러나 다양성을 높이기 위해서 5개의 하위 정책을 동시에 찾는 것이다. 그래서 \((16 * 10 * 12)^{10} \approx 2.9 * 10^{32}\)의 엄청나게 많은 가능성을 가진다.
search algorithm detail
탐색 알고리즘은 RNN 컨트롤러와 Proximal Policy Optimization algorithm으로 구성된다. 각 단계에서 컨트롤러는 softmax로 예측한다. 그리고 다음 예측은 다음 단계로 포함된다. 컨트롤러에는 총 2개의 보강 연산이 있는 5개의 하위 정책과 그에 해당하는 크기 및 확률을 예측하기 위해 총 30개의 softmax의 예측이 있다.
1
5(하위 정책)*(2(보강 방법) + 2(확률) + 2(크기)) = 30
The training of controller RNN
어떠한 보강 정책이 childmodel의 일반화를 개선하는데 얼마나 좋은지에 대해서 학습한다. 이 실험에서는 childmodel의 일반화를 측정하기 위해서 검증 세트를 따로 보관했다. childmodel은 학습할 데이터 셋에 5개의 하위 정책을 적용하여 생성 된 데이터로 훈련된다. 그런 다음 검증 셋에서 childmodel을 평가하여 정확도를 측정한다. ward signal로 사용된다. 각 데이터 셋은 약 15000개의 보강 정책을 샘플링한다.
Architecture of controller RNN and training hyperparameters
논문 : B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le. Learning transferable architectures for scalable image recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017
컨트롤러 RNN은 각 layer에서 100개의 hidden unit과 각 아키텍처 결정과 관련된 2개의 convolution cell에 대해 2x5B softmax(위 논문에서는 B는 일반적으로 5)의 예측을 갖는 one layer LSTM이다. 컨트롤러 RNN의 10B 예측 각각은 확률과 관련된다. childmodel의 공동 확률은 이러한 10B softmax에서 모든 확률의 곱이다. 이 공동 확률은 컨트롤러 RNN의 기울기를 계산하는데 사용한다. 기울기는 childmodel의 검증 정확도에 의해서 조정되고 컨트롤러 RNN을 업데이트한다.
- 학습 속도 0.00035의 PPO(Proximal Policy Optimization)을 사용한다.
- entropy penalty : 가중치의 0.00001
- 0.95의 가중치를 가진 이전 보상의 지수 이동 평균
- 컨트롤러 가중치 : -0.1 ~ 0.1 균일하게 초기화
탐색이 끝나면 최고 5개 보강 정책의 하위 정책을 단일 보강 정책(25개의 하위 정책)으로 연결한다. 25개의 하위 정책이 포함된 최종 보강 정책은 학습하는데 사용되고 이 논문을 개선하기 위해 유전자 프로그래밍 또는 random search와 같은 다른 이산 검색 알고리즘을 사용할 수 있다.
1
5(보강 정책) * 5(하위 정책) * (2(보강 방법) + 2(확률) + 2(크기))
Experiments and Results
CIFAR10
- 4000개 추출 사용
- WideResNet-40-2(layer : 40, widening factor : 2) 모델을 사용
- 120 epoch
- weight decay : \(10^{-4}\)
- learning rate : 0.01
- cosine learning decay with one annealing cycle
CIFAR100
- CIFAR10과 같다.
SVHN
- 1000개 추출 사용
- 나머지는 CIFAR10과 동일
Augmentation
Final Policy
- CIFAR10

- SVHN

- ImageNet
