EfficientDet 톺아보기 2
이전 포스트에서는 EfficientNet을 간략하게 정리하였다. 이제 속도와 정확성 측면에서 효과적인 object detection network인 EfficientDet을 알아보자.
Abstract
효과적인 network를 만들기 위해서 먼저 BiFPN(weighted bi-direction pyramid network)를 제안한다.
그리고 모든 backbone network, feature network, box/class prediction network을 위해 resolution, depth, width를 복합적으로 scaling하는 compound scaling 방법을 제안한다. 이 두가지 방법으로 EfficientDet을 개발하였다.
Introduction
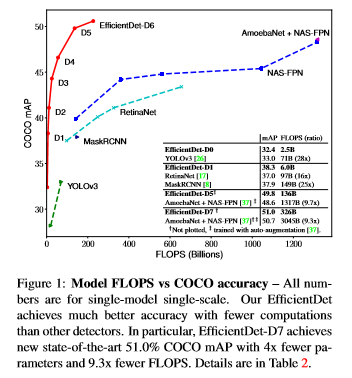
최근들어 매우 정확한 object detection을 위해서 많은 발전이 있었다. 하지만 그에 따른 많은 비용으로 인해 속도가 느려지는 단점이 있다. 예를 들어 NASFPN 같은 경우는 state of the art 정확도를 달성하기 위해서 167M 매개변수와 3045FLOPS가 필요하다.
이렇게 연산량이 많고 모델의 크기가 크면 실생활에 사용하기 어렵다. 그래서 anchor based network, one stage detector, pruning 등 많은 방법이 나왔다. 하지만 이러한 방법은 속도가 높아짐에 따라서 정확도가 낮아진다. 그래서 정확도와 속도를 둘다 잡기 위한 체계적인 연구를 진행한다.
different input features are at different resolutions, we observe they usually contribute to the fused output feature unequally
- 쉽고 빠른 multi scale feature fusion을 위한 bidirectional feature network인 BiFPN을 제안한다.
- backbone, feature network, box/class network, resolution을 함께 scale up하는 compound scaling 방법을 제안한다.
BiFPN
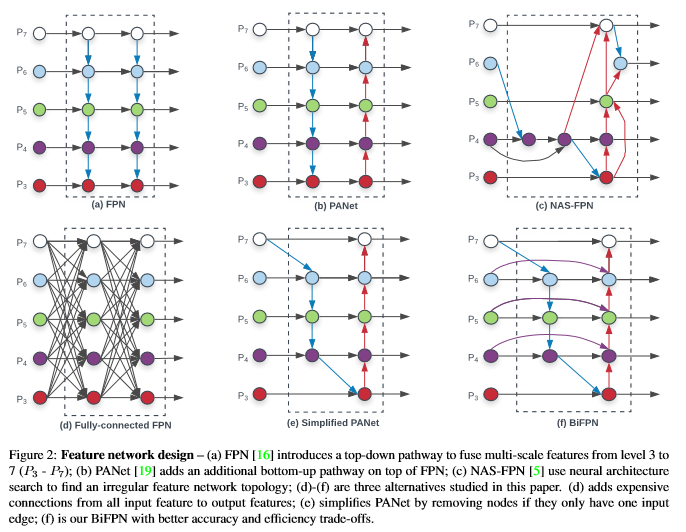
BiFPN에 대한 주요 아이디어 2개 : efficient bidirectional cross-scale connections, weighted feature fusion
Problem Formulation
multi scale feature fusion은 서로 다른 해상도의 feature를 모으는데 초점을 맞춘다. 공식적으로 multi scale feature의 목록을 표현하면
\[\vec{P^{in}} = \left ( P^{in}_{l_1} ,P^{in}_{l_2}, ... \right )\]- \(P^{in}_{l_i}\) : level \(l_i\)의 feature를 나타낸다.
이 논문의 목표는 서로 다른 feature를 효과적으로 모으고, 모아진 feature를 새롭게 변환할 \(f\)를 찾는 것이다.
\[\vec{P^{in}} = f \left ( \vec{P^{in}} \right )\]위의 공식을 FPN(a)으로 예를 들면 input feature는 \(\vec{P^{in}} = \left ( P^{in}_{3} ,...P^{in}_{7} \right )\)이고 \(P^{in}_i\)는 \(\frac{1}{2^i}\)의 해상도를 갖는다.
즉, \(P^{in}_3\)은 level이 3이므로 \(\frac{640}{2^3} = 80\)의 해상도를 갖고 level이 7이면 \(\frac{640}{2^7} = 5\)를 갖는다.
FPN을 표현하면
\[P^{out}_7 = Conv(P^{in}_7)\] \[P^{out}_6 = Conv(P^{in}_6 + Resize(P^{out}_7))\] \[...\] \[P^{out}_3 = Conv(P^{in}_3 + Resize(P^{out}_4))\]- \(Resize\) : upsampling, downsampling
Cross-Scale Connections
기존의 하향식 FPN은 단방향이다. 단방향에 부족한 정보의 흐름을 보완하기 위해 상향식 경로를 추가한 네트워크가 PANet(b)이다. cross scale connections는 계속 연구되어지고 있다. 이 논문에서는 모델의 효율성을 높이기 위해서 cross scale connections 최적화를 제안한다.
- 입력 edge가 하나밖에 없는 노드를 제거한다. 입력이 두개 이상이어야한다. simplified PANet(e)과 비슷해진다.
- 비용을 줄이고 더 많은 feature를 통합하기 위해서 동일한 level에 있는 경우 원래 입력에서 출력노드로 edge를 추가한다.
- 하나의 하향식 경로와 하나의 상향식 경로만 있는 PANet과 달리 각 양방향 경로를 하나의 feature layer로 취급하고 동일한 layer를 여러번 반복한다. 아래의 그림을 보면 이해가 갈 것이다.
Weighted Feature Fusion
해상도가 다른 input feature를 합할때 가장 일반적인 방법은 해상도를 맞추고 합치는 것이다. 해상도를 높일때 pixel localization을 복구시키기 위해 pyramid network는 global self attention upsampling이라는 것을 도입했다.
그러나 이 논문에서는 서로 다른 input feature가 다른 해상도 이기 때문에 output feature에 불균형을 야기한다. 이 문제를 해결하기 위해서 각 input에 대해 weight를 추가해서 각 input feature의 importance 배울수 있도록 network를 제안한다. 3가지 접근법을 고려한다.
Unbounded fusion
\[O = \sum_i w_i \cdot I_i\]- \(w_i\) : 학습할 수 있는 weight(scalar, vector, tensor)
softmax-based fusion
\[O = \sum_i \frac{e^{w_i}}{\sum_j e^{w_j}} \cdot I_i\]모든 가중치 0~1 범위의 확률값으로 정규화 시키는 방법
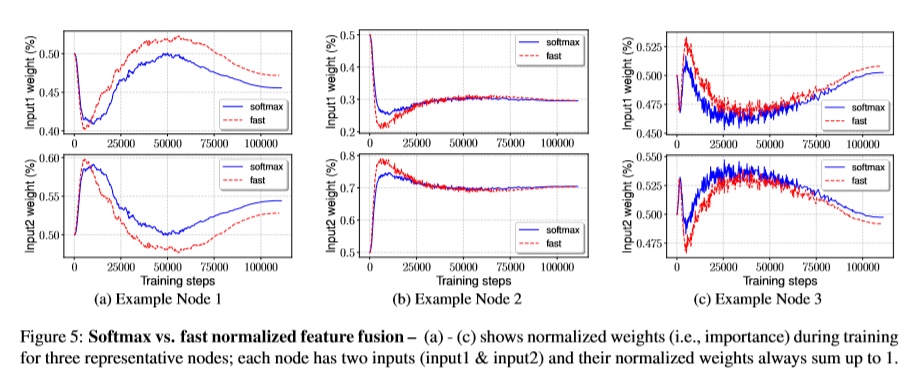
softmax를 하면 GPU 하드웨어의 속도를 저하시킨다고 한다. 그래서 추가 대기 시간을 최소화하기 위해 fast fusion 접근법을 추가로 제안한다.
Fast normalized fusion
\[O = \sum_i \frac{w_i}{\epsilon + \sum_j w_j} \cdot I_i\]- relu를 적용하여 \(w_i \geq 0\)이 보장된다.
- \(\epsilon = 0.0001\)은 수치적 불안정성을 피하기 위한 작은 값(분모가 0인 것을 방지)
위의 식도 0 ~ 1사이로 정규화 되지만 softmax가 없으므로 효율적이다. softmax와 유사한 학습과 정확도를 가지며 GPU에서 최대 30% 빠르다고 한다.
구체적으로 BiFPN에서 예를들면
\[P^{td}_6 = \frac{Conv(w_1 \cdot P^{in}_6 + w_2 \cdot Resize(P^{in}_7))}{w_1 + w_2 + \epsilon}\] \[P^{out}_6 = \frac{Conv(w_1' \cdot P^{in}_6 + w_2' \cdot P^{td}_6 + w_3' \cdot Resize(P^{out}_5))}{w_1' + w_2' + w_3' + \epsilon}\]효율성을 더욱 더 높이기 위해서 depthwise seperable convolution을 사용하고 각 convolution 후에 batch normalization과 activation function을 추가한다.
EfficientDet
EfficientDet의 Network 구조와 Compound Scaling 알아보자
EfficientDet Archtecture
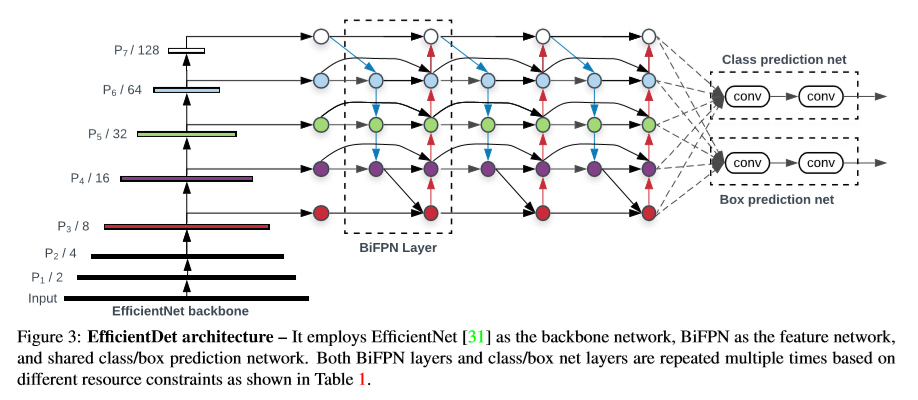
- one stage detector의 방식을 따른다.
- EfficientNet을 backbone으로 사용한다.
- class와 box prediction network를 공유한다.
Compound Scaling
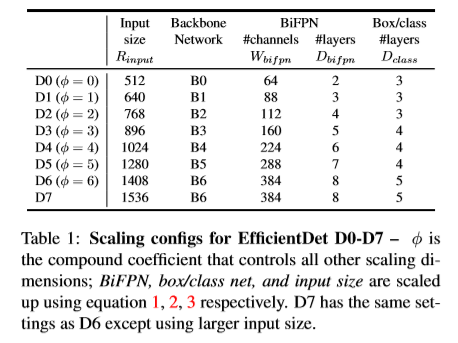
obeject detection을 위한 새로운 Compound Scaling 방법을 제안한다.
\(\phi\)를 사용해서 backbone network, BiFPN network, class/box network, resolution을 확장시킨다.
EfficientNet과 달리 object detector는 단순 image classification보다 훨씬 많은 scaling dimension을 가지기 때문에 grid search 방법은 시간이 너무 오래걸려서 하기 어렵고 직접 설정을 해주는 방식을 사용했다.
Backbone Network
ImageNet에서 pretrain model을 사용하기 위해 EfficientNet에서는 논문과 동일한 width, depth, resolution scaling 계수를 사용한다.
BiFPN Network
확장시키는 방법은 \(W_{bifpn}\)를 무한정으로 늘릴 수 있지만, \(D_{bifpn}\)는 작은 정수로 반올림해야 하기 때문에 선형으로 증가 시킨다.
\[W_{bifpn} = 64 \cdot (1.35^{\phi})\] \[D_{bifpn} = 2 + \phi\]- \(W_{bifpn}\) : width(channels)
- \(D_{bifpn}\) : depth(layers)
Box/Class Network
width는 BiFPN과 동일하게(\(W_{pred} = W_{bifpn}\)) 맞추어 주어야 하지만 depth는 선형적으로 증가 시킨다.
\[D_{box} = D_{class} = 3 + \left \lfloor \phi/3 \right \rfloor\]Input image resolution
\[R_{input} = 512 + \phi \cdot 128\]Benchmark
COCO
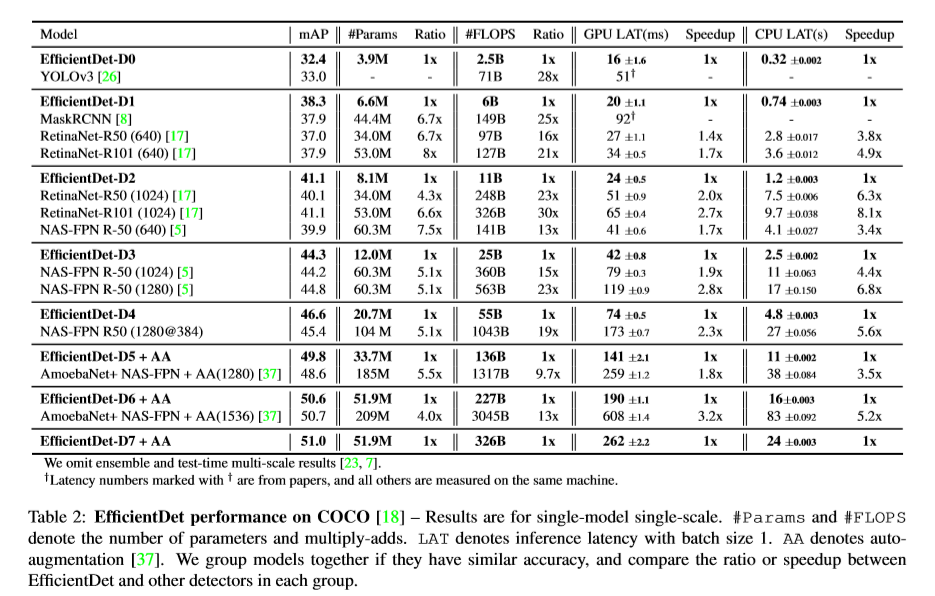
- COCO dataset에서 benchmark
- EfficientDet은 model parallelism 없이 3x3 anchor를 사용하였다.
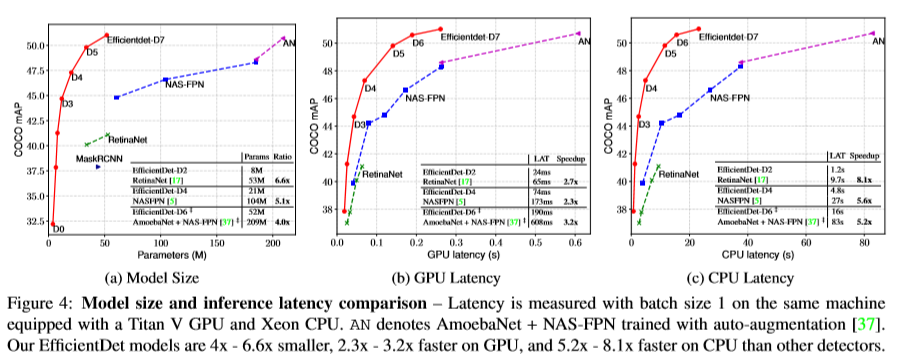
latency comparison
Softmax vs fast normalized feature fusion
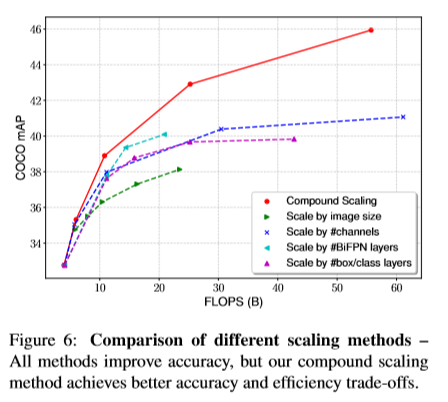
Compound Scaling