SSD 톺아보기
SSD
(Single Shot MultiBox Detector)
Abstract
bounding box의 output 공간을 나누고 각 feature map에서 서로 다른 종횡비로 default box를 생성하고 예측시에 default box에 score를 구해서 box를 조절한다.
- subsequent pixel과 resampling 제거 : 단순함
- single stage detector
Introduction
VOC2007
300x300: 77.2% mAP512x512: 79.8% mAP
resampling을 하지 않기 때문에 YOLO와 Faster-RCNN보다 속도와 성능이 좋다. 작은 convolution filter를 사용해 bounding box의 위치에서 object categories와 offsets을 예측하고 다양한 종횡비를 detection하기 위해서 별도의 filters를 사용했고 다양한 scale에 detection을 하기 위해 다양한 feature map에 적용하기도 하였다.
YOLO의 경우 63.4 % mAP에서 SSD의 경우 74.3 % mAP로 향상된다.
The Single Shot Detector
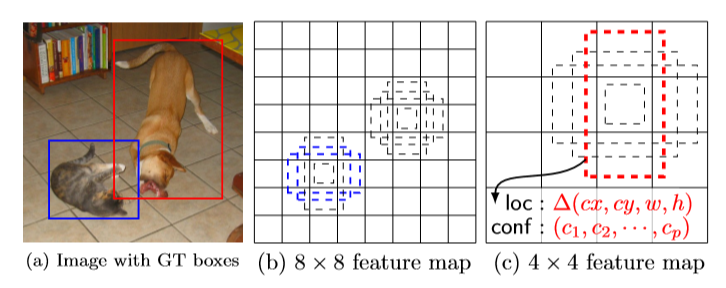
여러가지 feature map에서 학습하고 default box와 ground truth box를 일치 시키고 일치된 box를 양성 나머지를 음성으로 정의한다.
- loss : localization loss + confidence loss
Model
고정된 크기의 bounding box들과 해당 box에 object class의 점수를 예측하는 feed-forward convolutional network를 기반으로 한다.

1
2
3
4
5
6
7
8
9
10
11
38x38x512
19x19x1024
10x10x512
5x5x256
3x3x256
1x1x256
모두가 output에 연결된 feature map이다.
Multi-scale feature maps for detection
VGG-16를 부분만 사용하고 그 뒤에 feature를 추출하는 feature map을 추가한다. grid의 크기는 점차 감소하고 다양한 scale에서 object를 예측할 수 있다.
38x38, 19x19, 10x10, 5x5, 3x3, 1x1
Convolutional predictors for detection
각 feature를 추출하는 layer마다 3x3xp filter size를 가지는 convolution layer를 연결시켜서 bounding box의 offset과 class,confidence를 예측한다.
filter size = 3 x 3 x (default box num x (classes + offset))
Default boxes and aspect ratios
default box와 feature map을 각 grid cell과 연관시킨다. 각각의 feature map에서는 cell의 default box로 오프셋을 예측하고 이로 인해서 총 (c + 4) * k 개의 필터가 생기고 m x n feature map에 대해서 (c + 4) * kmn 의 output이 생긴다.
Training
- 각 feature map의 output
1
gridx x gridy x (default box num x ((class + isbackground) + offset(x,y,w,h)))
- bounding box의 개수 ``` default box의 개수 : 4 6 6 6 4 4
38 x 38 x 4 = 5776
19 x 19 x 6 = 2166
10 x 10 x 6 = 600
5 x 5 x 6 = 150
3 x 3 x 4 = 36
1 x 1 x 4 = 4
총합 : 8732 ```
Matching strategy
어떤 default box가 ground truth에 해당하는지 jaccard overlap을 이용해서 결정하고 training 시킨다. 그리고 threshold가 0.5 보다 높은 값만을 이용한다.

Total Loss = confidence loss + localization loss
- confidence : class
- localization : bounding box offset
- N : matched default boxes
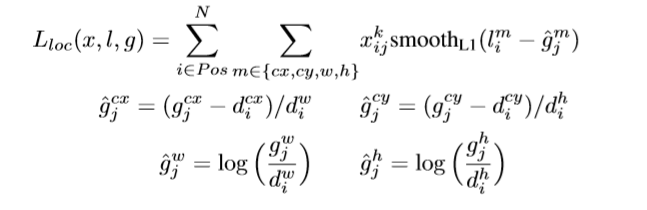
localization:smooth L1 loss
smooth L1 loss는 L1과 동일하지만 error가 작을 경우 거의 맞는 것으로 판단해서 loss값이 빠르게 줄어든다.
l:predicted boxd:default boxg:ground truth boxcx,cy:center
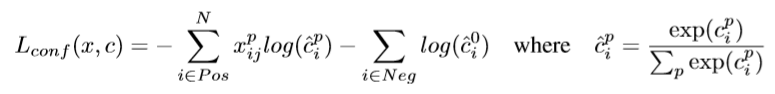
c:class confidence:softmax loss- ` weight term α` : 1
Choosing scales and aspect ratios for default boxes
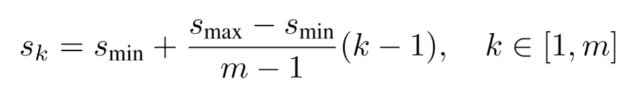
m:num of feature mapSmin: 0.2Smax: 0.9aspect ratios:1 , 2 , 3 , 1/2 , 1/3
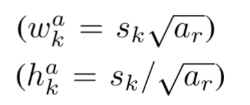
default box의 중심을 위와 같이 설정했다.
fk:k-th square feature map의 크기
Hard negative mining
대부분의 default box는 negative이기 때문에 모든 negative를 사용하는 대신 각 default box를 confidence를 기준으로 정렬하고 negative와 positive 사이의 비율이 최대 3:1이 되도록 한다.
Data augmentation
- 전체이미지 사용
- 최소 jaccard overlap이 0.1 0.3 0.5 0.7 0.9가 되도록 patch를 sampling
- 랜덤 sampling
resize,horizontally flip with probability of 0.5,photo-metric distortions
Benchmark
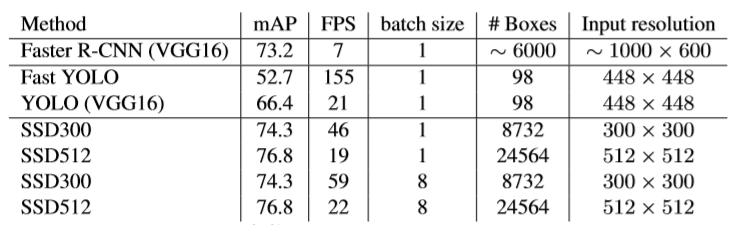

Conclusions
이 모델의 주요 특징은 network 상단의 여러 feature map에 연결된 multi scale convolution bounding box를 사용하는 것이다. 그리고 기존 방법(YOLOv1, Faster RCNN)보다 box의 localization, scale을 많이 고려하였다. SSD300 모델은 59FPS에서 실행된다. 기존 방법(YOLOv1, Faster RCNN)보다 빠르고 정확하다.