2021 Efficient Deep Learning 톺아보기
2021 Efficient Deep Learning
- Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
모델 압축 몰아보기 위해 Google Researcher에서 나온 Efficient Deep Learning paper 를 읽어봅시다. (44 pages… ^^;;)
- 중요한 문장 체크(요약)
- 고찰 등등
실제 우리가 서비스 모델을 만들기 위한 다양한 고찰이 담겨있는 paper입니다.
처음에는 그냥 모델압축 연구 관련 논문인 줄 알았지만 읽어보니 실제 현업과 더 관련있는 논문입니다.
Abstract
- modeling
- spanning
- techniques
- infrastructure
- hardware
위에 5가지 핵심 영역으로 survey를 진행합니다.
Introduction
Deep Learning with neural networks has been the dominant methodology of training new machine learning models for the past decades.
신경망을 사용한 딥러닝은 지난 10년간 새로운 머신러닝 모델을 훈련하는 지배적인 방법론이었습니다.
모델은 SOTA에만 집중하기에 모델의 complexity, number of parameters는 꾸준히 증가하면서 GPT-3의 경우 175 billion(1750억) 파라미터를 가지고 한번 반복하는데 수백만 달러가 소비된다고 합니다.
실제 모델을 잘 학습시켰다고 해도 real world에서는 동작이 잘 안될수도 있기 때문에 훈련이나 배포시 아래와 같은 문제에 직면합니다.
Sustainable Server-Side Scaling: 훈련 비용은 일회성일 수 있는데 결국 장기간 추론할 때는 많은 비용이 들 수 있다. 대기업(구글, 페이스북, 아마존 등)은 연간 수십억 달러를 소비한다고 합니다..
Enabling On-Device Deployment: IOT에서 real time으로 동작시켜야 하는 경우 target device에 최적화 된 모델을 개발해야함
Privacy & Data Sensitivity: 학습 비용을 줄이기위해 학습 데이터를 작게하면 실제 데이터에서 성능이 좋지 않다.
New Applications: 특정 새로운 어플리케이션에서 새로운 제약조건을 가지면 off-the-shelf 모델을 지원하지 않는다. off-the-shelf는 기성품이라는 의미인데 미리 학습된 모델이라고 생각하면 좋을 것 같다.
Explosion of Models: 모델 하나는 잘돌지만 여러개 돌때는 자원문제로 힘들다.
실제 서비스 측면에서 생각하는 논문이라는 것을 알 수 있다. 매우 좋은 듯 ㅎㅎ
Efficient Deep Learning
Efficiency!!
- Inference Efficiency:
- 모델이 작은가요?
- 모델이 빠른가요?
- 추론의 중점은 얼마나 많은 파라미터를 가지는지가 중요합니다.
- Training Efficiency:
- GPU는 몇개 인가요?
- 모델이 메모리에 들어가나요?
- 학습의 중점은 얼마나 많은 데이터를 사용해야하는지가 중요합니다.
위에 두개를 충족하려면 가장 좋은 방법은 디자인을 처음부터 제대로 하는게 아닐까?
pareto-optimality를 달성하자
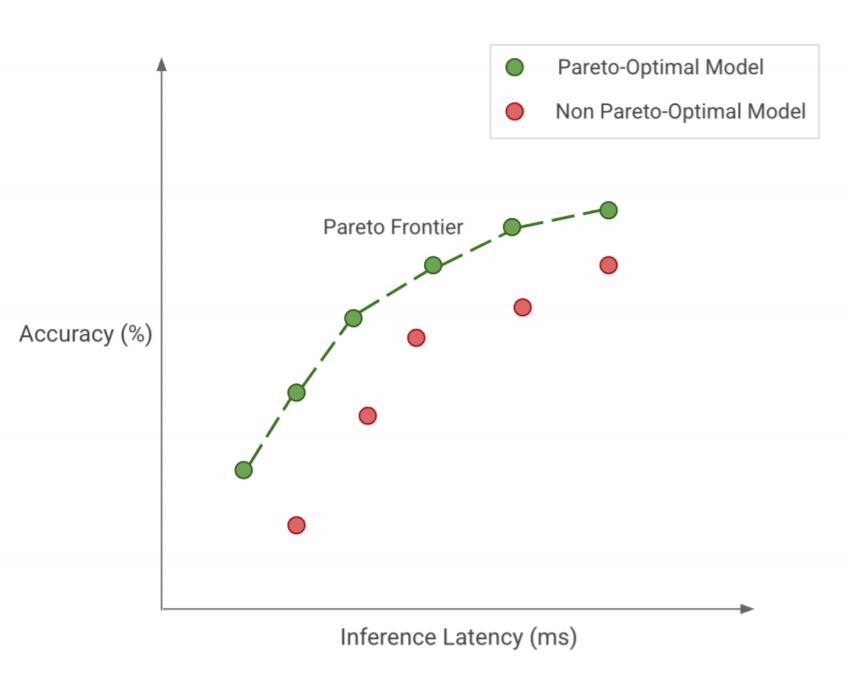
모든 것을 잘 아우르는 최적의 모델을 찾자!
A Mental Model
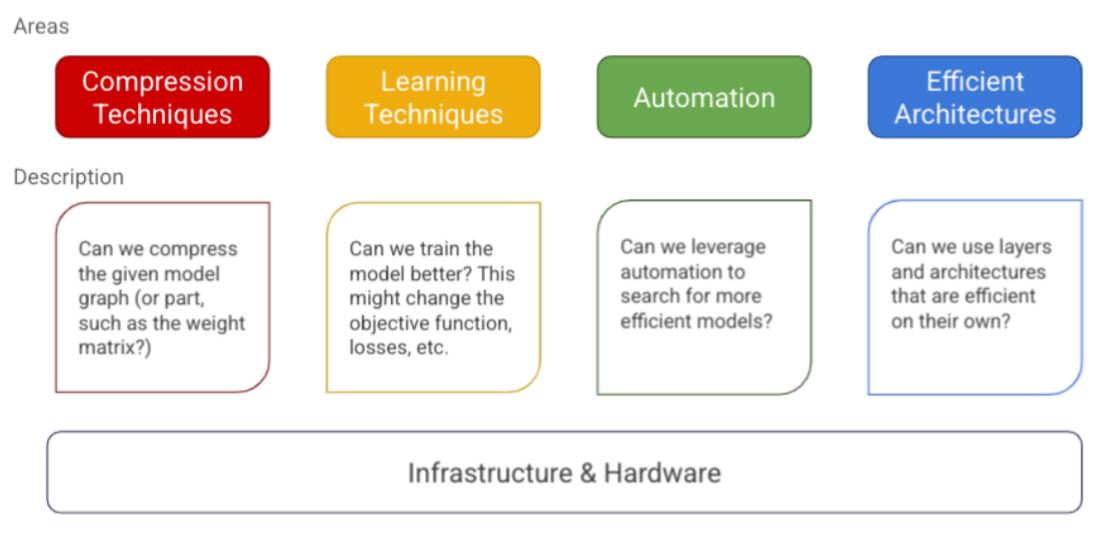
Compression Techniques: 일반적으로 layer를 압축하는 알고리즘, 예를 들어 양자화(부동소수점 32bit -> 정수 8bit)가 있다.
Learning Techniques: 모델을 학습하는 기술(적은 데이터, 적은 에러, 빠른 수렴), 예를 들어 distillation이 있다.
Automation: 최적의 하이퍼 파라미터, 모델 구조 선택을 자동화
Efficient Architectures: 효과적인 구조를 처음부터 디자인하기, 예를 들어 attention layer, convolution layer가 있다.
Infrastructure: 효과적인 프레임 워크, 예를 들어 Pytorch, Tensorflow가 있다.
Compression Techniques
만약 model이 over-parameter를 가지면 일반화에도 도움이 된다.
Pruning
프루닝은 가지치키를 뜻하며 특정 threshold 보다 작은 weights를 제거하거나 0으로 만들어 파라미터를 줄일 수 있는 기술입니다.

Optimal Brain Demage(OBD), Optimal Brain Surgeon(OBS) 이라는 두개의 논문이 있는데 프루닝 분야의 고전적인 연구입니다. 이런 방법들은 보통 가장 작은 saliency score를 가지는 weights를 제거하고 반복적으로 파인튜닝합니다.
saliency score란 보통 각 노드가 loss에 미치는 영향이나 weight 값 자체가 될 수 있습니다.
OBD는 2차 미분(\(\frac{\partial^2 L}{\partial w^2_i}\))을 사용하여 saliency score를 근사합니다. 직관적으로 이 값이 높을수록 제거가 되었을 때 영향이 크다는 것을 의미합니다.
2차 미분값을 계산하기 위한 속도를 높이기 위해서 Hessian 행렬의 대각선 요소만 계산합니다.(cross-interaction을 무시하기 때문)
정확도 저하 없이 8배 가량을 줄였다고 합니다.
Saliency: 2차 미분을 사용하지만, magnitude based pruning, momentum based pruning에 의존하여 saliency score를 결정합니다.
Structured v/s Unstructured: 가장 유연한 작업은 unstructured pruning이며 모든 파라미터가 동일하게 처리 됩니다. structured pruning은 weight matrix, channel, filter 단위로 처리하기 때문에 추론 시간에서 이득을 보기 쉽습니다. unstructured pruning은 각 노드 단위로 처리하기 추론 시간에서 이득을 보기 어렵습니다.
Distribution: 어느 layer에 얼만큼 파라미터를 제거할지 결정하는 방법입니다. MobileNetV2, EfficientNet의 경우 작은 파라미터를 가지는 첫번째 layer를 가지고 있으며 이를 pruning하는 작업은 많은 이득 없이 정확도가 떨어집니다.
Scheduling: 얼만큼, 언제 pruning을 해야하는지 결정하는 방법입니다. 매 라운드마다 동일한 수를 제거해야하는지 아니면 먼저 많이 제거하고 점점 제거하는 수를 줄여야 합니다.
Regrowth: 일부 방법은 prune-redistribute-regrow의 일정한 주기를 통해 동일한 수준의 희소성을 유지하며 prunning 된 connection을 regrowing 합니다.

Beyond Model Optimization
근래 Lottery Ticket Hypothesis는 다른 관점의 pruning이며 큰 네트워크안에는 작은 네트워크가 존재한다는 가설을 설정했습니다.
이건 미리 모델을 학습시키고 프루닝한 다음 미리 학습시킨 모델의 초기화 값을 그대로 옮겨서 재학습 시키는 방법입니다. 여러 데이터셋에서 결과를 보여주었지만 실제 ImageNet 같은 큰 데이터셋에서는 잘 동작하지 않는다고 하며 오히려 무작위 초기화가 더 좋다는 것을 보여주는 논문도 있습니다.
Discussion
실제 unstructured pruning의 경우 이론적으로는 감소한다고 보여주지만(0으로 처리해서 사실상 연산에는 포함 됨) 어떻게 개선해야할지 명확하지 않습니다.
structured pruning은 실제 0으로 처리하지 않고 제거가능하기에 도움이 됩니다.
Quantization
대부분 파라미터는 32bit 부동소수점 입니다. Quantization은 lower-precision datatype으로(즉, 32bit -> 8bit) quantizing하여 모델을 최적화 하는 방법입니다. 이로 인해 lower model size와 lower inference latency를 얻을 수 있습니다. 그런 다음 아래 그림처럼 그 사이의 모든 값을 정수 값으로 linearly extrapolate 할 수 있습니다.
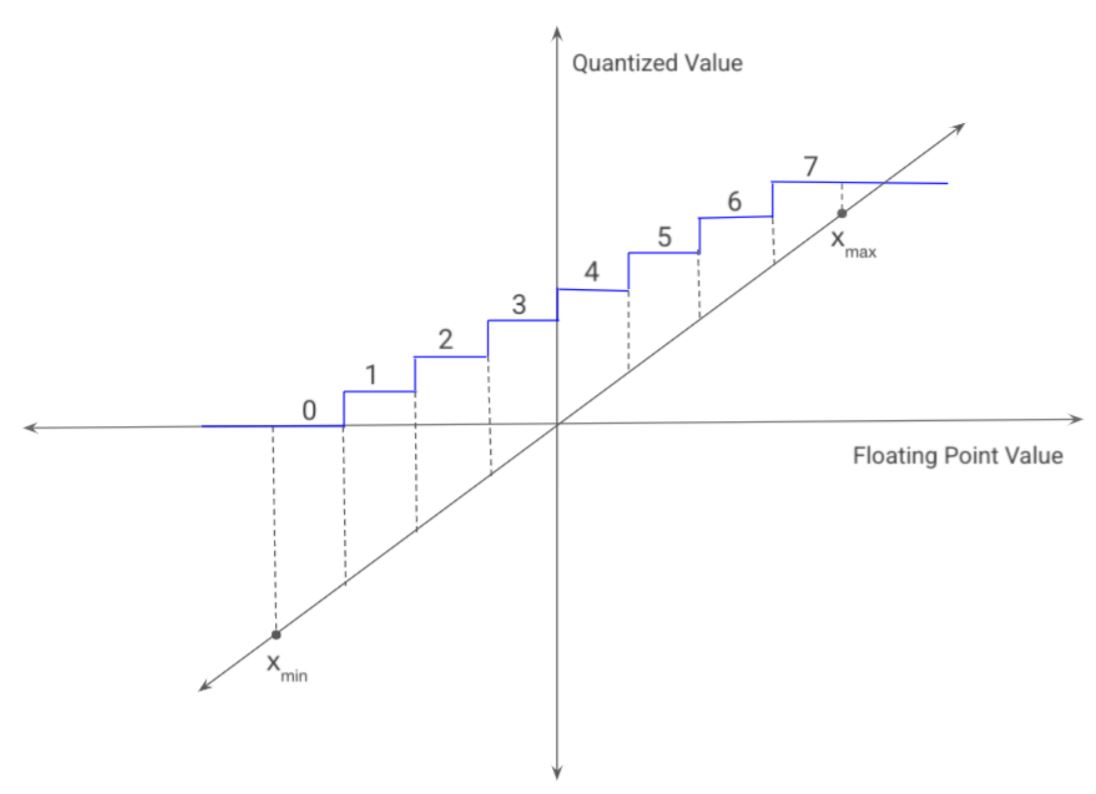
Weight Quantization
모델의 32bit 부동소수점 weights matrix가 주어지면 최소 가중치를 0, 최대 가중치를 \(2^b - 1\)로 매핑합니다. 합리적인 b의 값은 8입니다.(32 -> 8로 4배가 줄어들고 uint8_t, int8_t를 지원하기 때문)
양자화는 2가지 제약조건이 있는데
quantization의 방식은 선형(affine transformation)이어야 하므로 precision bits가 선형으로 분포됩니다.
0.0을 고정 소수점 \(x_{q0}\)에 정확히 매핑되어야 합니다. 0은 텐서에서 누락된 값을 표현하기 위해서 사용되는 경우가 있기에(패딩) \(x_{q0}\)를 역양자화하면 0이 아닌 값으로 매핑될 수 있습니다.
\(s\)는 \(x_{min}, x_{max}\)와 고정 소수점 값을 사용하여 계산되는 scale value 입니다.(32bit 부동 소수점에서 0 ~ 255 로 스케일링할 변수로 변화하기 위한 값)
\(z\)는 \(x = 0.0\)에 할당되어 있는 영점 값입니다.
\[dequantize(x_q) = \hat{x} = s(x_q - z)\]역영자화는 \(\hat{x}\)로 표기하는데 이는 \(x\)의 손실이 있는 추정치이기 때문입니다.

위에 그림으로 양자화 및 역양자화가 표현됩니다. 사전 훈련 된 모델의 가중치를 양자화 하는 것을 post-training quantization이라고 합니다.
Activation Quantization
latency를 개선하려면 고정 소수점 표현에서 수학 연산을 해야합니다. 이는 모든 중간 layers의 입력과 출력은 고정 소수점이라는 것과 역양자화를 하지 안하도 된다는 것을 의미합니다.
Quantization-Aware Training(QAT)
논문에서 훈련 후에 양자화 된 5계층 feed-forward network를 언급합니다.
하지만 아래 몇몇 연구에서 강조하는 것처럼 네트워크가 더 복잡해짐에 따라 훈련 후 양자화는 추론 성능을 좋지 않게 한다는 것을 보여줍니다. 이는 2가지 이유가 있는데..
outlier weights!! 매우 큰 이상 값이 나오면 대부분 이상값으로 치우치는 문제
weight matrix 내부에 다른 분포!! 예를 들어 컨볼루션 레이어 내에서 각 필터의 가중치 분포는 다를 수 있지만 동일하게 양자화 하는 문제
이러한 문제는 low-bit widths 에서 더 두드러질 수 있습니다.
Towards Accurate Post-training Network Quantization via Bit-Split and Stitching : 훈련 후 양자화를 유지하려 하지만 학습된 방식으로 precision bits를 할당하기 위한 새로운 방법을 사용
TFLite Converter : 양자화된 모델과 양자화되지 않은 모델 사이의 activations 간의 오류를 비교하여 능동적으로 수정
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference : Quantization-Aware Training을 제안합니다. 훈련은 floating point로 하지만 forwardpass에서 추론할때 사용 될 양자화 동작을 시뮬레이션합니다 (즉, 양자화 하는 방법을 모방하여 학습). weights와 activations를 양자화 동작을 시뮬레이션하는 함수에 넣습니다. (fake-quantized) X가 fake-quantized tensor라고 가정하면 특별한 양자화 노드를 추가하여 학습 중에 양자화할 weights와 activations에 관련된 통계값(\(X_{min}, X_{max}\)의 moving average)를 계산하고 추론시에 양자화 합니다.
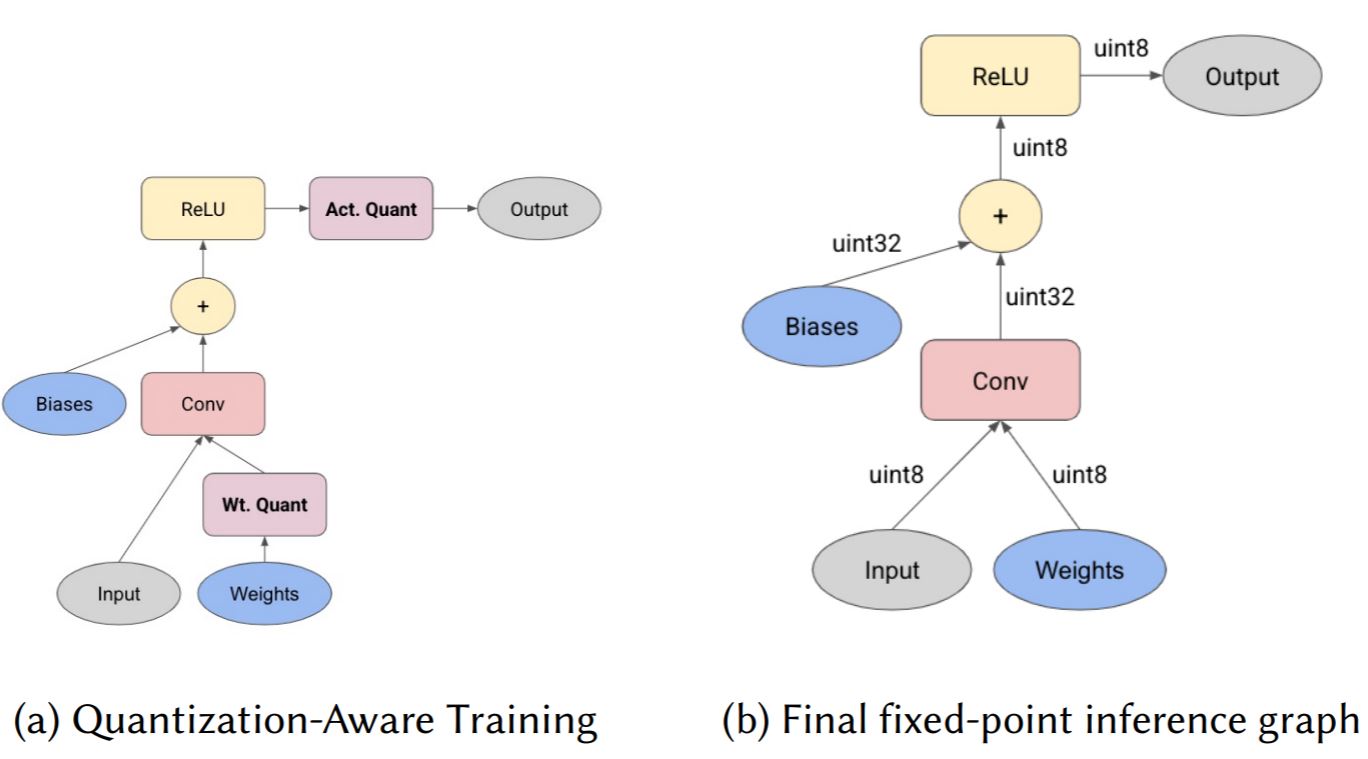
Other Notable Works
Model compression via distillation and quantization : 양자화 포인트 \(p\)를 학습하고 손실을 줄이기 위해 knowledge Distillation을 사용합니다.
etc..
Result
훈련 후 양자화가 적용되는 모델은 정확도 차이가 상당합니다. 모델의 크기는 4배 작아지지만 추론하는 동안 가중치를 역양자화해야 하기 때문에 latency가 높습니다.
8-bit QAT는 정확도는 기존 모델과 매우 근접하여 디스크 공간이 4배 적게 필요하고 1.64배 빠릅니다!
Discussion
Quantization은 잘 연구된 기술로 model size를 많이 줄일 수 있습니다.
Wegith Quantization은 구현이 간단하며 Activation Quantization은 중간 계산에 필요한 메모리 뿐만 아니라 latency 또한 감소하게 하므로 강력하게 고려해야합니다.
가능한 Quantization-Aware Training을 사용해야합니다. 정확도의 측면에서도 가장 좋은 성능을 가집니다.
Tensorflow Lite같은 도구를 사용하면 양자화를 쉽게 사용할 수 있습니다.
성능상의 이유로 Batch Normalization, Activation 등과 같은 일반적인 레이어를 따르는 일반적인 작업을 고려해야 합니다. ‘fold’하는게 가장 좋습니다..? (흠.. 추가 layer에서는 그냥 동작시키고 나머지 작업에서 quantization 하는 것이라 생각 됩니다.)
Other Compression Techniques
Low-Rank Matrix Factorization, K-Means Clustering, Weight-Sharing
추가 압축을 위해서 적합!
Learning Techniques
Learning Techniques는 더 나은 정확도를 얻기 위해 기존 학습 방법과 다르게 학습하는 방법 입니다. 모델의 파라미터와 레이어의 수를 줄인 작은 모델이 기존의 큰 모델과 동등한 성능을 달성하게 합니다. 학습하는 방법에 초점을 맞추기 때문에 추론에는 영향을 주지 않습니다.
Distillation
Ensemble은 일반화를 돕는데 잘 알려진 방법입니다. 이는 단일 가설 보다 다중 독립 가설이 좀 더 나은 성능을 가진다는 직관에서 시작됩니다.
Bagging : 다양한 모델을 겹치는 데이터 없이 학습하는 방법
Boosting : 다양한 모델의 손실을 고정하여 학습하는 방법
averaging : 앙상블 모델들을 voting하는 방법
몇몇은 작은 모델이 큰 앙상블의 성능을 모방할 수 있다는 것을 발견합니다. Hinton은 어떻게 더 큰 모델(teachers)이 더 작은 모델(students)에게 “dark knowledge”를 추출하도록 가르칠 수 있는지에 대한 방법을 연구했습니다.
teacher 모델이 예측한 값은 soft-labels로 argmax를 취하기 전에 확률값입니다. soft-labels은 서로 다른 클래스 간의 관계를 포착할 수 있게 합니다. 예를 들어 트럭은 자동차와 유사하지만 사과와는 거리가 멉니다. student 모델은 teacher 모델의 soft-labels 값을 전달받아 이를 모방하도록 cross-entropy 합니다. 그리고 기존 hard-labels 값도 cross-entropy하여 둘을 결합합니다.
\[Y_{i}^{(t)} = \frac{\sum_{j=1}^n exp(Z_j^{(t)} / T)}{exp(Z_i^{(t)} / T)}\]\(T\)는 temperature로 1보다 큰 값을 가지며 분포를 부드럽게 하는 역할을 합니다.
\[L = \lambda_1 \cdot L_{ground-truth} + \lambda_2 \cdot L_{distillation}\] \[= \lambda_1 \cdot CrossEntropy(Y, Y^{(s)}; \theta) + \lambda_2 \cdot CrossEntropy(Y^{(t)}, Y^{(s)}; \theta)\]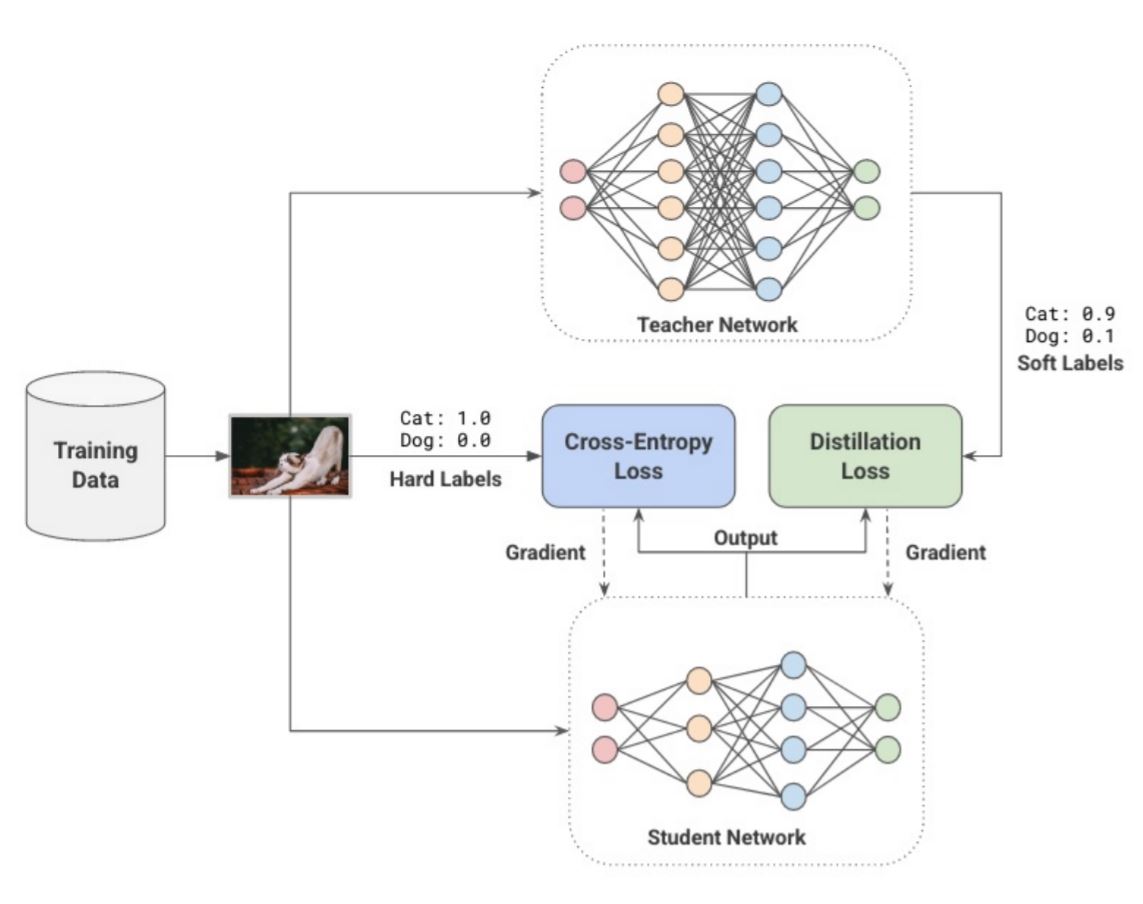
위에 식과 그림으로 Knowledge Distillation이 완성됩니다.
Distilling the knowledge in a neural network. : distillation으로 speech recognition task에서 10개 모델 앙상블 정확도와 작은 모델의 정확도를 근접하게 만들었습니다.
Do deep convolutional nets really need to be deep and convolutional? : Cifar-10에서 distillation으로 하나의 hidden layer를 가지는 MLP 모델의 성능을 향상시켰습니다.
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter : distillation을 사용해 BERT를 압축했습니다. teacher와 student 모델의 representation vector 사이의 cosine distance를 최소화하는 cosine loss를 사용하였으며, 이를 통해 97% 성능을 유지하고 40% 작아지고 CPU에서 60% 빠르다고 합니다.
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer : teacher와 student 모델 사이의 attention maps을 transfer 합니다.
Mobilebert: a compact task-agnostic bert for resource-limited devices : student와 teacher BERT사이의 layer-wise distillation을 하는 progressive-knowledge transfer 전략을 사용합니다.
Combining labeled and unlabeled data with co-training : 학습된 분류기를 사용하여 생성된 pseudo-labels의 subset을 재학습하여 classifier의 에러율을 줄입니다.
Discussion
labeled data에서 성능을 향상시키는 증거가 많다. 게다가 unlabeled data로 teacher 모델의 pseudo-labels을 생성하여 성능 향상에 많은 기여를 합니다.
복잡한 모델에도 효과적이며 일부 중간 부분에서 출력간의 차이를 최소화하는 새로운 손실 함수가 필요합니다.
Data Augmentation
labeled 데이터가 많을수록 모델의 성능은 좋아지지만 labeling 작업은 많은 노동으로 이루어집니다. 이를 완화하기 위해 data augmentation 방법을 사용하는데.. 실제 강아지 사진이 있을 때 강아지는 수직, 수평으로 뒤집거나 회전해도 강아지입니다. 대부분 모든 사람이 튜토리얼을 통해 모델을 학습할 때 기본적으로 사용되어지는 방법입니다.
아래 이미지랑 같이 보세요 ㅎㅎ 많은 것을 다루지는 않습니다. 근래 다양한 Data Augmentation 방법을 어떻게 표현하는지만 알고 넘어갑시다.
Label-Invariant Transformations : 가장 흔한 data augmentation 입니다. flipping, cropping, ratation, distortion, scaling, shearing 등등 다들 한번씩 써보신거죠 ㅎㅎ
Label-Mixing Transformations : Mixup과 같은 방법들! 이것도 정말 많이 사용되는 방법입니다. 이미지 두개를 각 weight를 곱해 더하는 방법인데 여기서 weight를 얼마나 곱한지에 따라서 라벨값이 결정됩니다.
Data-Dependent Transformations : 해당 exmaple의 손실을 최대화하도록 하는 transformation을 선택하거나 모델을 속이도록 adversarially하게 선택합니다.
Synthesis Sampling : 합성으로 새로운 examples를 만드는 방법입니다.
Composition of Transformations : 다양한 transformation을 결합하는 방법입니다.
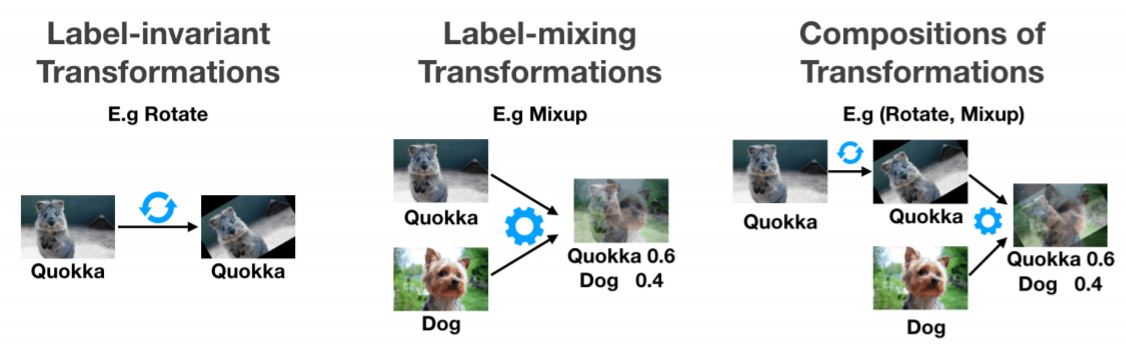
Data Augmentation은 Optimizer 논문 보듯 정말 다양한데 지금까지 나온 방법들에서 그렇게 큰 변화를 주거나 그렇지는 않습니다(제 생각에는…?). 각 방법론 main 논문에서 방법만 훑어도 무방할 것 같습니다.
Self-Supervised Learning
이 분야도 재미있는 분야인데 이번에 좀 보게되어 좋습니다.
Supervied Learning은 데이터에 크게 의존합니다. 위에 Distillation이나 Data Augmentation도 학습 데이터를 줄이는데 큰 역할을 하지만 사실 데이터가 없는 문제가 전부 해결되는 정도는 아닙니다. Self Supervised Learning(SSL)는 supervisory bits를 추출하는 것을 목표로 하며, generalized representations를 학습하기 위해서 labeled data가 필요하지 않습니다. 일반적으로 모델의 입력의 일부가 누락된 것으로 가정하고 이를 예측하는 방법을 학습하는 pretext task를 해결하며 수행됩니다. 이렇게 학습 된 모델은 보통 transfer되어 fine-tuning 하는데 사용 되며 이는 처음(init random weights)부터 학습하는 것보다 빠르게 수렴하고 좀 더 나은 성능을 얻습니다.
ULMFiT은 unlabeled data를 통해 다음 단어를 예측하는 pretext task 를 해결하기 위한 아이디어를 제안했습니다. 이를 통해 적은 labele data로 좋은 성능을 보여줍니다.
BERT은 주어진 문장에서 15%의 masked token을 예측하는 Masked Language Model이며 두 개의 문장 A, B가 주어질 때 B가 A 다음에 오는지를 예측합니다. 이를 통해 11개의 NLP task에서 SOTA를 달성하며 추후 연구들의 많은 발전에 기여했습니다.
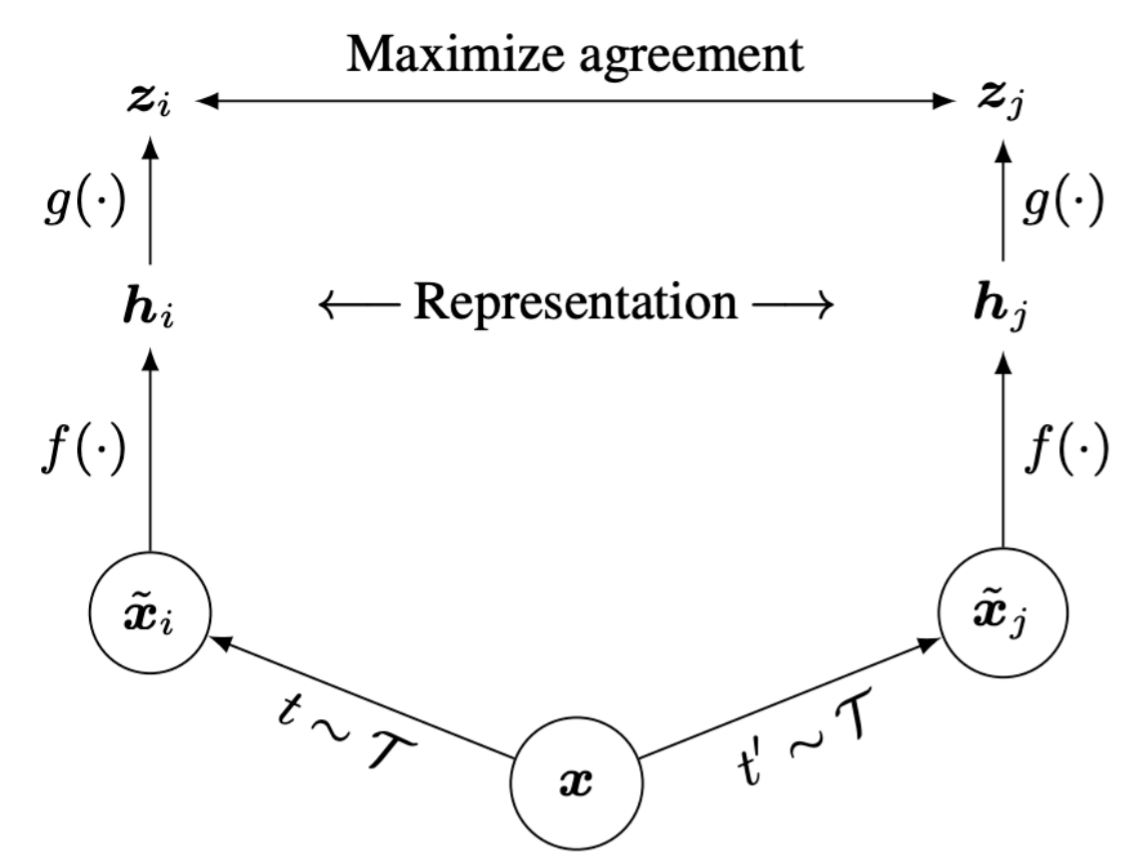
Unsupervised representation learning by predicting image rotations는 얼만큼 회전이 되었는지를 예측하는 방법입니다. 또 다른 주제는 유사한 입력과 유사하지 않은 입력을 구별하는 방법을 학습시키는 방법입니다.
SimCLR은 주어진 이미지 쌍에 대해서 유사한 입력인 경우 cosine similarity가 최대화되며 유사하지 않은 입력인 경우 cosine similarity가 최소화 되도록 학습합니다. 이를 통해 성능을 개선했습니다.
Discussion
실생활에 넘쳐나는 unlabeled data를 통해 적은 labeled data로 좋은 성능의 모델을 얻을 수 있으며 이는 ML 실무자에게 중요한 역할을 할 것이라 믿습니다.
Automation
실제 사람이 직접 해야하는 작업을 줄이기 위해 systematically 그리고 automatically하게 최적의 solutions을 찾는 방법입니다. 이는 많은 시간을 소비하기에 신중하게 선택해야합니다.
Hyper-Parameter Optimization
Automation에서 가장 흔한 방법은 Hyper-Parameter Optimization(HPO) 입니다. learning rate, weght decay와 같은 hyper parameters는 빠르게 수렴하기 위해서 신중하게 설정해야합니다. 이 값은 fully connected layer의 수, convolutional layer filter의 수와 같은 모델의 구조를 통해 결정할 수 있습니다.
수동으로 하기에는 매우 지루하고 시간이 많이 소요되는 작업이며 이를 자동으로 하는 알고리즘을 살펴보면.. 먼저 \(L\)을 손실 함수, \(f\)를 hyper parameters의 집합(\(\lambda\))로 학습한 모델, \(x\)를 입력, \(\theta\)를 모델의 매개변수라고 합시다. 최적의 \(\lambda\)를 찾아야합니다.
\[\lambda^{*} = argmin_{\lambda \in \Lambda} L(f_{\lambda}(x;\theta), y)\]\(\Lambda\)는 모든 hypter parameters의 집합입니다. 가장 흔한 전략은 유한 집합 \(S=\left \{ \lambda^{(1)}, \lambda^{(2)}, \dots, \lambda^{(n)} \right \}\)에서 선택하는 것입니다.
\[\lambda^{*} \approx argmin_{\lambda \in \left \{ \lambda^{(1)}, \lambda^{(2)}, \dots, \lambda^{(n)} \right \}} L(f_{\lambda}(x;\theta), y)\]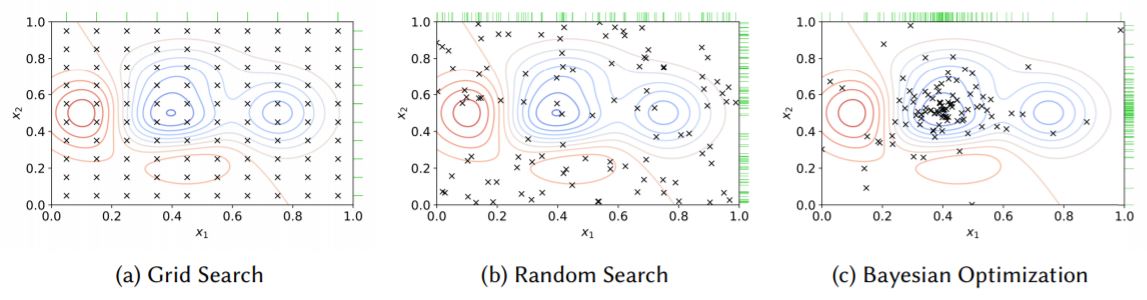
Grid Search : 모든 가능한 조합을 시도합니다.
Random Search : 무작위로 샘플링하여 시도합니다.
Bayesian Optimization(BO) : search space의 여러 지점에서 목적 함수의 값을 능동적으로 추정한 다음 수집된 정보를 바탕으로 새로운 trials를 생성합니다. 무작위가 아닌 유도된다는 점에서 최적의 성능에 도달하기 위해 필요한 trials가 더 적습니다.
Population Based Training(PBT) : 유전 알고리즘과 같은 진화적인 접근 방식입니다. 먼저 random하게 시작하고 미리 결정된 step의 수로 훈련됩니다.
Multi-Armed Bandit Algorithms : Successive Halving(SHA), Hyper-Band와 같은 방법은 random search와 유사합니다. 그러나 더 좋은 성능을 가지는 trials에 좀 더 많은 자원을 할당합니다. 사용자가 search를 위한 budget B(예를 들어, 총 에폭 수)를 설정합니다. 그리고 무작위로 hyper-parameters를 설정하고 학습합니다. B가 소진되면 낮은 성능의 trials가 제거되고 나머지 trials의 B에 \(\lambda\)가 곱해지게 됩니다. 그리고 반복합니다.
HPO Toolkits
몇몇 software toolkits이 존재합니다.
Vizier : Google
Sagemaker : Amazon
NNI, Tune, Advisor 그리고 다양한 오픈소스는 local에서 사용할 수 있습니다.
Neural Architecture Search
말 그대로 모델의 architecture를 찾는 알고리즘 입니다. NAS는

Efficient Architectures
기존 모델을 유지하는게 아니라 새롭게 모듈을 만들고 모델을 구성하는 방법
Vision
Vision 도메인에서는 Fully Connected Layer, Convolutional Layer를 효과적으로 하는 방법이 주된 목적이고 Fully Connected Layer는 2가지 주요 문제점을 가집니다.
- FC Layer는 공간 정보를 무시합니다.
- FC Layer는 중간 크기의 입력으로 작업할 때 parameter의 수가 폭발적으로 증가합니다. 이는 과적합에 취약하며 학습하기 어렵습니다.
Convolutional Layer는 filter를 학습하기 때문에 위에 같은 문제점이 없습니다. 대게 입력 feature map과 filter를 통해 그 다음 feature map을 생성합니다. 앞부분 layer는 edge를 학습하며 뒤에서는 texture와 shape을 학습합니다. (컨볼루션의 자세한 설명이 있지만 기본적인? 것이라 생략합니다.)
Depth-Separable Convolutional Layers
이것도 Efficient Modeling에서 흔한 방법론이며 아래그림으로 설명됩니다.
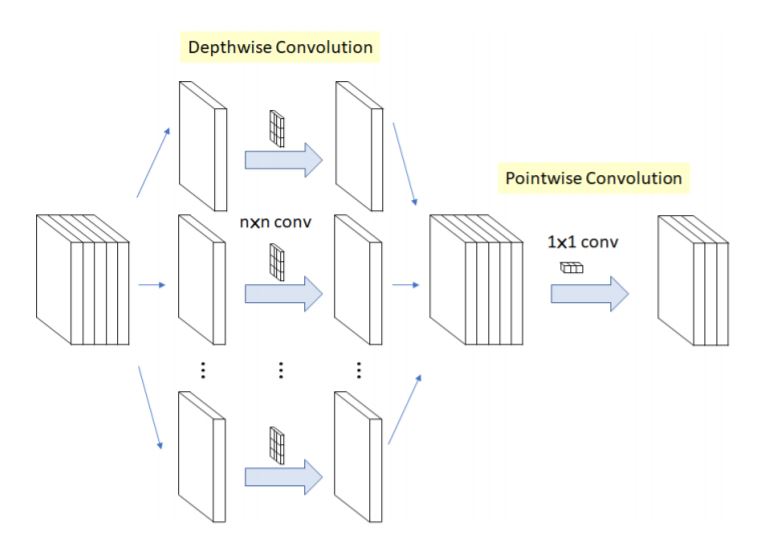
- Point-wise convolution : 1x1 convolution으로 output channels 크기를 가집니다.
- Depth-wise convolution : 3x3 convolution
이를 통해
Standard Convolutional Layer :
\[s_x × s_y × input_channels × output_channels\]Depth-wise Convolutional Layer :
\[(1 × 1 × input_channels × output_channels) + (s_x × s_y × output_channels)\]파라미터가 줄어들게 됩니다.
Infrastructure
보통 딥러닝을 학습하거나 추론할 때 framework를 사용합니다. 이번 파트에서는 하트웨어와 소프트웨어의 상호작용에 대한 survey를 합니다.
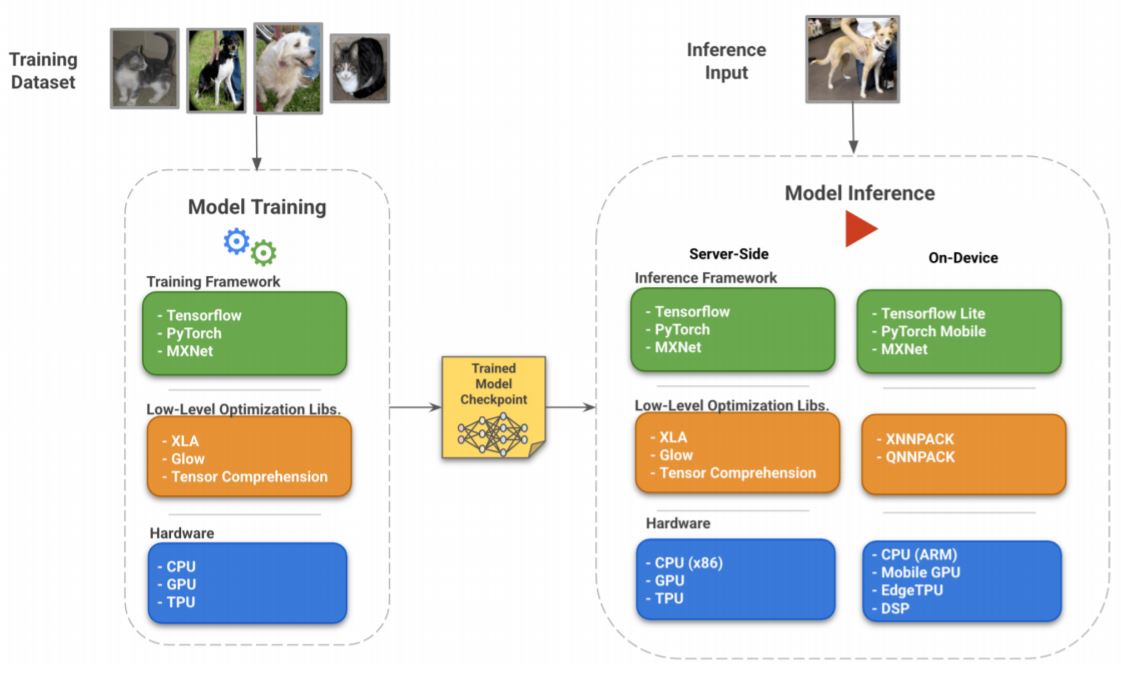
Tensorflow Ecosystem
Tensorflow는 인기있는 머신러닝 framework로 가장 확장성이 좋고 효율적인 방법들을 제공합니다.
Tensorflow Lite for On-Device Usecases
Tensorflow Lite는 적은 resource을 가지는 환경을 위해 디자인 된 라이브러리와 도구의 집합입니다.
Interpreter and Op Kernels : TFLite는 일반적인 모듈(Convolution, Pooling, ReLU etc.)의 구현과 TFLite models을 실행하기위한 interpereter를 제공합니다. 이를 Op Kernel 이라고 합니다. 이는 ARM 기반 프로세서에 최적화 되어있으며 빠른 실행을 위해 Qualcomm의 Hexagon과 같은 스마트폰 DSP(Digital Signal Process)를 활용할 수 있습니다.
Converter : TFLite Converter는 주어진 TF models를 interpreter가 추론할 수 있도록 single flatbuffter file로 변환하는 데 유용합니다. 양자화를 위한 다양한 것도 제공합니다.
Other Tools for On-Device Inference
TF Micro는 slimmed down interpreter와 매우 작은 resource microcontrollers에 대한 추론을 위해 더 작은 연산 집합으로 구성됩니다.
TF Model Optimization toolkit은 양자화, 프루닝, 군집화와 같은 기술을 처리하는 Tensorflow 라이브러리 입니다.
TensorflowJS는 Node.js와 브라우저 내에서 신경망을 학습하거나 추론하는데 사용할 수 있는 Ecosystem 라이브러리 입니다.
XLA for Server-Side Acceleration
일반적인 TF model graph는 TF’s executor process으로 실행되고 이는 CPU, GPU에서 실행하기 위해 표준 최적화 커널을 사용됩니다.
XML는 이를 수행하는 새로운 커널을 생성하고 모델에서 linear algebra 연산을 최적화 할 수 있는 graph compiler입니다.
For example, certain operations which can be fused together are combined in a single composite op.
This avoids having to do multiple costly writes to RAM, when the operands can directly be operated on while they are still in cheaper caches.
Pytorch Ecosystem
Pytorch는 인기있는 머신러닝 framework로 산업과 연구에 많이 사용됩니다.
General Model Optimization
Pytorchg에서는 Just-in-Time(JIT) compilation을 제공합니다. TorchScript(모델을 직렬화하고 최적화하기 위해 사용)에 속해있습니다.
torch.jit.script로 감싼 모델 그대로 저장하면 코드파일 없이 모델을 사용가능 합니다.buffer checkpoint를 활성화하면 특정 레이어의 출력만 메모리에 유지하고 나머지는 backward에서 계산가능합니다. 이는 특히 activation과 같은 큰 출력을 가지지만 계산량이 적은 layer에 도움이 됩니다.
Hardware
GPU
Graphics Processing Units(GPUs)는 computer graphics를 가속화하기 위해서 만들어졌습니다.
- 2007년도에 등장한 CUDA 라이브러리는 GPU를 범용 목적으로 사용할 수 있게 하였으며 cuBLAS와 같은 라이브러리는 linear algebra 연산의 속도를 빠르게 하였습니다.
- 2009년도에 GPU가 딥러닝 모델을 가속할 수 있다는 것을 입증했습니다.
- 2021년도에 AlexNet 모델의 등장으로 딥러닝에서 GPU의 사용은 표준이 되었습니다.

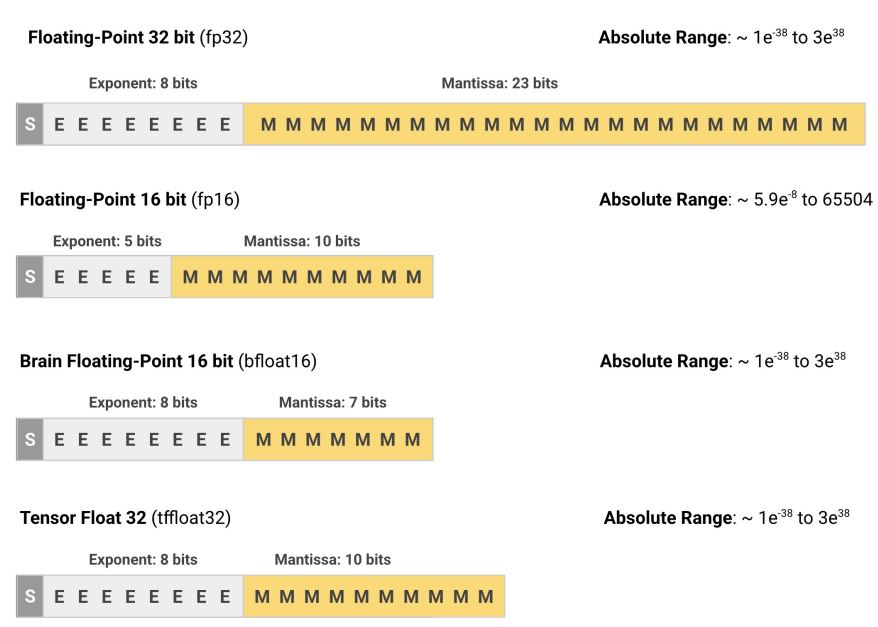
Tensor Core는 표준 MAC 연산을 최적화 합니다. 여기서 B와 C는 fp16인 반면 A와 D는 fp32입니다.
TPU
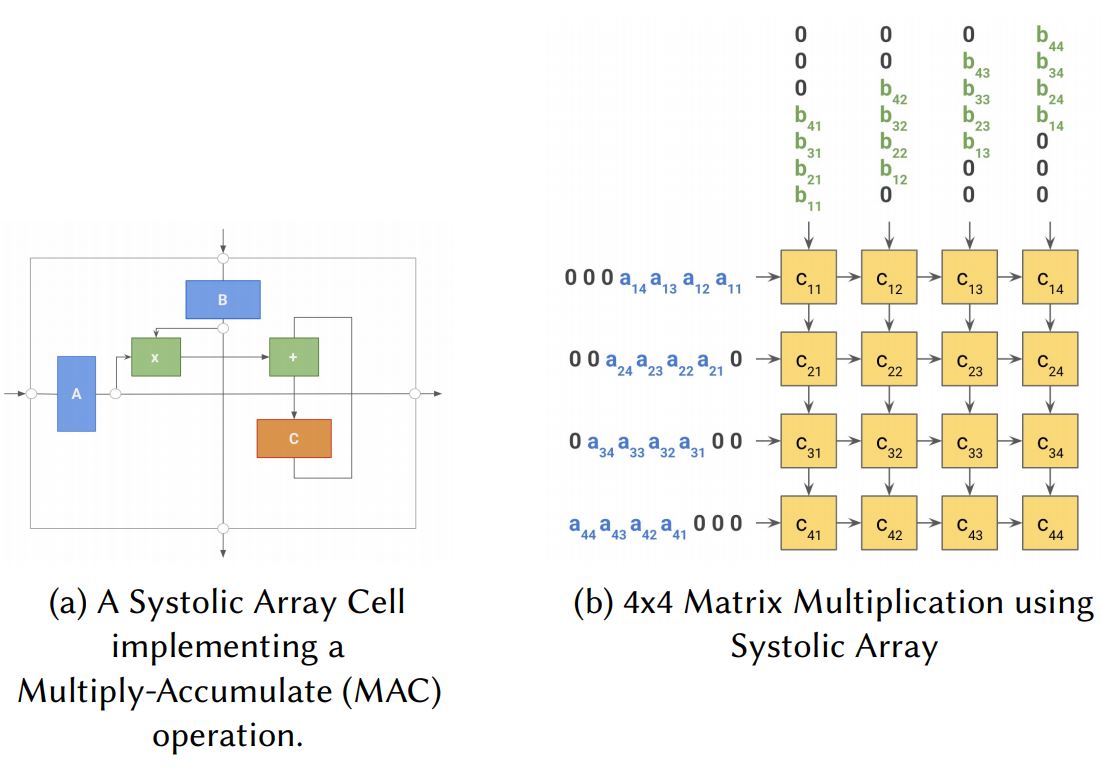
TPU는 Goopgle이 Tensorflow로 딥러닝 어플리케이션을 가속화하기 위해서 설계한 독점 ASIC(Application-Specific Integrated Circuit)입니다. 범용 목적인 장치가 아니기 때문에 ML이 아닌 다른 응용 프로그램을 고려할 필요가 없기 때문에 linear algebra 연산을 병렬화하고 가속화하도록 미세 조정됩니다. 핵심 architecture는 Systolic Array를 활용하는 것입니다.
EdgeTPU
EdgeTPU는 낮은 전력을 사용하는 Edge Device에서 추론을 하기 위한 맞춤형 ASIC입니다. TPU와 같이 linear algebra 연산을 가속화하는데 특화되어 있지만 추론에만 사용되며 더 낮은 비용을 가집니다. Tensorflow Lite 모델에서만 동작하며 Coral 플랫폼을 사용합니다.
Jetson
Jetson은 임베디드 및 IoT 장치에 딥러닝 어플리케이션을 동작시키기 위해서 사용되는 Nvidia 가속기 제품입니다. lightweight 배포를 위해서 설계된 저전력 system on a module(SoM)인 Nano 그리고 Nvidia Volta 및 Pascal GPU architecture를 기반으로 하는 Xavier 및 TX로 구성됩니다.
A PRACTITIONER’S GUIDE TO EFFICIENCY

앞서 효과적인 딥러닝을 위한 다양한 방법을 제안했는데 이번 파트에서는 실제 실무자들이 사용할 수 있는 실용적인 가이드를 제공합니다.
- Quality-related metrics : Accuracy, F1, Precision, Recall, AUC etc.
- Footprint-related metrics : Model Size, Latency, RAM etc.
위에 Quality, Footprint에는 당연하게 trade-off가 존재합니다. 정확도가 높으면 latency를 희생해야합니다.
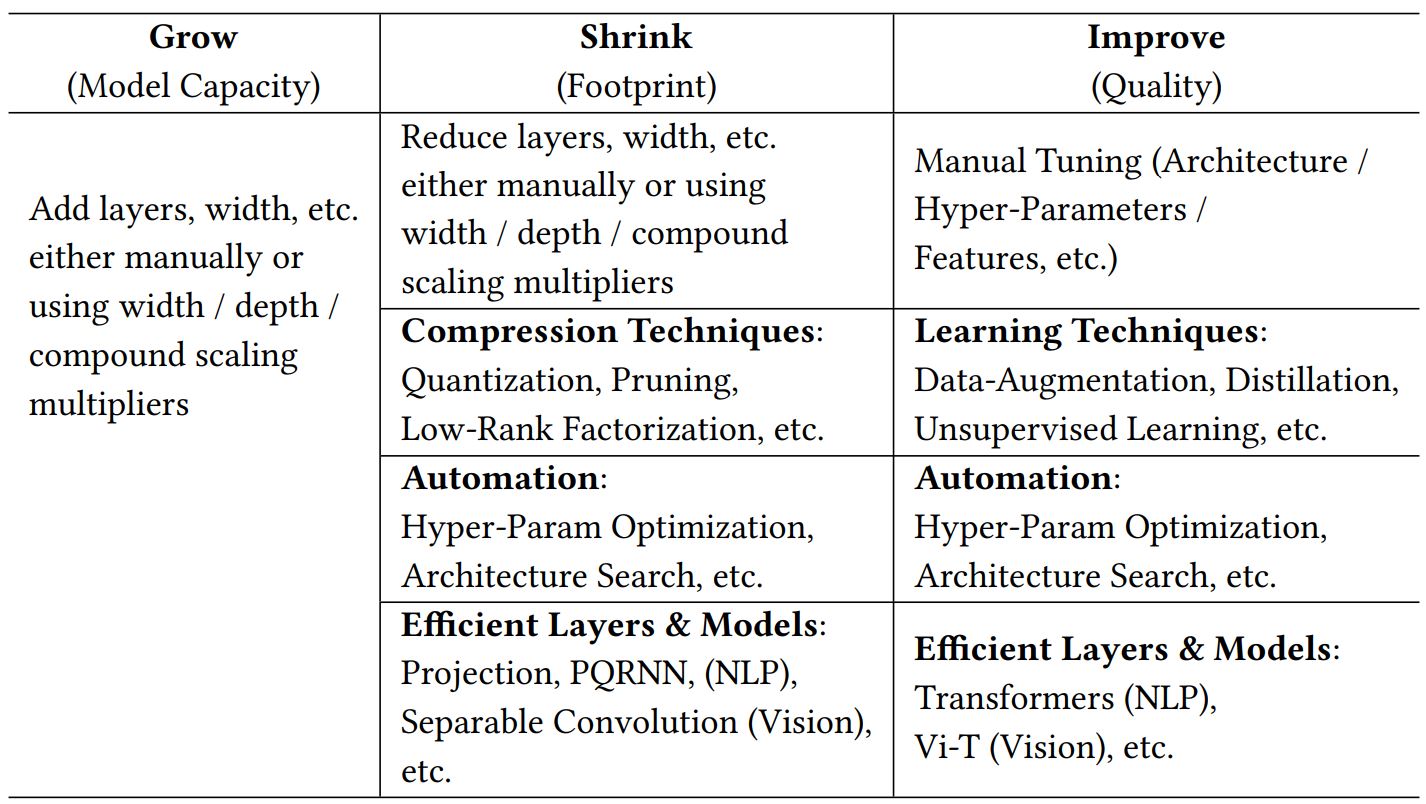
Shrink-and-Improve for Footprint-Sensitive Models : 동일한 quality를 가지면서 더 작은 footprint를 얻고자 한다면 compression techniques, architecture search를 사용해야합니다.
Grow-Improve-and-Shrink for Quality-Sensitive Models : 동일한 footprint를 가지면서 더 좋은 quality를 얻고자 한다면 learning techniques, automation을 사용해야합니다.
Experiments
efficiency techniques를 사용하여 pareto-frontier를 달성합니다.
efficiency techniques의 다양한 조합으로
Shrink-and-Improve와Grow-Improve-and-Shrink의 trade-off를 입증합니다.
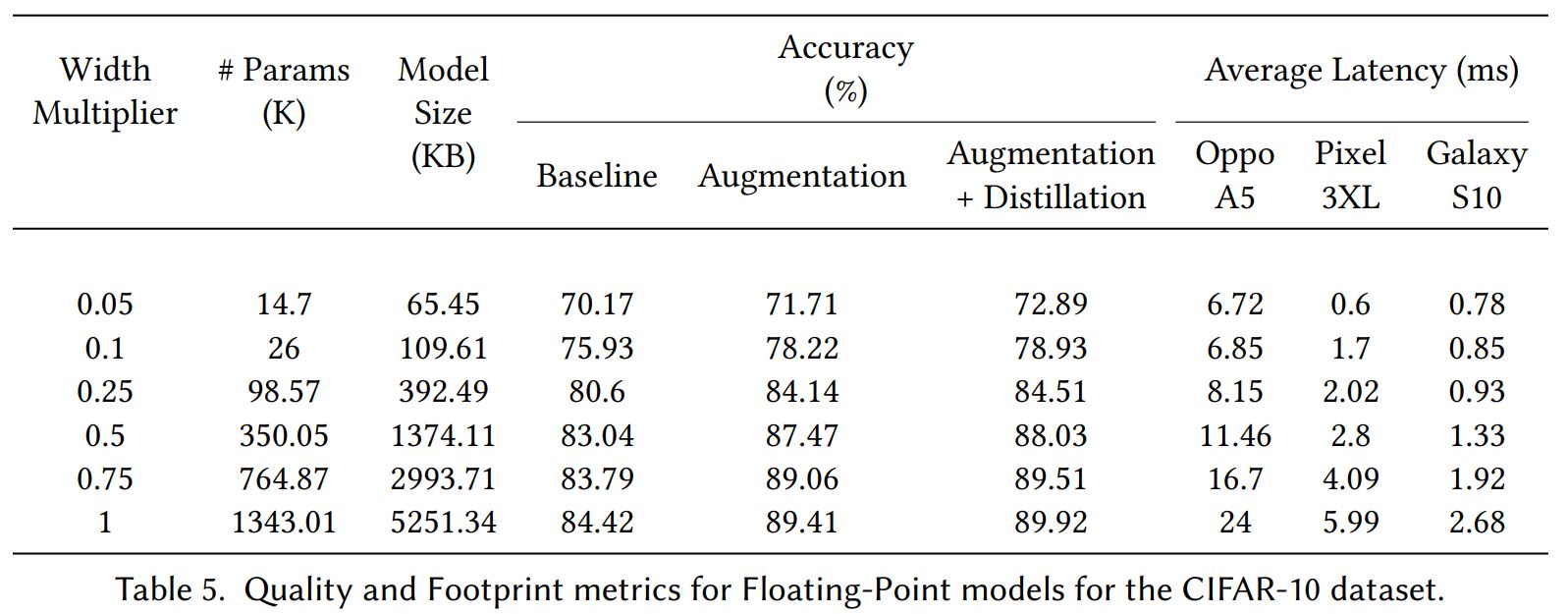

위에 테이블은 이전 테이블에 대해 양자화 된 모델입니다.
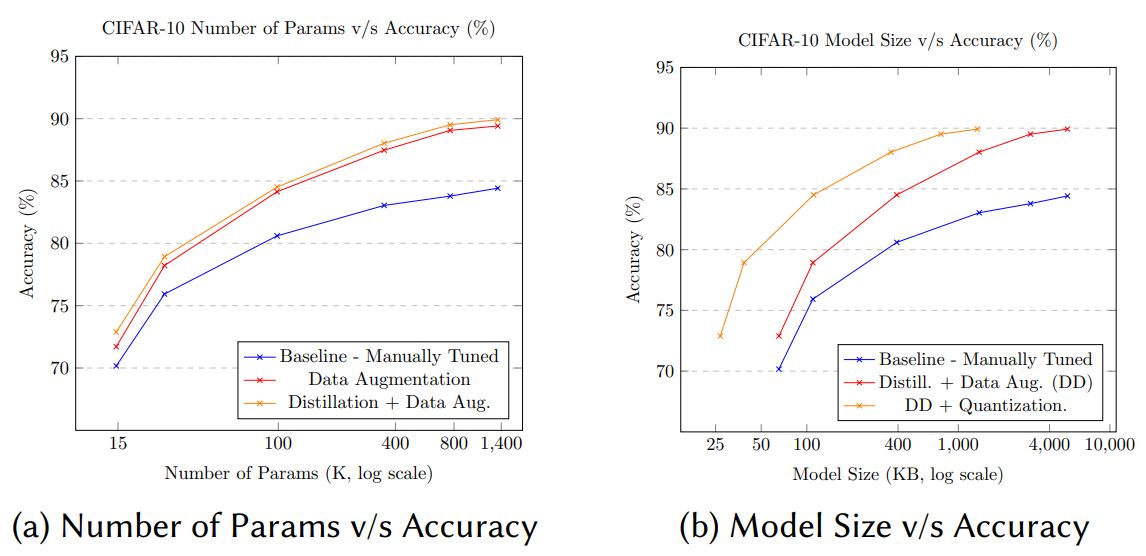
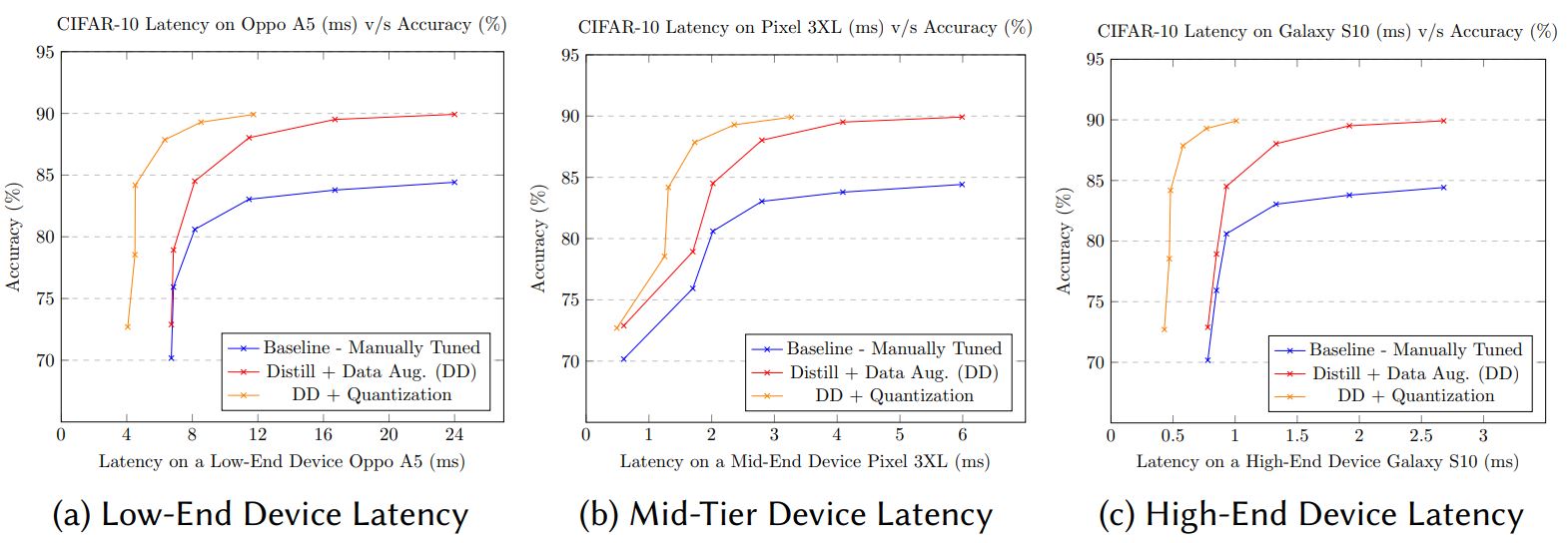
자세한 Discussion이 있는데 그래프와 테이블에 대한 설명이 있습니다. 저는 그림을 보면 충분히 설명이 되는 것 같아서 생략합니다.
모델의 효율성에 초점을 맞춘 survey paper로 실무에 적합한 논문인 것 같다. 정말 많은 도움이 됨