CornerNet 톺아보기
CornerNet
(CornerNet: Detecting Objects as Paired Keypoints)
Abstract
CornerNet은 bounding box를 왼쪽 위(top-left)와 오른쪽 아래(bottom-right)의 한 쌍의 keypoint로 감지하는 object detection에 대한 새로운 접근방법을 제안한다.
쌍을 이루는 keypoint로 object를 detection하기 때문에 anchor box를 만들 필요가 없다.
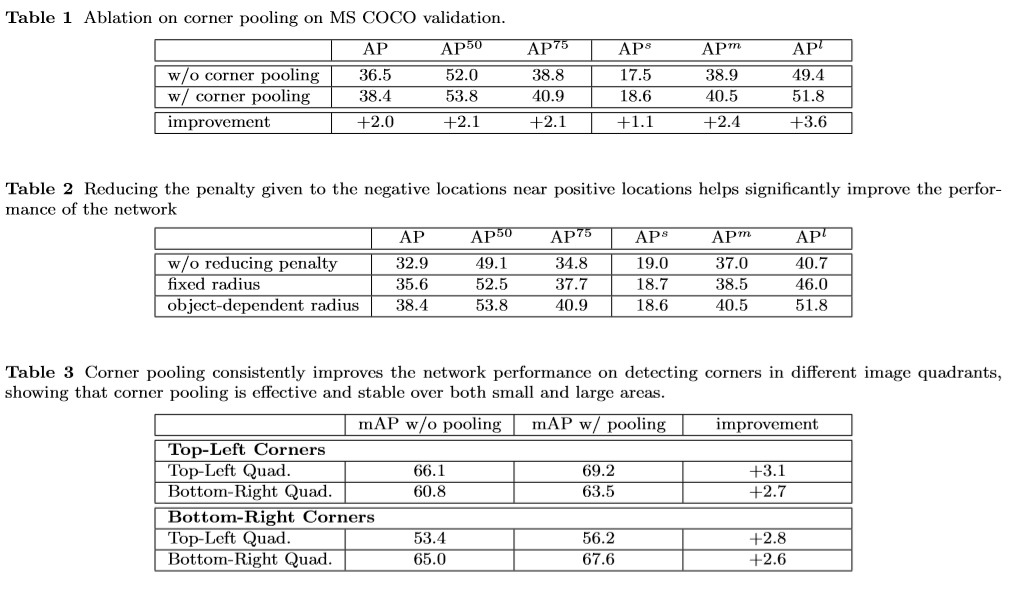
corner의 localize하는데 도움이 되는 새로운 유형의 corner pooling을 소개한다.
성능이 MS COCO에서 42.2% AP를 달성하여 기존 one-stage 검출기보다 성능이 뛰어나다.
Introduction
SOTA의 기본적인 구성 요소는 다양한 크기와 종횡비를 가지는 anchor box다. one-stage detector는 이미지 위에 anchor box를 밀집시킨뒤 anchor box를 계산하고 box regression을 통해 coordinates를 수정해서 최종 bounding box를 만들어낸다.
하지만 anchor box를 사용하는데에는 2가지 단점이 있다.
- 매우 많은 anchor box가 필요하다.
각 anchor box가 ground truth box와 얼마나 겹치는지 여부를 분류하도록 검출기를 훈련시키기 때문에 ground truth box와 충분한 겹치는 anchor box를 찾기 위해 많은 anchor box가 필요하다. 결과적으로는 작은 부분의 anchor box가 겹치게 된다. 이는 positive anchor box(foreground)와 negative anchor box(background)사이에 큰 불균형을 유발하고 학습 속도를 늦춘다.
- 많은 hyper parameter가 생긴다.
anchor box의 개수, 크기, 종횡비가 hyper parameter이고 대체로 휴리스틱(사람의 선택)을 통해 이루어진다.
이 논문에서는 새로운 접근 방식을 제안 : bounding box의 top-left 모서리와 botton-right의 모서리의 쌍을 예측하기
single convolutional network를 사용해서 top-left 모서리에 대한 heatmap, bottom-right 모서리에 대한 heatmap, 한 쌍의 모서리를 그룹화 해줄 임베딩 을 예측한다. 이러한 접근법은 human-pose estimation의 방식에서 영감을 얻었다.
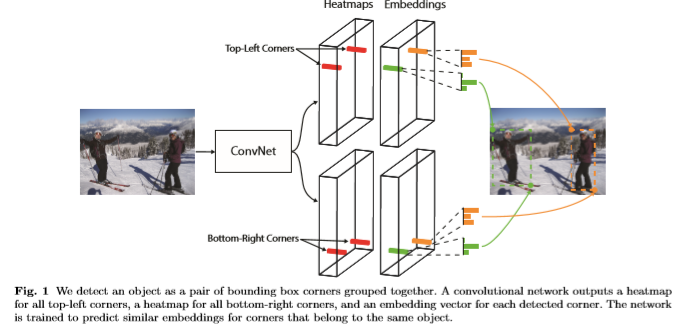
그림1 : 전체 파이프 라인
CornerNet의 또 다른 새로운 구성요소는 Convolutional Network가 경계 상자의 모서리를 더 잘 localize하는데 도움이 되는 새로운 유형의 pooling layer인 corner pooling이다. bounding box의 모서리는 보통 object의 외부에 존재한다.

이러한 경우 주변 정보를 토대로 localize를 할 수 없다. 대신에 pixel 위치에 왼쪽 상단 모서리가 있는지 확인하려면 object의 가장 위쪽 경계를 pixel 위치에서 가로 오른쪽으로 보고 가장 왼쪽 경게를 pixel 위치에서 세로 아래쪽으로 봐야한다. –> corner pooling에 동기를 부여
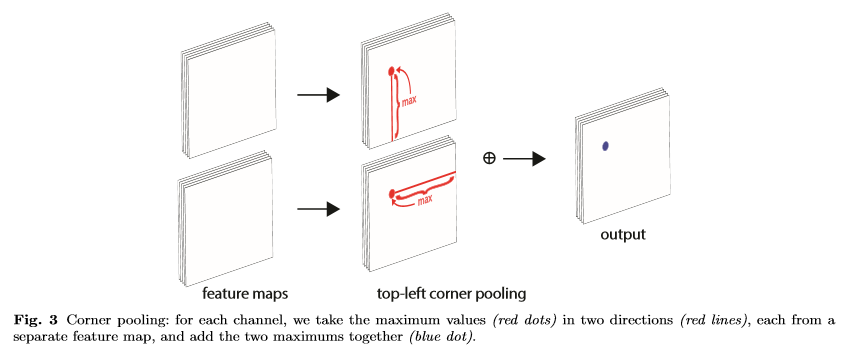
- 두개의 feature map을 받는다.
- 각 pixel 위치에서 첫 번째 feature map에서 오른쪽으로 모든 feature 벡터를 max pooling한다,
- 각 pixel 위치에서 두 번째 feature map에서 아래의 모든 feature 벡터를 max pooling한다.
- 두개의 결과를 더한다.
CornerNet
Overview
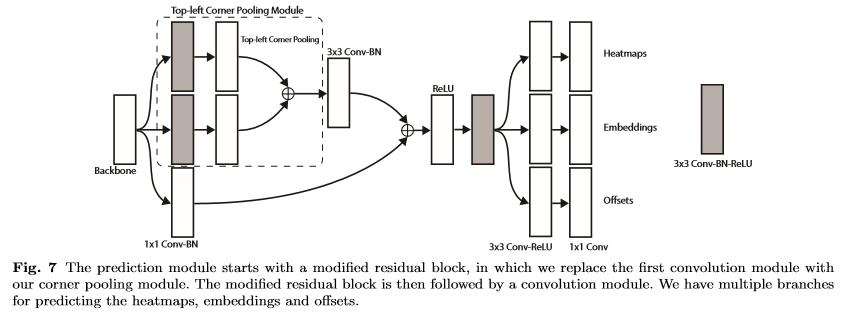
Convolution Network는 서로 다른 object categories의 corner의 위치를 나타내는 2개의 heatmap set(top-left, bottom-right)를 예측한다. Network는 또한 동일한 object로 부터 두개의 corner의 임베딩 사이의 거리가 작도록 검출 된 각 corner에 대한 임베딩 벡터를 예측한다. 더 정교한 bounding box를 예측하기 위해서 Network는 corner의 위치를 약간씩 조정하기 위해서 offset을 예측한다.
그래서 예측된 heatmap, embedding, offsets를 사용해 후처리를 하고 최종 bounding box를 얻는다.
backbone으로 Hourglass network를 사용한다. 두 개의 예측 모듈(top-left, bottom-right)이 있다. 각 모듈에는 위에 3가지를 예측하기 전에 feature를 pooling하는 corner pooling이 있다. 그리고 object를 detection 하기 위해서 여러가지 scale를 사용하지는 않는다. backbone의 출력에만 두 모듈을 적용한다.
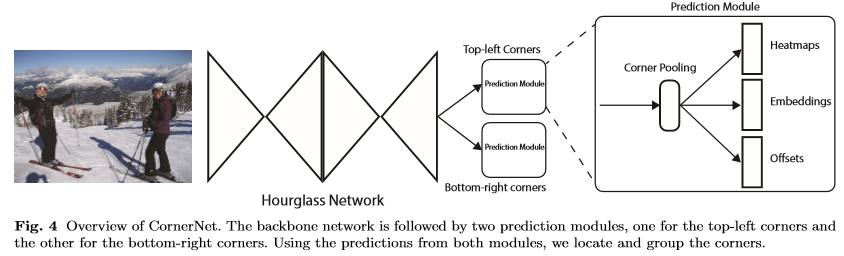
Detecting Corners
2개의 heatmap sets를 예측하자
각 heatmap에는 C(categories)개의 channel이 있고 크기는 \(H * W\)다. background에는 channel이 존재하지 않는다. 각 channel은 class의 모서리 위치를 나타내는 binary mask다. 각 모퉁이 마다 하나의 ground-truth에 positive location이 있고 다른 모든 location은 negative로 간주한다. 학습하면서 negative location에 패널티를 가하지만 positive 위치 반경 내에서의 negative location은 그 패널티를 줄인다. 왜냐하면 한쌍의 false corner detection이 각각의 ground-truth 위치에 근접한 경우에도 ground-truth와 겹치는 box를 생성할 수 있기 때문이다. 아래 주황색원의 반지름 내에 한 쌍의 점이 ground-truth에 있는 적어도 t(t=0.3) IOU의 bounding box를 생성하게해서 object의 크기에 따라 반지름을 결정한다. 패널티 감소량은 2D Gaussian : \(e^{-\frac{x^2 y^2}{2 \sigma^2}}\)(\(\sigma : \frac{radius}{3}\))에 의해서 주어진다.

Loss
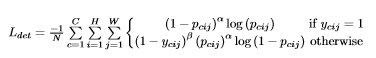
- Loss : Focal loss
- N : 이미지에서 object의 수
- \(\alpha, \beta\) : 각 점의 기여도를 제어하는 하이퍼 파라미터 \(\alpha = 2, \beta = 4\)
- \(p_{cij}\) : 예측된 heatmap의 클래스 c에 대한 위치 (i,j)의 점수
- \(y_{cij}\) : Gaussian으로 점수가 조정된 ground-truth의 heatmap
많은 네트워크는 global 정보를 수집하고 메모리의 사용을 줄이기 위해 downsampling layer를 포함한다. 이미지가 fully convolutionally 방식으로 적용되는 경우 출력 크기는 일반적으로 이미지보다 작다. 그래서 이미지에서의 위치 \((x,y)\)는 heatmap에 \(([\frac{x}{n}],[\frac{y}{n}])\) 다.(\(n =\) downsampling vector). heatmap에서 입력 이미지로 위치를 다시 매핑 할 때 약간의 정밀도가 손실 될 수 있고 그로 인해서 bounding box의 IOU에 영향을 줄 수 있기 때문에 다시 매핑 하기전에 corner location을 약간 조정해서 offsets을 예측한다.
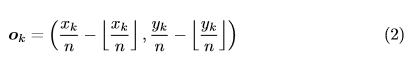
- \(o_k\) : offset
- \(x_k , y_k\) : corner \(k\) 의 \(x,y\) 좌표다.
학습시에, ground-truth corner location에 smooth L1 Loss를 적용한다.
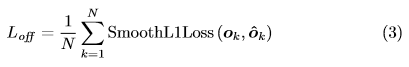
Grouping Corners
이미지에는 여러개의 object가 있고 그로인해서 여러개의 corner가 검출된다. 보통 인간의 joint을 검출하는데 각 joint에 대해서 embedding을 생성하고 그 거리를 기준으로 joint를 그룹화 한다. CornerNet도 이러한 개념을 적용한다.
각각의 corner에 대해서 embedding vector를 예측해서 top-left와 bottom-right가 동일한 bounding box에 속하는 경우 embedding vector 사이의 거리가 작아야한다. 그리고 corner사이의 거리를 기준으로 그룹화를 할 수 있다. embedding의 실제값은 중요하지 않고 embedding 사이의 거리만 중요하다. 1차원 embedding을 사용한다.
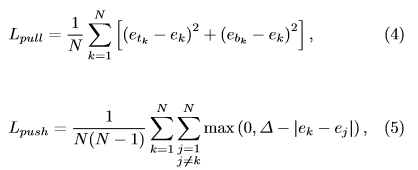
- pull loss : Network를 훈련해 corner를 그룹화
- push loss : Network를 훈련해 corner를 분리
- \(e_k\) : \(e_{t_k}, e_{b_k}\)의 평균
- \(∆\) : 1
Corner Pooling
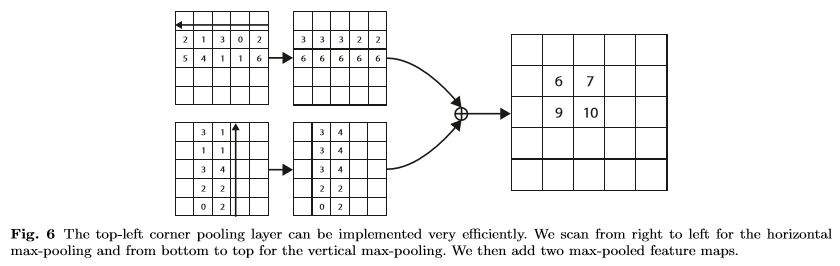
corner의 존재에 대한 local visual evidence가 없다. 즉, corner를 학습한다고 하지만 학습을 하는데 그게 corner라는 증거가없다. top-left corner를 확인하려면 object의 가장 위쪽 경계에 대해서 가로에서 오른쪽으로, 세로에서 아래쪽으로 봐야한다. 그래서 corner를 더 잘 localization 할수 있도록 corner pooling을 제안한다.
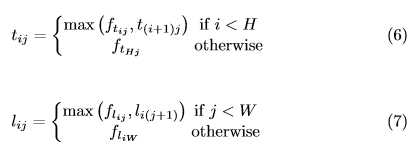
위치 \((i, j)\)의 pixel이 top-left corner인지 확인한다고 가정하자. \(f_t,f_l\)은 top-left corner pooling에 대한 입력 feature map이 되고, \(f_{t_{ij}}, f_{l_{ij}}\)는 각각 \(f_t,f_l\)의 위치 \((i,j)\)에 있는 vector가 되게 한다.
\(H * W\) feature map을 사용하기 때문에
- 첫번째 corner pooling은 \(f_t\)에서 \((i,j) ~ (i,H)\) 사이의 모든 feature vector다.
- 두번째 corner poolint은 \(f_l\)에서 \((i,j) ~ (W,j)\) 사이의 모든 feature vector다.
- 마지막으로 더한다.
Hourglass Network
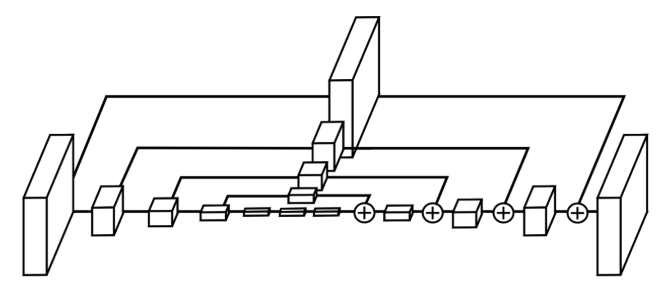
CornerNet에서 Hourglass Network를 backbone으로 사용한다. Hourglass Network는 처음에 사람의 자세를 예측하기 위해서 처음 도입되었고, 하나 이상의 Hourglass module로 구성된 fully convolution neural network다. 위와 같은 Hourglass module이 쌓이면 Hourglass Network가 완성된다. upsampling과 downsampling을 반복하고 pooling으로 발생하는 세부 손실을 줄이기 위해서 skip-connection layer가 추가된다.
이 논문에서는 원래 Hourglass의 max pooling을 사용하는 대신 convolution에서 stride를 2로 잡아서 downsampling한다. 그렇게 5번을 줄이고 경로를 따라서 채널수를 늘린다(256,384,384,384,512).
모든 skip-connection layer는 2개의 residual module로 구성이 되어있다.
Hourglass module 중간에는 512개의 channel을 가진 4개의 residual module이 있다.
Hourglass Network를 통과하기 전에 stride 2, 128 channel을 가지는 7x7 convolution과 stride 2, 256 channel을 가지는 residual module을 사용하여 이미지의 해상도를 4배 줄이고 학습을 시작한다.
Intermediate Supervision
Hourglass에서는 Intermediate Supervision를 사용하는데 말 그대로 중간 감독을 진행하는 방법이고, 중간중간에 얻어지는 예측값에 대해서 loss function을 적용할 수 있다. 하지만 성능이 저하되기 때문에 사용하지 않는다고 한다.
첫 번째 Hourglass module의 입력과 출력 모두에 1x1 Conv-BN를 적용한다. 그리고 relu와 256 channel residual block을 병합해서 두 번째 Hourglass module의 입력으로 사용한다. Hourglass-104를 사용하고 다른 SOTA detector와 달리 전체 Network에 마지막 계층의 feature만 사용해서 예측한다.
Experiments
Training Details
- 입력 해상도 : 511 x 511
- 출력 해상도 : 128 x 128
- Augmentation :
random horizontal flipping,random scaling,random cropping,random color jittering - Optimizer :
Adam - PCA를 입력이미지에 적용??
아까 해상도를 4배 줄이고 진행한다고 했기 때문에 128 x 128가 맞다.
\[L = L_{det} + \alpha L_{pull} + \beta L_{push} + \gamma L_{off}\] \[\alpha,\beta = 0.1 , \gamma = 1\]- Batch Size : 49
- learning rate : 250k = \(2.5 * 10^{-4}\), 50k = \(2.5 * 10^{-5}\)
Testing Details
- 후처리로 heatmap, embedding, offset으로 bounding box 생성
- NMS
- heatmap에서 top-left 100개 bottom-right 100개 선택
- corner의 위치는 offset으로 조정된다.
- top-left와 bottom-right의 embedding사이의 거리를 L1 distance으로 계산한다. distance가 0.5보다 크거나 다른 categorie의 corner가 포함된 쌍은 없앤다.
L1 distance
- 멘헤튼 거리라고 불린다.
- 두 점의 세로축의 차이와 가로축의 차이를 더하는 것
Benchmark
CornerNet

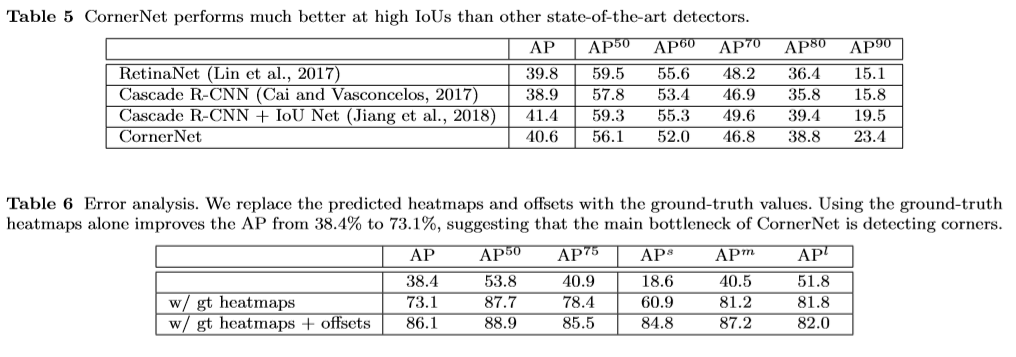
Detection Benchmark