강화학습 끄적이기
강화학습 이해하기: Q-Learning
강화학습은 기계학습의 한 분야로, 에이전트가 환경과 상호작용하며 보상을 최대화하는 행동을 학습하는 것을 목표로 합니다. 이 포스트에서는 Q-Learning이라는 강화학습 알고리즘에 대해 설명하고, 이를 구현하는 Python 코드를 제공하겠습니다.
필요한 도구들
- python 3
- tensorflow
- OpenAI Gym
Q-Learning(Table)
Q-Learning은 에이전트가 최대의 보상을 받을 수 있는 행동을 선택하는 방법을 학습하는 알고리즘입니다.
원리
Q-Learning은 다음과 같은 수식을 기반으로 합니다:
1
2
3
4
5
6
MAX Q = maxQ(state,action)
R = r1 + r2 + r3 + r4 + ''' + rn
R(t) = r(t) + r(t+1) + ''' + rn
R(t) = r(t) + R(t+1)
Q(s,a) <= r + maxQ(s',a')
Q-Learning 알고리즘의 작동 방식
- 행동 선택 후 실행
- 보상 받기
- Q 업데이트: Q(s,a) <= r + maxQ(s’,a’)
- 상태 업데이트: s => s’
Q-Learning 구현하기
아래는 Q-Learning을 구현한 Python 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
def rargmax(vector): # https://gist.github.com/stober/1943451
""" Argmax that chooses randomly among eligible maximum idices. """
m = np.amax(vector)
indices = np.nonzero(vector == m)[0]
return pr.choice(indices)
env = gym.make('FrozenLake-v3')
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n])
# Set learning parameters
num_episodes = 2000
# create lists to contain total rewards and steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
action = rargmax(Q[state, :])
# Get new state and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = reward + np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList) / num_episodes))
print("Final Q-Table Values")
print("LEFT DOWN RIGHT UP")
print(Q)
plt.bar(range(len(rList)), rList, color="red")
plt.show()
강화학습의 진화: Q-Learning에서 E-Greedy까지
강화학습은 에이전트가 환경과 상호작용하며 보상을 최대화하는 행동을 학습하는 기계학습의 한 분야입니다. 이번 포스트에서는 Q-Learning에서 시작하여 E-Greedy라는 전략을 사용하는 방법에 대해 알아보겠습니다.
Exploit vs Exploration
에이전트가 어떤 행동을 선택해야 할지 결정하는 방법에는 크게 두 가지 접근법이 있습니다.
- Exploit: 현재 알고 있는 최선의 행동을 선택합니다.
- Exploration: 새로운 행동을 시도하여 더 좋은 결과를 찾아봅니다.
이 두 가지 접근법 중 어떤 것을 선택할지는 상황에 따라 달라집니다.
E-Greedy 전략
E-Greedy 전략은 Exploration과 Exploit을 적절히 섞는 방법입니다. 확률 e로 랜덤한 행동을 선택하고, 1-e의 확률로 현재 가장 좋은 행동을 선택합니다.
Discount Future Reward
미래의 보상을 현재의 보상보다 낮게 평가하는 방법을 Discount Future Reward라고 합니다. 이를 통해 에이전트는 미래의 보상을 고려하면서도 최적의 길을 선택하는 행동을 학습하게 됩니다.
아래는 이러한 개념들을 적용한 Python 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
env = gym.make('FrozenLake-v3')
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n])
# Set learning parameters
dis = .99
num_episodes = 2000
# create lists to contain total rewards and steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
# choose an action by greedily (with noise) picking from Q table
action = np.argmax(Q[state, :] + np.random.randn(1,env.action_space.n) / (i+1))
# Get new state and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = reward + dis * np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList) / num_episodes))
print("Final Q-Table Values")
print("LEFT DOWN RIGHT UP")
print(Q)
plt.bar(range(len(rList)), rList, color="red")
plt.show()
E-Greedy 전략을 적용한 경우에는 아래와 같이 코드를 수정할 수 있습니다.
1
2
3
4
5
6
7
e = 1. / ((i//100)+1)
while not done:
if np.random.rand(1) < e:
action = env.action_space.sample()
else:
action = np.argmax(Q[state,:])
강화학습의 환경: Deterministic과 Stochastic
강화학습에서는 에이전트의 행동과 그 결과에 대한 확실성에 따라 환경을 Deterministic과 Stochastic으로 나눌 수 있습니다.
Deterministic vs Stochastic 환경
- Deterministic 환경은 에이전트의 행동 결과가 일정한 환경을 말합니다.
- Stochastic 환경은 에이전트의 행동 결과가 불확실한 환경을 말합니다.
예를 들어, ‘FrozenLake-v0’ 환경은 Stochastic 환경으로, 에이전트의 행동 결과가 항상 일정하지 않습니다. 이런 환경에서는 기존의 Q-Learning 알고리즘을 그대로 적용하면 대부분 실패하게 됩니다.
Stochastic 환경에서의 해결책
Stochastic 환경에서는 다양한 전략을 사용해야 합니다.
여러 에이전트의 행동을 고려하거나, 에이전트의 행동을 적절히 제한하는 방법이 있습니다. Q-Learning 알고리즘에서는 learning rate라는 개념을 도입하여 이를 해결합니다. Learning rate는 Q값을 얼마나 빠르게 업데이트할지 결정하는 파라미터입니다.
아래는 이를 적용한 Python 코드입니다.
source
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import gym
import numpy as np
import matplotlib.pyplot as plt
env = gym.make('FrozenLake-v0')
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n])
# Set learning parameters
dis = .99
learning_rate = 0.85
num_episodes = 2000
# create lists to contain total rewards and steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
# choose an action by greedily (with noise) picking from Q table
action = np.argmax(Q[state, :] + np.random.randn(1,env.action_space.n) / (i+1))
# Get new state and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = (1-learning_rate)*Q[state, action] \
+ learning_rate*(reward + dis * np.max(Q[new_state, :]))
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList) / num_episodes))
print("Final Q-Table Values")
print("LEFT DOWN RIGHT UP")
print(Q)
plt.bar(range(len(rList)), rList, color="red")
plt.show()
Q-Network: 신경망을 이용한 강화학습
강화 학습에서는 Q-Learning 알고리즘을 통해 행동을 학습합니다. 하지만, 상태 공간이 너무 크거나 연속적인 경우에는 Q-Table을 사용하기 어렵습니다. 이런 경우에는 신경망을 이용하여 Q 함수를 근사하는 방법을 사용할 수 있습니다. 이를 Q-Network라고 합니다.
Q-Network의 동작 방식
Q-Network는 신경망을 통해 Q 함수를 근사합니다. 이를 통해 Q 값이 매우 큰 상태-행동 쌍을 찾아내서 에이전트의 행동을 결정하게 됩니다.
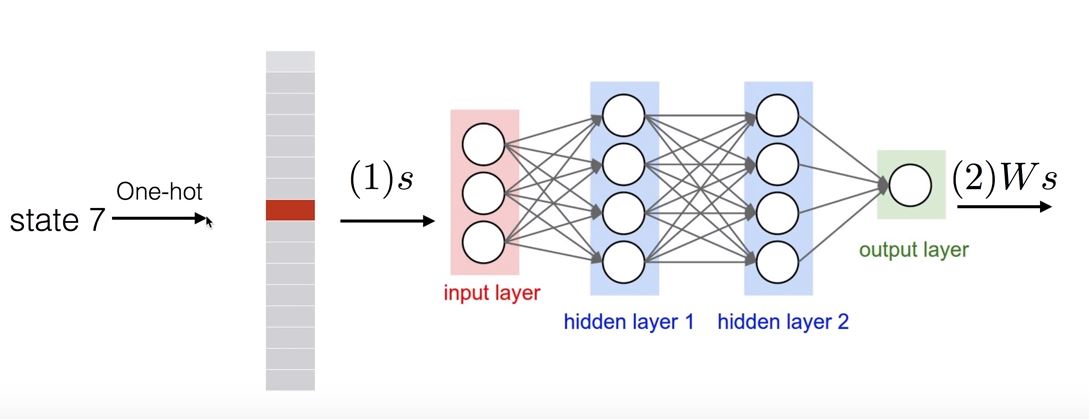
Q-Network 학습 알고리즘
Q-Network 학습 알고리즘은 다음과 같습니다.
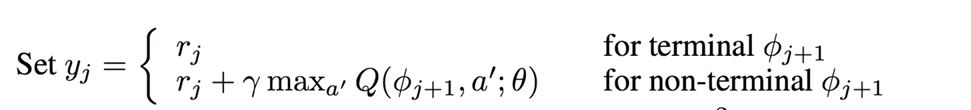
이 알고리즘에서는 E-Greedy 전략을 사용하여 행동을 선택합니다. 또한, 신경망의 입력으로 one-hot 벡터를 사용합니다.
아래는 이를 구현한 Python 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
import gym
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
def one_hot(x):
return np.identity(16)[x:x+1]
# make env
env = gym.make('FrozenLake-v0')
# parameter
# 16
input_size = env.observation_space.n
# 4
output_size = env.action_space.n
learning_rate = 0.1
dis = .99
num_episodes = 2000
# input,weight
X = tf.placeholder(shape=[1,input_size],dtype=tf.float32)
W = tf.Variable(tf.random_uniform([input_size,output_size],0,0.01))
# output,y label
Qpred = tf.matmul(X,W)
Y = tf.placeholder(shape=[1,output_size],dtype=tf.float32)
# loss
loss = tf.reduce_mean(tf.square(Y-Qpred))
# train
train = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(loss)
rList = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(num_episodes):
state = env.reset()
e = 1./((i/50) + 10)
rAll = 0
done = False
local_loss = []
while not done:
Qs = sess.run(Qpred,feed_dict={X: one_hot(state)})
# e-greed select action
if np.random.rand(1) < e:
a = env.action_space.sample()
else:
a = np.argmax(Qs)
# get state,reward
state1, reward, done, _ = env.step(a)
# Update
if done:
Qs[0,a] = reward
else:
Qs1 = sess.run(Qpred,feed_dict={X: one_hot(state1)})
Qs[0,a] = reward + dis * np.max(Qs1)
# train
sess.run(train,feed_dict={X: one_hot(state), Y: Qs})
rAll += reward
state = state1
rList.append(rAll)
print(rAll)
#print("step[" + str(num_episodes) + "/" + str(i) + "]")
print("percent of episodes: " + str(sum(rList) / num_episodes) + "%")
plt.bar(range(len(rList)),rList,color="red")
plt.show()
DQN: 강화학습에서의 이슈와 해결책
강화 학습에서는 몇 가지 주요 이슈가 있습니다:
학습 이슈
Correlations between samples: 강화학습에서는 연속된 행동 간의 상관관계가 높아, 이로 인해 학습이 어려워질 수 있습니다. 즉, 현재 행동과 그 다음 행동이 거의 유사하다면, 학습 알고리즘이 적절하게 일반화하는 데 어려움을 겪을 수 있습니다.
Non-stationary target: 강화학습에서는 목표 값이 계속 변화합니다. 이는 학습 과정에서 타겟 값이 고정되지 않고 계속 변화하기 때문에 발생하는 문제입니다.
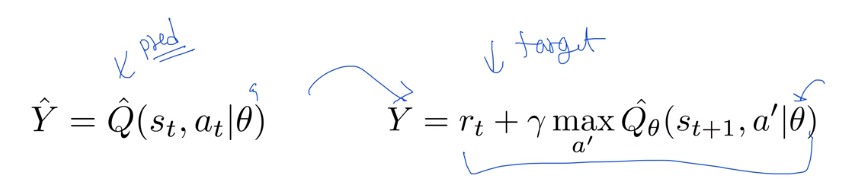
DQN의 해결책
DQN(Deep Q-Network)은 위의 두 가지 문제를 해결하기 위한 방법을 제공합니다.
Go deep: 신경망의 레이어를 깊게 쌓음으로써 복잡한 행동을 모델링할 수 있습니다.
Capture and replay: 일정 시간 동안 버퍼에 경험을 쌓아놓고, 이를 랜덤하게 선택하여 학습을 진행합니다. 이를 통해 상관관계 문제를 완화시킵니다.
Separate network: DQN은 두 개의 네트워크를 사용합니다. 하나는 가중치를 학습하는 네트워크이고, 다른 하나는 타겟 값을 제공하는 네트워크입니다. 일정 시간 간격으로 학습 네트워크의 가중치를 타겟 네트워크로 복사함으로써, 타겟 값의 변동을 줄입니다.
DQN 알고리즘의 학습 과정
- 네트워크 초기화
- 환경 초기화
- E-Greedy 전략을 사용하여 행동 선택
- 선택한 행동에 따른 보상과 다음 상태를 환경으로부터 얻음
- 경험을 버퍼에 저장
- 버퍼에서 랜덤하게 경험을 선택
- 선택한 경험을 사용하여 네트워크를 학습
- DQN은 이런 방식으로 강화학습에서의 이슈를 해결하고, 성능을 높이기 위한 방법을 제공합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
import numpy as np
import tensorflow as tf
import random
from collections import deque
from DQN import DQN
import gym
from typing import List
env = gym.make('CartPole-v0')
env = gym.wrappers.Monitor(env, directory="gym-results/", force=True)
# Constants defining our neural network
INPUT_SIZE = env.observation_space.shape[0]
OUTPUT_SIZE = env.action_space.n
DISCOUNT_RATE = 0.99
REPLAY_MEMORY = 50000
BATCH_SIZE = 64
TARGET_UPDATE_FREQUENCY = 5
MAX_EPISODES = 5000
def replay_train(mainDQN: DQN, targetDQN: DQN, train_batch: list) -> float:
"""Trains `mainDQN` with target Q values given by `targetDQN`
Args:
mainDQN (dqn.DQN): Main DQN that will be trained
targetDQN (dqn.DQN): Target DQN that will predict Q_target
train_batch (list): Minibatch of replay memory
Each element is (s, a, r, s', done)
[(state, action, reward, next_state, done), ...]
Returns:
float: After updating `mainDQN`, it returns a `loss`
"""
states = np.vstack([x[0] for x in train_batch])
actions = np.array([x[1] for x in train_batch])
rewards = np.array([x[2] for x in train_batch])
next_states = np.vstack([x[3] for x in train_batch])
done = np.array([x[4] for x in train_batch])
X = states
Q_target = rewards + DISCOUNT_RATE * np.max(targetDQN.predict(next_states), axis=1) * ~done
y = mainDQN.predict(states)
y[np.arange(len(X)), actions] = Q_target
# Train our network using target and predicted Q values on each episode
return mainDQN.update(X, y)
def get_copy_var_ops(*, dest_scope_name: str, src_scope_name: str) -> List[tf.Operation]:
"""Creates TF operations that copy weights from `src_scope` to `dest_scope`
Args:
dest_scope_name (str): Destination weights (copy to)
src_scope_name (str): Source weight (copy from)
Returns:
List[tf.Operation]: Update operations are created and returned
"""
# Copy variables src_scope to dest_scope
op_holder = []
src_vars = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES, scope=src_scope_name)
dest_vars = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES, scope=dest_scope_name)
for src_var, dest_var in zip(src_vars, dest_vars):
op_holder.append(dest_var.assign(src_var.value()))
return op_holder
def bot_play(mainDQN: DQN, env: gym.Env) -> None:
"""Test runs with rendering and prints the total score
Args:
mainDQN (dqn.DQN): DQN agent to run a test
env (gym.Env): Gym Environment
"""
state = env.reset()
reward_sum = 0
while True:
env.render()
action = np.argmax(mainDQN.predict(state))
state, reward, done, _ = env.step(action)
reward_sum += reward
if done:
print("Total score: {}".format(reward_sum))
break
def main():
# store the previous observations in replay memory
replay_buffer = deque(maxlen=REPLAY_MEMORY)
last_100_game_reward = deque(maxlen=100)
with tf.Session() as sess:
mainDQN = DQN(sess, INPUT_SIZE, OUTPUT_SIZE, name="main")
targetDQN = DQN(sess, INPUT_SIZE, OUTPUT_SIZE, name="target")
sess.run(tf.global_variables_initializer())
# initial copy q_net -> target_net
copy_ops = get_copy_var_ops(dest_scope_name="target",
src_scope_name="main")
sess.run(copy_ops)
for episode in range(MAX_EPISODES):
e = 1. / ((episode / 10) + 1)
done = False
step_count = 0
state = env.reset()
while not done:
if np.random.rand() < e:
action = env.action_space.sample()
else:
# Choose an action by greedily from the Q-network
action = np.argmax(mainDQN.predict(state))
# Get new state and reward from environment
next_state, reward, done, _ = env.step(action)
if done: # Penalty
reward = -1
# Save the experience to our buffer
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > BATCH_SIZE:
minibatch = random.sample(replay_buffer, BATCH_SIZE)
loss, _ = replay_train(mainDQN, targetDQN, minibatch)
if step_count % TARGET_UPDATE_FREQUENCY == 0:
sess.run(copy_ops)
state = next_state
step_count += 1
print("Episode: {} steps: {}".format(episode, step_count))
# CartPole-v0 Game Clear Checking Logic
last_100_game_reward.append(step_count)
if len(last_100_game_reward) == last_100_game_reward.maxlen:
avg_reward = np.mean(last_100_game_reward)
if avg_reward > 199:
print("Game Cleared in {episode} episodes with avg reward {avg_reward}")
break
if __name__ == "__main__":
main()
DQN.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import numpy as np
import tensorflow as tf
class DQN:
def __init__(self, session: tf.Session, input_size: int, output_size: int, name: str="main") -> None:
"""DQN Agent can
1) Build network
2) Predict Q_value given state
3) Train parameters
Args:
session (tf.Session): Tensorflow session
input_size (int): Input dimension
output_size (int): Number of discrete actions
name (str, optional): TF Graph will be built under this name scope
"""
self.session = session
self.input_size = input_size
self.output_size = output_size
self.net_name = name
self._build_network()
def _build_network(self, h_size=16, l_rate=0.001) -> None:
"""DQN Network architecture (simple MLP)
Args:
h_size (int, optional): Hidden layer dimension
l_rate (float, optional): Learning rate
"""
with tf.variable_scope(self.net_name):
self._X = tf.placeholder(tf.float32, [None, self.input_size], name="input_x")
net = self._X
net = tf.layers.dense(net, h_size, activation=tf.nn.relu)
net = tf.layers.dense(net, self.output_size)
self._Qpred = net
self._Y = tf.placeholder(tf.float32, shape=[None, self.output_size])
self._loss = tf.losses.mean_squared_error(self._Y, self._Qpred)
optimizer = tf.train.AdamOptimizer(learning_rate=l_rate)
self._train = optimizer.minimize(self._loss)
def predict(self, state: np.ndarray) -> np.ndarray:
"""Returns Q(s, a)
Args:
state (np.ndarray): State array, shape (n, input_dim)
Returns:
np.ndarray: Q value array, shape (n, output_dim)
"""
x = np.reshape(state, [-1, self.input_size])
return self.session.run(self._Qpred, feed_dict={self._X: x})
def update(self, x_stack: np.ndarray, y_stack: np.ndarray) -> list:
"""Performs updates on given X and y and returns a result
Args:
x_stack (np.ndarray): State array, shape (n, input_dim)
y_stack (np.ndarray): Target Q array, shape (n, output_dim)
Returns:
list: First element is loss, second element is a result from train step
"""
feed = {
self._X: x_stack,
self._Y: y_stack
}
return self.session.run([self._loss, self._train], feed)