StyleGAN 톺아보기
StyleGANv1
개인적으로 딥러닝모델을 이해할 때 각 모듈의 입력 출력 역할이 중요하다고 생각합니다.
먼저.. StyleGAN은 PGGAN 기반으로 latent space를 학습 데이터 분포와 비슷하게 변화시키는 방법을 학습하는 모델입니다. 거기에 더해 이미지의 style을 변화시키기 위해 entangle space를 disentangle spce로 변환하기 위한 몇가지 방법을 제안합니다.
- entangle
- 특징 구분이 어렵도록 얽혀있는 상태를 나타냅니다.
- disentangle
- 특징 구분이 잘되어있어 특징을 변환하는게 쉬움
1
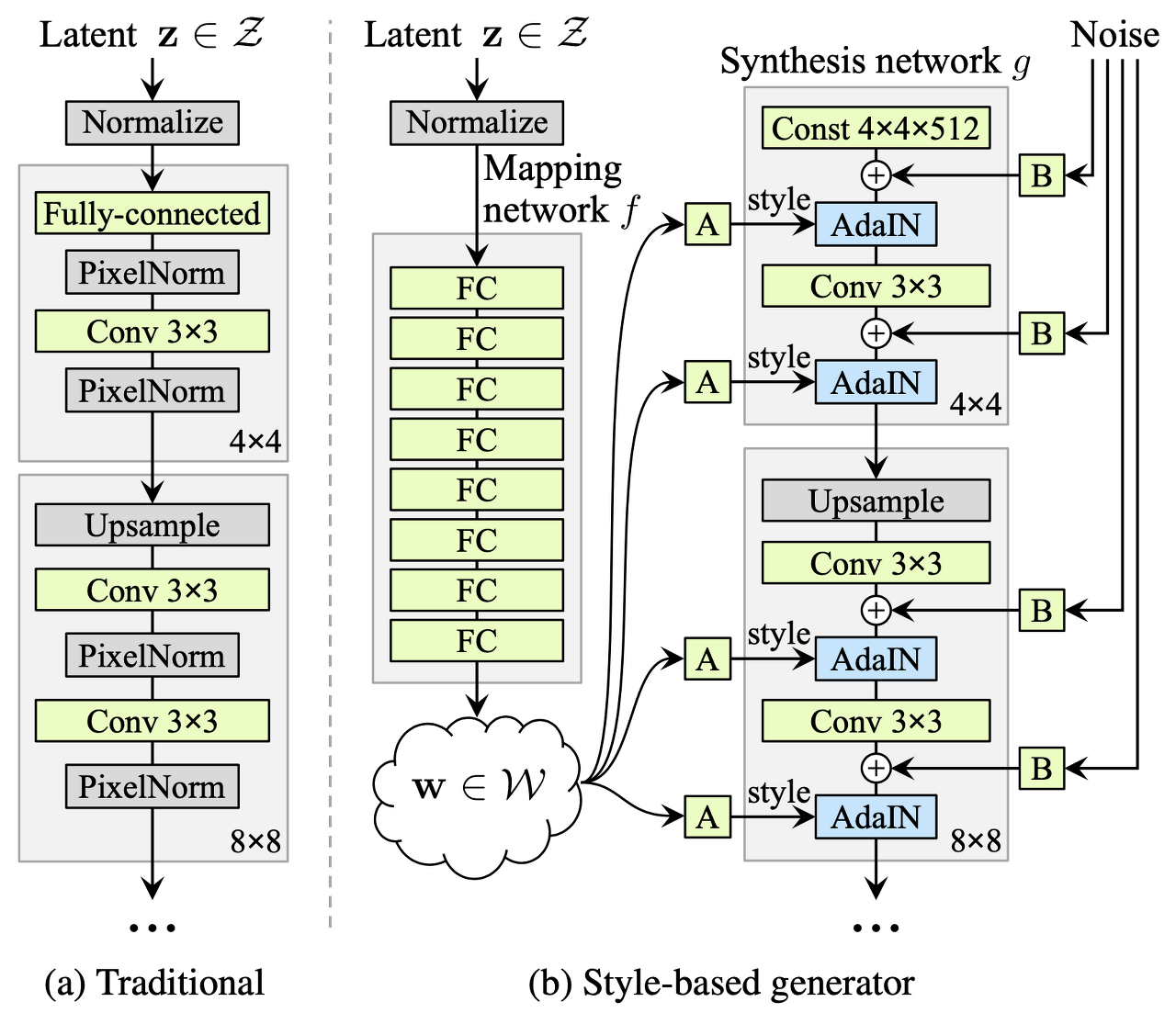
latent vector(z) -> mapping network -> intermediate latent vector(w) -> synthesis network -> output
Mapping Network
PGGAN의 경우 latent vector를 바로 generator에 넣기 때문에 entanglement가 발생하며 이는 style을 조절하기 어렵습니다. 이를 해결하기 위해 latent vector를 mapping 해준 뒤 사용합니다.
Noise
Stochastic variation(머리카락, 수염, 주름 등)을 처리하도록 synthesis network의 각 layer마다 noise를 추가로 넣어줍니다. 이를 통해 더 사실적인 이미지를 생성하고 input latent vector는 이미지의 중요한 정보(성별, 이종, 헤어스타일 등)를 표현하는 데에만 집중합니다.
AdalN
mapping한 latent vector w를 synthesis network에 입력하여 이미지를 생성합니다. 여기서 PGGAN과 다르게 AdalN을 사용합니다.
\[AdalN(x_i, y) = y_{s,i} \frac{x_i - \mu(x_i)}{\sigma(x_i)} + y_{b,i}\]Style Mixing
StyleGAN generator는 합성 네트워크의 각 단계에서 중간 벡터를 이용하는데, 이로 인해 네트워크는 각 단계가 상관관계가 있음을 학습한다. 이러한 상관관계를 줄이기 위해, 모델은 랜덤 하게 두 개의 인풋 벡터를 선택한 후 각각에 대한 중간 벡터 w를 생성한다. 그리고 초기 단계에서는 첫번째 벡터를 통해 학습하고, 랜덤한 포인트 이후의 나머지 레벨에서는 다른 벡터를 통해 학습하게 된다. 랜덤하게 벡터를 바꾸는 것은 네트워크가 레벨 간 상관관계를 학습하고 의지하지 않도록 보장한다.
- Coarse styles
- 4x4 layer ~ 8x8 layer
- 포즈, 일반적인 헤어스타일, 얼굴형 등에 영향
- Middle styles
- 16x16 layer ~ 32x32 layer
- 자세한 얼굴 특징, 헤어스타일, 눈 뜨고/감음 등에 영향
- Fine styles
- 64x64 layer ~ 1024x1024 layer
- 눈, 머리, 피부 등의 색 조합과 미세한 특징 등에 영향

StyleGANv2
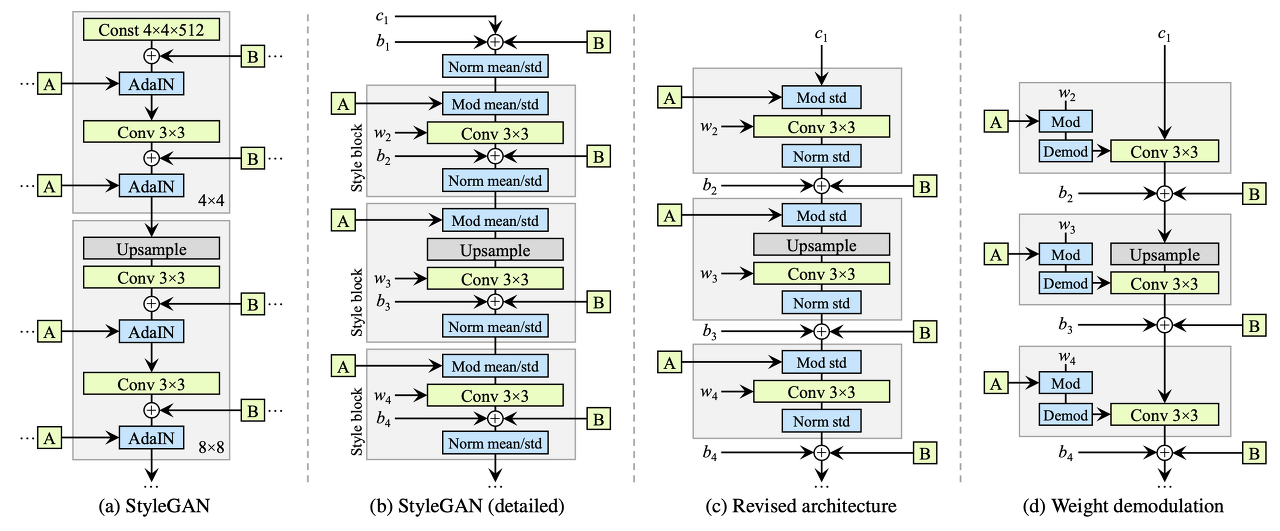
StyleGAN에서 Droplet artifacts, Phase artifacts가 존재하는 이유를 분석하고 이를 해결하기 위해 모델 구조와 훈련 방법을 개선하였다.
inversion이 더 잘 동작하도록 하였다.
Droplet Artifacts
먼저 64 x 64 해상도부터 물방울 같은 결함이 보이고 모든 해상도에서 다 보인다.
nomarlized feature map 상에서 매우 두드러진 특징이 나타나는 것을 보며 AdalN이 너무 강하여 다른 정보들을 파괴하는 것이라 결론을 지었다.
그래서 normalization 단계를 제거하였더니 결함이 사라지는 것을 발견
이를 통해 제안된 구조는
- AdalN에서 평균을 제거하고 표준편차만 사용한다.
- convolution weight를 normalization 한다.
- bias와 noise를 block의 밖으로 두어 style과 noise의 영향력을 독립시켰다.
최종적으로 그림 (d)가 됨
Phase Artifact
Latent manipulation 과정에서 특정 요소(이빨 등)가 고정된다. 이는 Progressive growing이 원인으로 추정되며 각 resolution이 output resolution에 즉시 영향을 미친다.
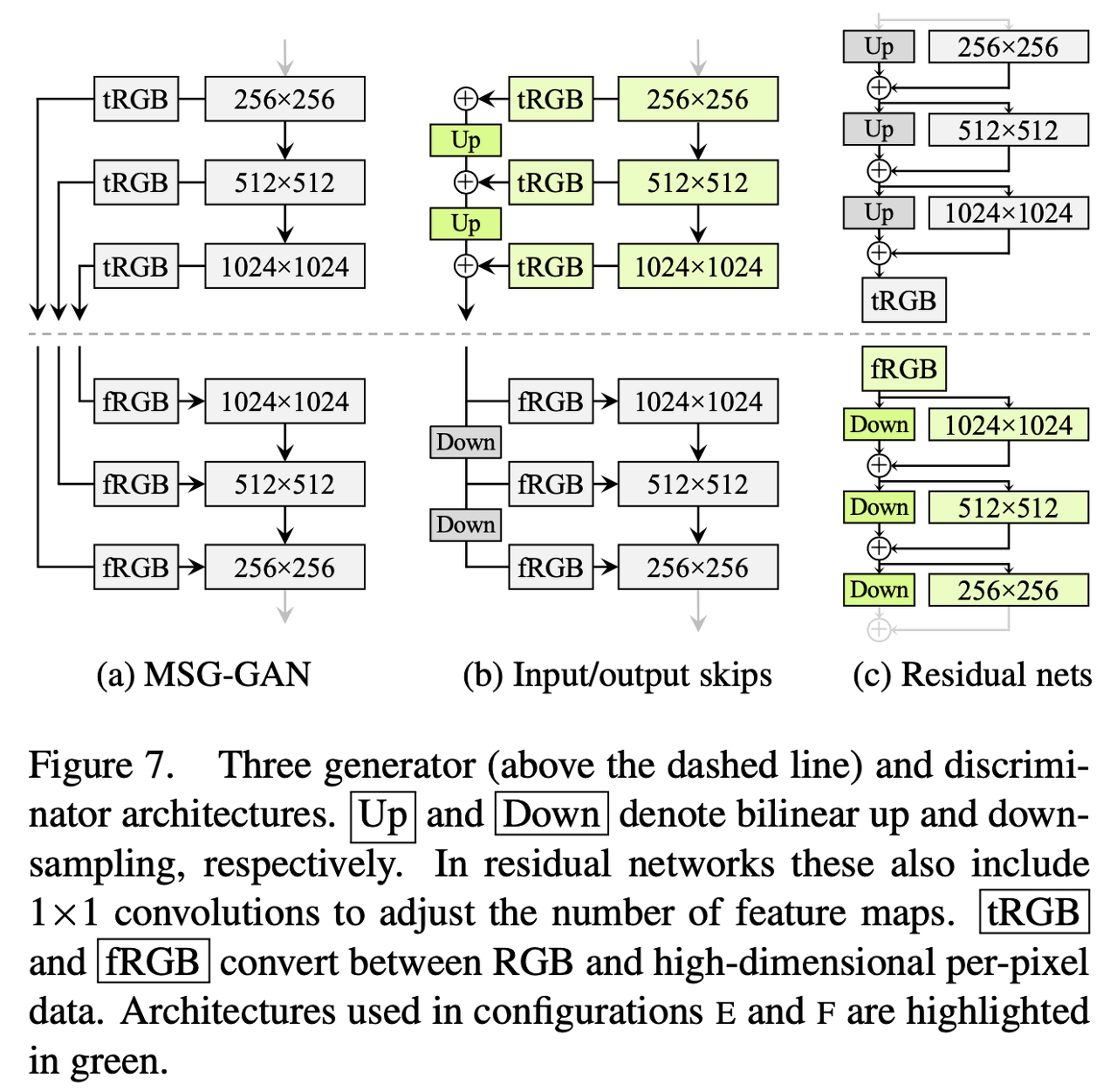
- Progressive growing 대신에 단순한 feedforward 네트워크를 사용한다.
- MSG-GAN과 비슷한 기관을 갖는 네트워크
- 위에 그림을 각 G와 D를 조합하여 비교
- G output skips과 D residual이 좋았음
Regularization
PPL은 latent vector가 특정 단위로 계속 조절을 하면서 이미지를 서서히 변하게 함
PPL이 작으면 부드럽게 변화함
PPL이 크면 급격히 변화함(broken image)
Lazy Regularization
16번의 mini-batch마다 한번 씩 정규화
Path Length Regularization
손실 함수에 적용되는 새로운 정규화 term을 제안했다. latent space의 부드러운 정도를 나타내는 Path Length Regularization
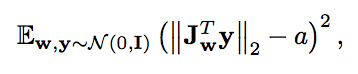
- a is a constant
y is a random image generated from a normal distribution.
- architecture 탐색이 더 쉬워지고
- smoother generator는 invert를 더 쉽도록 한다.
- \(w\)가 움직이는 만큼 \(G(x)\)도 일정하게 움직인다.
- 명시적으로 Jacobian Matrix를 계산하지 않는다.
생성된 이미지와 랜덤한 이미지를 곱하고 w에 대해서 미분
StyleGANv3
StyleGANv1과 StyleGANv2가 픽셀 좌표에 의존하는 문제점을 해결하기 위한 방법을 제안합니다.
예제 보는 사이트 : https://nvlabs.github.io/stylegan3/
위에 사이트에서 영상을 보시면 latent space를 조절하면서 얼굴이 이동할 때 머리카락이나 코, 눈 등 다양한 요소가 자연스럽게 이동하는 것이 아닌 고정 된 픽셀 좌표에 의존하도록 이동하는 문제점을 해결합니다.
-> 이런 문제를 texture sticking 이라고 합니다.

위 그림 왼쪽은 중심을 기준으로 주변 latent space로 이동 후 평균낸 것인데 당연히 blurred 이미지가 나와야 할 것이라 예상하지만 StyleGAN2에서는 sharped 이미지가 나옴(눈 주변 털)
오른쪽 그림은 중심 라인을 두고 인물을 이동시켜 머리카락의 변화를 봄 이동하는 것에 따라 자연스럽게 컬이 나와야하는데 StyleGANv2는 마치 머리카락이 붙어서 같이 옮겨가는 듯하게 보임
실세계에서는 얼굴이 이동함과 동시에 다양한 요소가 자연스럽게 이동한다…
- spatial information을 제거해야함
- translation equivariant representation이 필요함
- aliasing을 제거해야한다고 합니다.
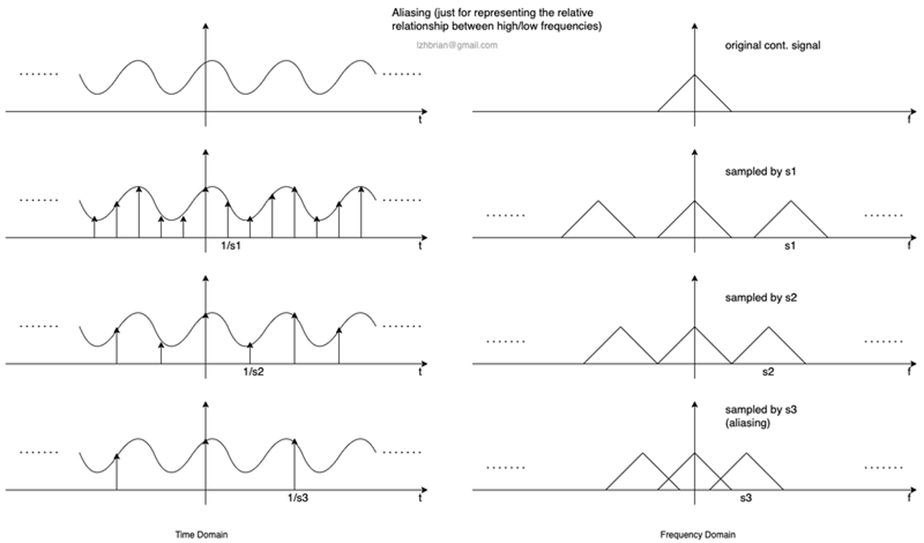
- Nyquist-Shannon sampling theorem
“만약 신호가 대역제한(bandlimited)신호이고, 표본화 주파수가 신호의 대역의 두 배 이상이라면 표본으로부터 연속 시간 기저 대역 신호를 완전히 재구성할 수 있다.”
예를들어 신호 주파수가 10 Hz 이면 샘플링 주파수는 5 Hz 이상이어야 한다. 만약 아래로 떨어지면 aliasing이 발생함
- https://www.youtube.com/watch?v=BZwUR9hvBPE
- https://github.com/lzhbrian/alias-free-gan-explanation?ref=pythonrepo.com
위 자료를 참고해 추가 정리하기