Sora 훑어보기
Sora 훑어보기
- 논문: Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
- GitHub: https://github.com/lichao-sun/SoraReview
- WebSite: https://sora.com/
🔍 Sora란?
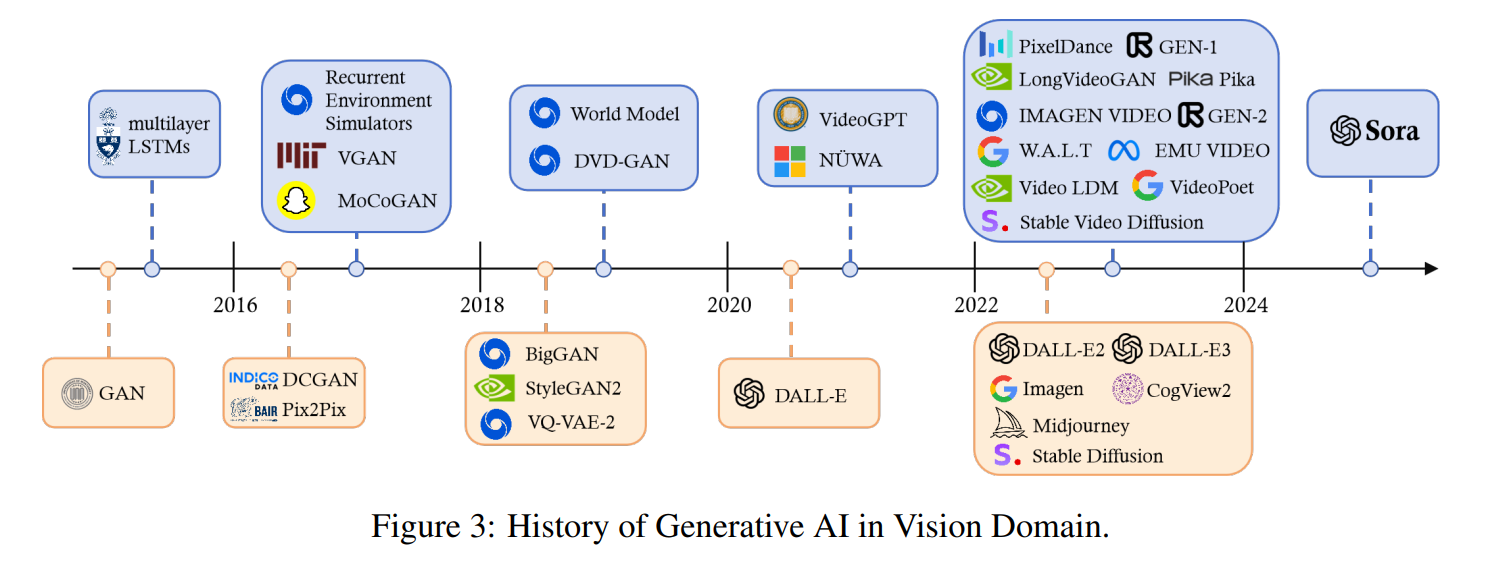
Sora는 OpenAI에서 개발한 최초의 텍스트-비디오 생성 AI 모델입니다.
이 모델은 자연어 입력을 기반으로 최대 1분 길이의 고품질 영상을 생성할 수 있는 AI 시스템으로,
기존 텍스트-이미지 생성 모델인 DALL·E의 비디오 확장판이라 볼 수 있습니다.
기존 비디오 생성 모델은 다음과 같은 한계를 갖고 있었습니다.
- 🎬 영상 길이 제한 (대부분 4~10초 이내)
- 🎥 물리적 연속성 부족 (물체 움직임, 카메라 이동 부자연스러움)
- 🎭 캐릭터 일관성 문제 (장면 전환 시 같은 인물이 다른 모습으로 등장)
- ⚡ 해상도 저하 (고해상도 비디오 생성이 어려움)
Sora는 대규모 비디오 데이터와 Diffusion Transformer 아키텍처를 활용하여 이러한 문제를 해결합니다.

🚀 Sora의 핵심 AI 기술
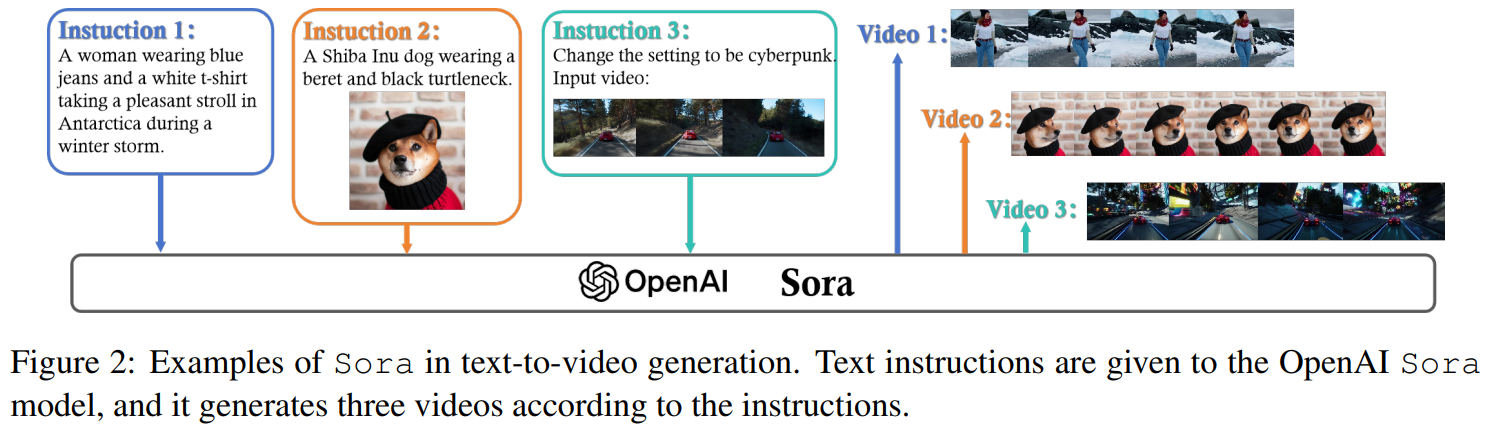
1️⃣ Diffusion Transformer 기반 비디오 생성
Sora는 텍스트 입력을 받아 점진적으로 고해상도 영상을 생성하는 방식으로 작동합니다.
이는 기존 이미지 생성 모델인 Stable Diffusion 및 DALL·E 3의 원리를 확장한 것입니다.
🏗️ 비디오 생성 과정
1️⃣ 텍스트 프롬프트 처리
- GPT-4 기반 텍스트 이해 모듈이 텍스트 입력을 해석
- 장면, 캐릭터, 조명, 카메라 움직임 등을 포함하는 비디오 시퀀스 정보 생성
2️⃣ Latent Spacetime Encoding (시공간 잠재 표현)
- Spacetime Latent Patches 방식을 활용하여 비디오를 작은 블록(패치) 단위로 변환
- 공간적 연속성(Spatial Coherence)과 시간적 연속성(Temporal Consistency)을 유지
3️⃣ Diffusion Transformer 적용
- 초기 노이즈 상태의 영상에서 시작하여 점진적으로 선명한 비디오를 생성
- 기존 2D 이미지 생성 방식이 아니라 3D 시공간 데이터 기반 디퓨전 모델 사용
4️⃣ 고해상도 비디오 복원 (Super-resolution)
- VAE(Variational Autoencoder) 기반 비디오 압축 및 복원 네트워크 활용
- 다양한 해상도(720p, 1080p) 및 다양한 종횡비(16:9, 9:16 등) 지원
2️⃣ 모델 아키텍처: Diffusion Transformer + VAE
Sora는 기존 텍스트-이미지 생성 모델과 달리,
비디오 생성에 최적화된 Diffusion Transformer 및 VAE 기반 압축 모델을 사용합니다.
📌 Sora 모델 구조
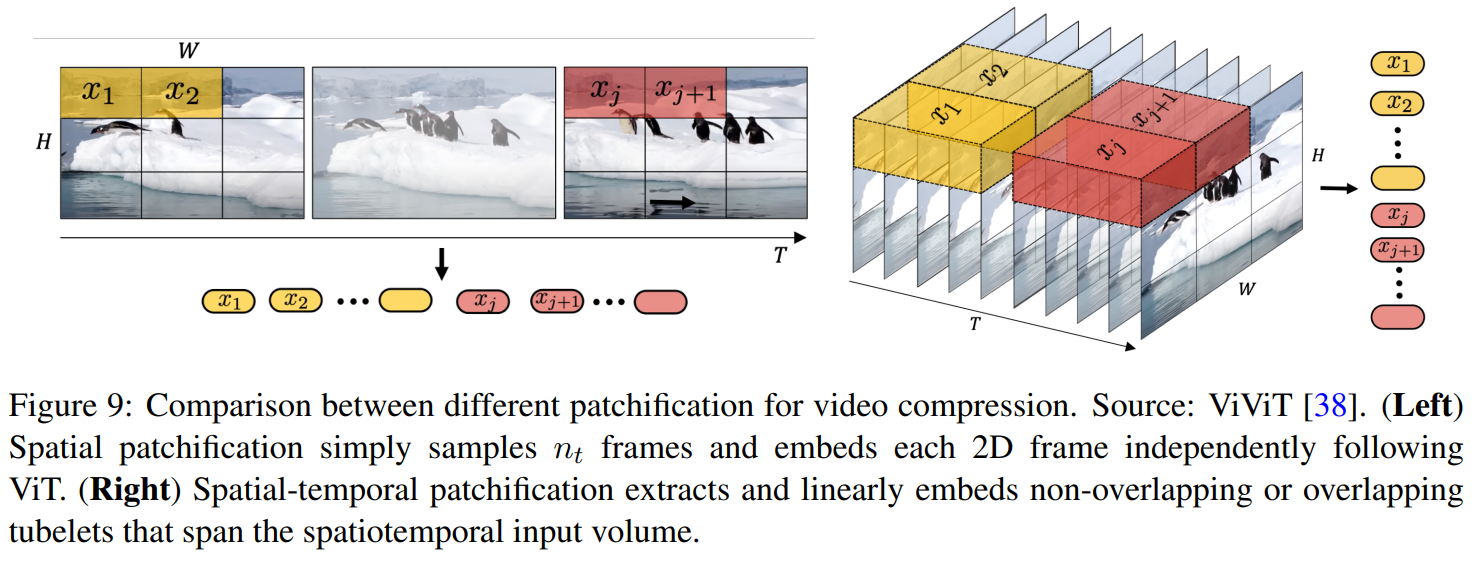
- 비디오 압축 네트워크 (VAE 기반)
- 원본 비디오 데이터를 저차원(latent space)으로 변환하여 학습 효율 향상
- 고해상도 비디오를 처리할 수 있도록 메모리 최적화
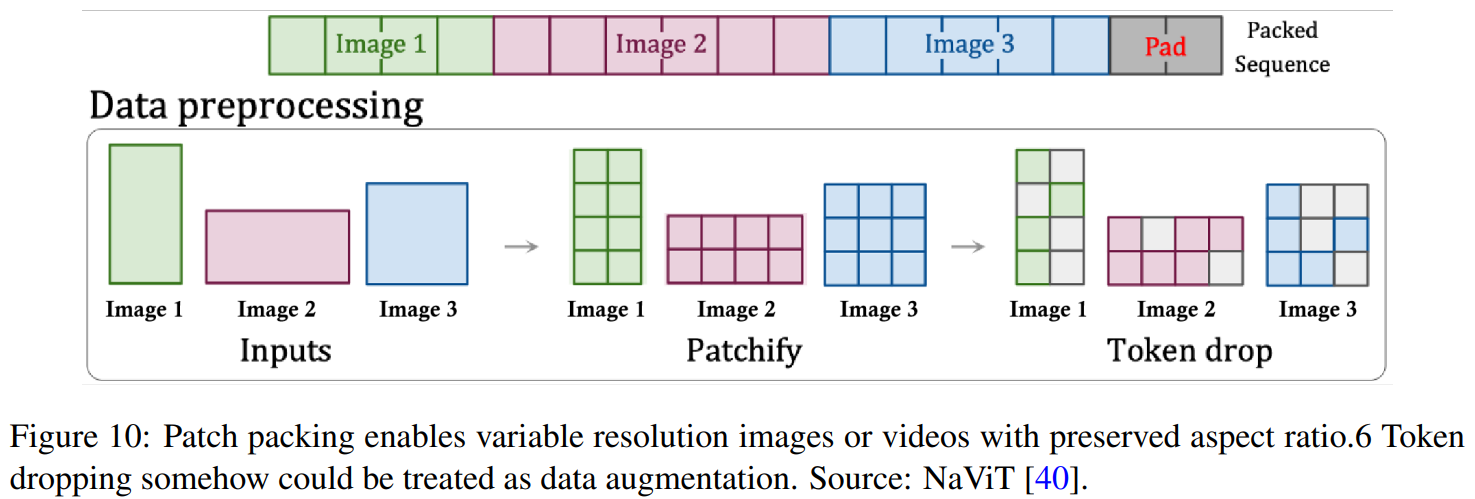
- Spacetime Latent Patches
- 비디오를 작은 공간-시간 단위의 패치(patch)로 변환하여 효율적으로 학습
- Diffusion Transformer가 장시간의 비디오 데이터를 효과적으로 학습 가능
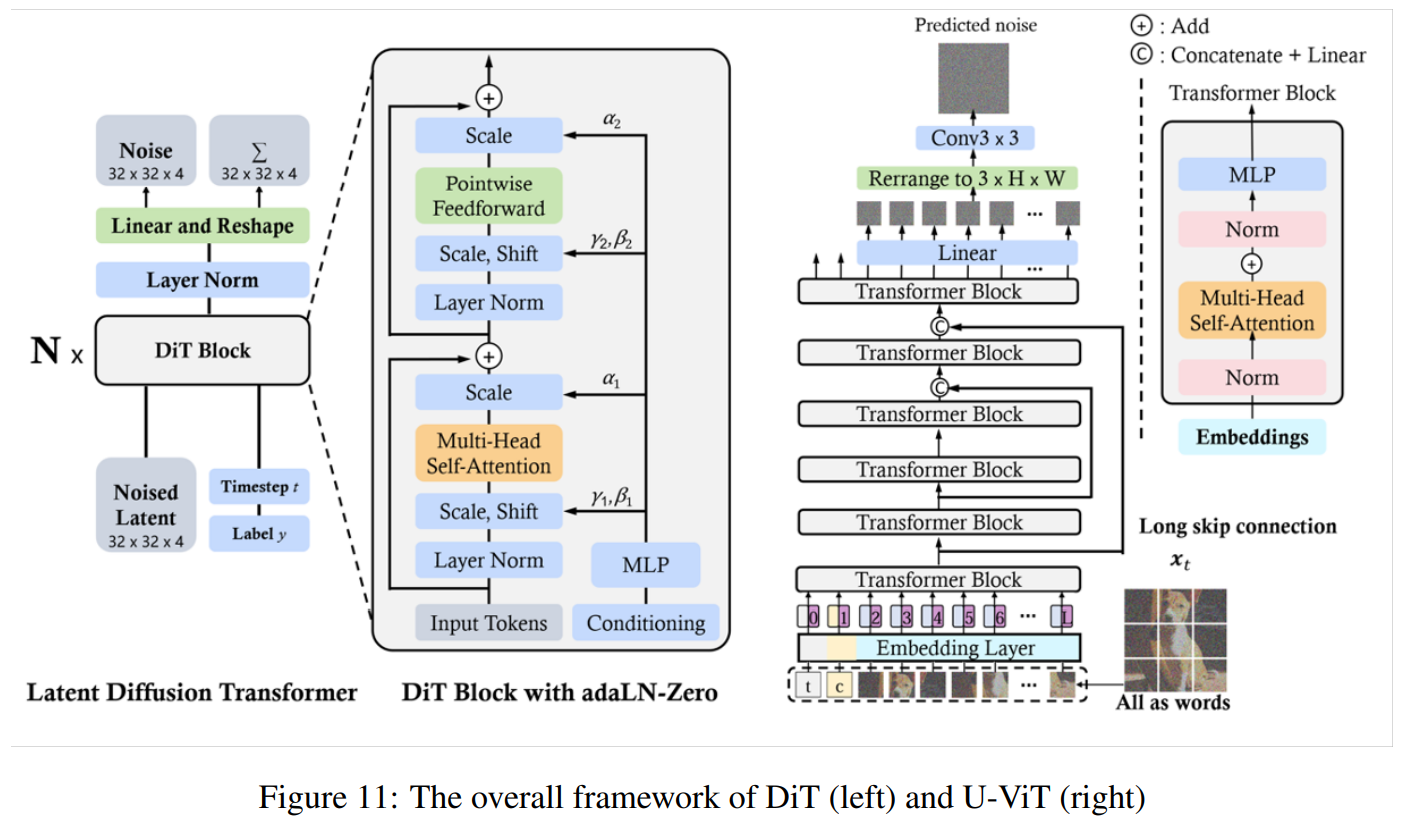
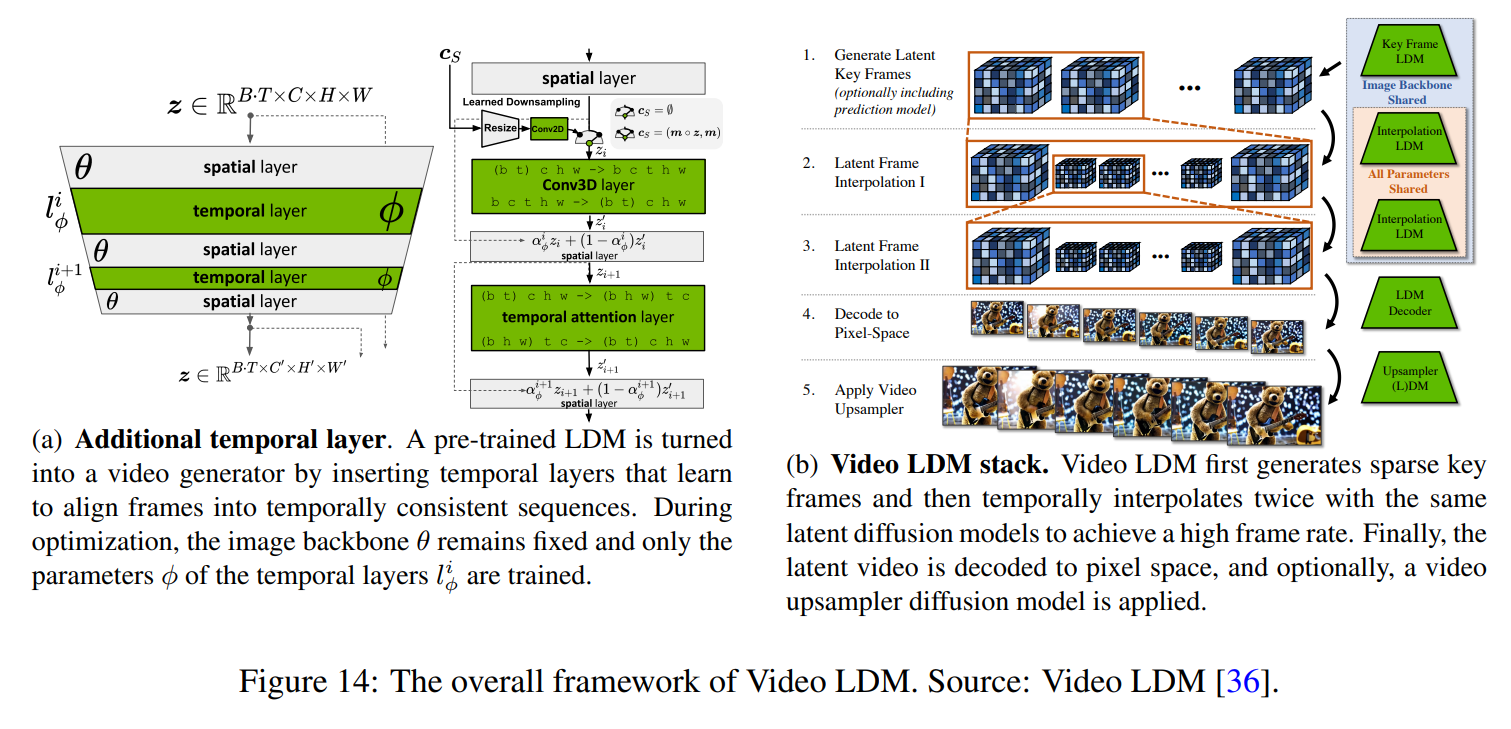
- Transformer 기반 Diffusion 모델 (Diffusion Transformer)
- 기존 U-Net 기반 Diffusion 모델이 아니라 Transformer 기반 디퓨전 모델 적용
- 멀티모달 학습 가능 (텍스트 + 비디오 + 이미지 결합 학습)
3️⃣ 학습 방법: 데이터셋 및 강화 학습 기법
📂 학습 데이터셋
| 데이터 출처 | 설명 |
|---|---|
| 인터넷 비디오 데이터셋 | 유튜브, 영화, 다큐멘터리, 시뮬레이션 영상 |
| 합성 데이터 (Synthetic Data) | AI 생성 비디오, 애니메이션, 게임 엔진 시뮬레이션 |
| 물리 시뮬레이션 데이터 | 물체의 움직임을 반영한 물리 기반 비디오 |
🏋️ 강화 학습 및 최적화 기법
- Reinforcement Learning with Human Feedback (RLHF)
- 사용자의 피드백을 받아 학습 강화
- 텍스트 입력과 실제 생성 영상 간의 일관성 유지
- Noise Schedule Optimization
- 디퓨전 과정에서 최적의 노이즈 감소 방식 적용
- 비디오 프레임 간의 연속성 유지
🔥 Sora의 한계점 및 해결 방안
1️⃣ 물리적 일관성 부족
- 물체가 공중에 떠 있거나, 비현실적인 움직임이 발생
- 해결 방안: 물리 기반 시뮬레이션 데이터 추가 학습
2️⃣ 캐릭터 일관성 문제
- 장면 전환 시 동일 캐릭터가 다르게 보이는 문제 발생
- 해결 방안: Identity Consistency Loss 적용
3️⃣ 추론 속도 최적화 필요
- 초고해상도 비디오(4K) 생성 시 추론 시간이 매우 길어짐
- 해결 방안: MoE(Mixture of Experts) 및 LoRA 기반 최적화 적용
🎬 Sora의 활용 분야
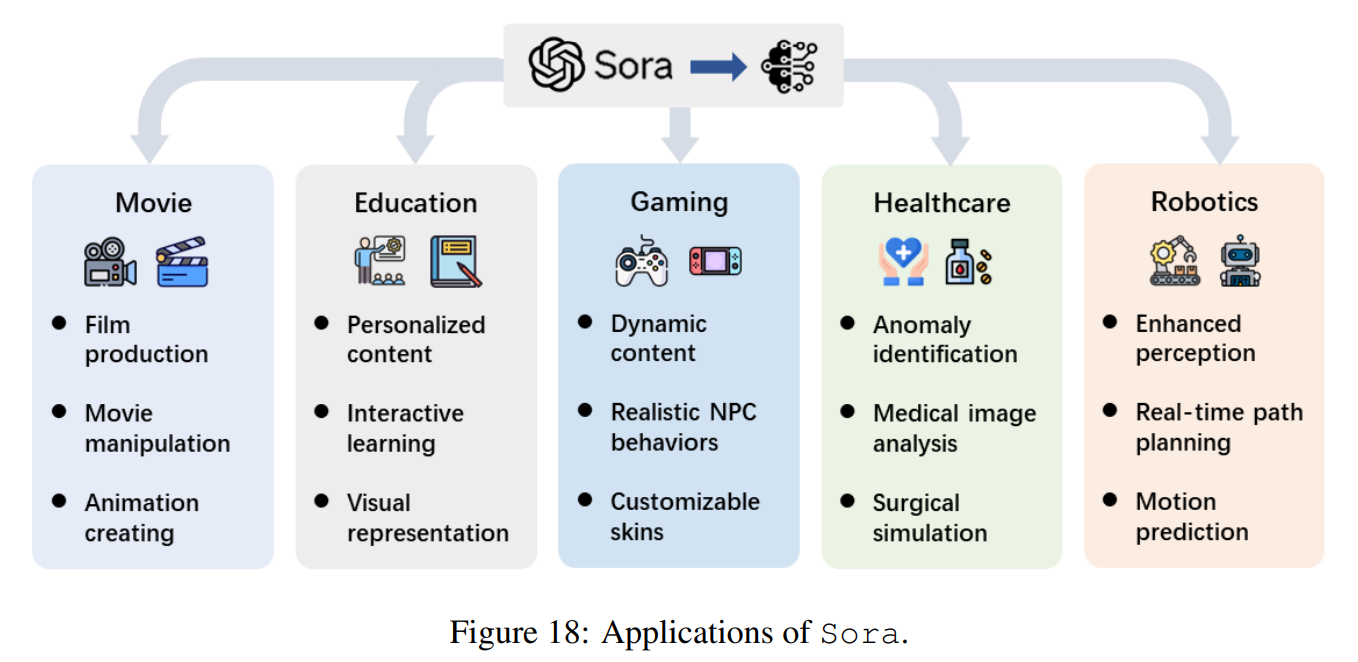
🎥 1️⃣ 영화 및 영상 콘텐츠 제작
- VFX 자동화 및 스토리보드 → 비디오 자동 생성 가능
🎓 2️⃣ 교육 및 시뮬레이션
- AI 강의 자료 → 애니메이션 자동 변환 가능
- 역사적 사건을 시각적으로 재현
🎮 3️⃣ 게임 개발 및 메타버스
- 캐릭터 애니메이션 자동 생성
- 메타버스 환경 시뮬레이션
🔮 미래 전망
- 더 긴 영상 생성 가능성 (5~10분 이상)
- 3D 모델링 및 AI 시뮬레이션 결합 가능성
- 실시간 비디오 생성 최적화 연구 진행 가능성
🏆 결론
Sora는 비디오 생성 AI의 새로운 패러다임을 제시하는 모델입니다.
향후 더 정밀한 AI 학습 최적화 및 물리적 시뮬레이션 강화가 필요할 것으로 보입니다.
This post is licensed under CC BY 4.0 by the author.