Replicate 끄적이기
인공지능 모델 배포의 두 가지 어려움
최근에 개인이나 회사에서 인공지능 모델을 배포하는 작업이 점점 더 중요해지고 있는 추세다. 하지만 인공지능 모델을 배포하려면 크게 두 가지 문제에 직면하게 된다.
1) GPU를 대여 혹은 구매하기에는 돈이 부족하다.
2) 빠르고 효율적으로 배포 개발하고 싶다.
일반적으로는 AWS나 다른 클라우드 호스팅 서비스를 이용하여 GPU를 대여하고, 시간당 비용을 지불하는 방식을 선택한다. 하지만 돈이 없는 개인 개발자나 빠르게 시장 검증을 위한 프로덕션을 만드는 팀에게는 이런 시스템이 부담스럽다.
이런 문제를 해결하기 위해, 사람들은 대부분 AWS Lambda와 비슷한 결제 구조를 가진 GPU 클라우드 호스팅 서비스를 원하고 있다. 즉, 사용한 만큼만 비용이 발생하는 시스템을 찾고 있는 것이다.
그래서 이런 요구에 맞춰서, Replicate라는 서비스가 등장했다. 이 서비스는 사용자가 사용한 만큼만 비용을 지불하는, 매우 유연한 결제 시스템을 제공한다. 이로써, 개발자들은 자신의 예산 내에서 인공지능 모델을 효과적으로 배포할 수 있게 됐다.
‘Replicate’는 GPU 호스팅을 지원하는 클라우드 플랫폼으로, 다른 사용자가 만든 API를 활용하거나, 직접 API를 쉽게 구축하여 사용할 수 있는 플랫폼이다. 사용 시에는 요금이 부과되지만, 로컬 환경에서 충분히 검증한 후에 배포하면 적절하게 활용할 수 있다.
Replicate 입문
Replicate를 활용하면, 다른 사람들이 만든 기능을 접속해볼 수 있는 화면을 확인할 수 있다.
Playground: 웹 상에서 직접 코드를 실행하고 결과를 확인할 수 있는 기능이다. 이를 통해 실시간으로 모델의 동작을 시뮬레이션해 볼 수 있다.
API: Replicate는 사용자에게 API 호출을 위한 코드를 제공한다.
Examples: Replicate는 API를 만든 사람이 다양한 예제 코드를 공유할 수 있다.
위의 3가지 기능만 알면, 자신의 계정 키를 통해 쉽게 Replicate를 사용해볼 수 있다. 하지만 한번만 사용해도 요금이 청구되니, 이 점을 주의해야한다.
Replicate 금액 시스템
Replicate의 금액 시스템도 한번 알아보자.
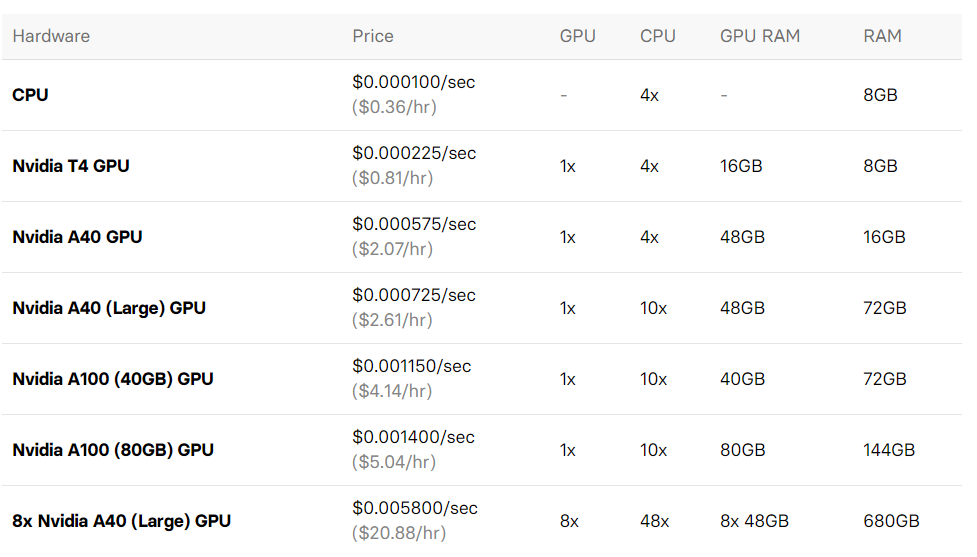
위 표는 2024년 2월 1일 기준의 금액 테이블이다. 나는 대략적으로 Replicate에서 서비스를 몇 번 이용해본 결과, Diffusion 기반 모델들은 Nvidia A40 GPU(Large)로 10초 정도 소요되었던 것으로 기억한다.
Replicate 라이프사이클 이해하기
아쉽게도 Replicate는 내가 만든 API나 다른 사람이 만든 API가 항상 동작 중인 상태는 아니다. 시스템은 크게 4가지 단계로 구성되어 있다.
Offine: 아무도 사용하지 않으면 컴퓨터(도커 인스턴스)를 꺼놓는다.
Booting: 접속이 들어오면 컴퓨터(도커 인스턴스)를 킨다. 이때 많은 시간이 소요되지만 돈은 지불되지 않는다.
Active: 동작 중인 상태다. 이 동작이 끝나기 10초 내로 다른 요청이 들어오는 경우, Active 상태를 유지한다.
Idle: Active 상태에서 10초 내로 다른 요청이 없을 시, Offline으로 넘어간다.
여기서 가장 큰 문제는 모든 요청에 대해서 빠르게 서비스를 할 수 없다는 것이다. 이 점을 고려하여 Replicate를 사용할 때는 시간과 비용을 잘 계산해야 한다.
이러한 문제를 위해 따로 배포를 위한 서비스도 제공하지만 Booting과 Idle을 진행하는 시간에도 금액이 소비된다는 문제점이 있다.
나만의 Replicate 모델 배포하기
Replicate의 가장 큰 장점 중 하나는, 남의 것만을 사용하는 것이 아니라 자신의 코드를 쉽게 배포할 수 있다는 점이다.
Replicate는 도커 시스템을 패키징하여, 자체적으로 만든 오픈소스인 COG 포맷에 맞추어 환경 설정과 추론 코드를 작성하면, 아주 손쉽게 코드 배포를 진행할 수 있다.
Highlight
📦 Docker containers without the pain. Writing your own Dockerfile can be a bewildering process. With Cog, you define your environment with a simple configuration file and it generates a Docker image with all the best practices: Nvidia base images, efficient caching of dependencies, installing specific Python versions, sensible environment variable defaults, and so on.
🤬️ No more CUDA hell. Cog knows which CUDA/cuDNN/PyTorch/Tensorflow/Python combos are compatible and will set it all up correctly for you.
✅ Define the inputs and outputs for your model with standard Python. Then, Cog generates an OpenAPI schema and validates the inputs and outputs with Pydantic.
🎁 Automatic HTTP prediction server: Your model’s types are used to dynamically generate a RESTful HTTP API using FastAPI.
🥞 Automatic queue worker. Long-running deep learning models or batch processing is best architected with a queue. Cog models do this out of the box. Redis is currently supported, with more in the pipeline.
☁️ Cloud storage. Files can be read and written directly to Amazon S3 and Google Cloud Storage. (Coming soon.)
🚀 Ready for production. Deploy your model anywhere that Docker images run. Your own infrastructure, or Replicate.
환경 설정을 위한 cog.yaml 설정 예시
‘cog.yaml’ 파일을 통해 환경 설정을 할 수 있다. 아래는 그 예시다.
1
2
3
4
5
6
7
8
9
build:
gpu: true
system_packages:
- "libgl1-mesa-glx"
- "libglib2.0-0"
python_version: "3.11"
python_packages:
- "torch==1.8.1"
predict: "predict.py:Predictor"
이 설정 파일은 도커나 다양한 환경 파일을 파이썬으로 작성해본 사람이라면 쉽게 이해할 수 있을 것이다.
‘build’ 항목에서는 GPU 사용 여부, 필요한 시스템 패키지, 사용할 파이썬 버전, 파이썬 패키지 등을 설정하고, ‘predict’ 항목에서는 예측을 수행할 파이썬 파일과 클래스를 지정한다.
이렇게 설정 파일을 작성하면, Replicate는 이 파일을 기반으로 적절한 환경을 구축하고 동작시킨다.
추론 프로세스를 위한 predict.py 설정 예시
‘predict.py’ 파일을 통해 추론 프로세스를 설정할 수 있다. 아래는 그 예시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from cog import BasePredictor, Input, Path
import torch
class Predictor(BasePredictor):
def setup(self):
"""Load the model into memory to make running multiple predictions efficient"""
self.model = torch.load("./weights.pth")
# The arguments and types the model takes as input
def predict(self,
image: Path = Input(description="Grayscale input image")
) -> Path:
"""Run a single prediction on the model"""
processed_image = preprocess(image)
output = self.model(processed_image)
return postprocess(output)
이 코드는 ‘cog’ 라이브러리의 ‘BasePredictor’ 클래스를 상속받아서, ‘setup’ 메소드와 ‘predict’ 메소드를 재정의한다.
‘setup’ 메소드에서는 모델을 메모리에 로드하고, ‘predict’ 메소드에서는 입력으로 받은 이미지를 전처리하고, 모델에 통과시킨 후, 후처리를 통해 최종 결과를 반환한다.
이렇게 설정 파일을 작성하면, Replicate는 이 파일을 기반으로 예측 작업을 수행한다.
파일구조는 대략 아래와 같다. (너무 간편하지만 도커를 빌드하고 컨테이너를 실행하는 시간에 대한 효율성을 잘 고려해서 코드를 작성하자.)
1
2
3
weights.pth
predict.py
cog.yaml
로컬에서 테스트
로컬에서는 아래의 명령어를 통해 테스트를 진행할 수 있다.
1
2
3
4
$ cog predict -i image=@input.jpg
--> Building Docker image...
--> Running Prediction...
--> Output written to output.jpg
빌드 및 배포 테스트
빌드 및 배포 테스트는 아래의 명령어를 통해 진행할 수 있다.
1
2
3
4
5
6
7
8
9
$ cog build -t my-colorization-model
--> Building Docker image...
--> Built my-colorization-model:latest
$ docker run -d -p 5000:5000 --gpus all my-colorization-model
$ curl http://localhost:5000/predictions -X POST \
-H 'Content-Type: application/json' \
-d '{"input": {"image": "https://.../input.jpg"}}'
Replicate에 배포하기
Replicate에 모델을 배포하기 위해서는 아래의 순서를 따른다.
1) Replicate에 로그인한다.
2) Dashboard로 이동한다.
3) ‘Models’ 메뉴로 이동한다.
4) ‘Create a new model’ 버튼을 클릭한다.
- 모델의 ‘Name’을 작성한다.
- ‘Hardware’를 선택한다.
- ‘What kind of model are you planning to create?’ 항목에서 ‘Custom Cog model’을 선택한다.
5) 이후에는 로컬에서 아래의 명령어를 통해 로그인하고, 모델을 push한다.
1
2
cog login
cog push r8.im/[user name]/[model name]
이렇게 하면 Replicate에 모델이 배포된다.