RAFT 훑어보기
- 논문: RAFT: Adapting Language Model to Domain Specific RAG
- 저자: Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
- 소속: UC Berkeley
- 코드: https://github.com/ShishirPatil/gorilla
🔍 RAFT란?
RAFT(Retrieval-Augmented Fine-Tuning)는 LLM을 도메인 특화 RAG(Retrieval-Augmented Generation) 환경에 최적화하는 새로운 학습 방법입니다.
기존 LLM은 범용적인 정보에는 강하지만, 특정 도메인(예: 의학, 법률, 엔터프라이즈 문서)에서 정확하고 신뢰할 수 있는 정보 검색 및 답변 생성이 어려운 한계가 있었습니다.
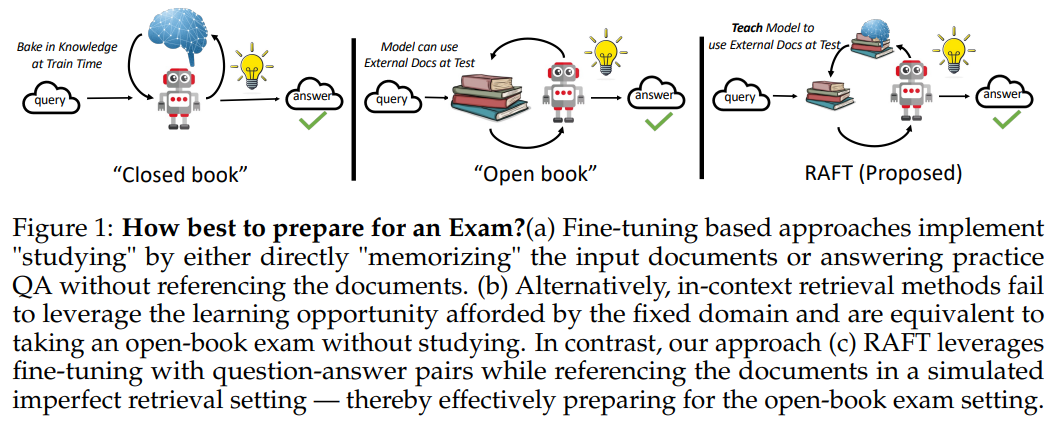
RAFT는 Fine-Tuning과 RAG의 장점을 결합하여 LLM이 신뢰할 수 있는 문서만을 활용하도록 학습하는 새로운 방법론입니다.
🏆 RAFT의 주요 기여
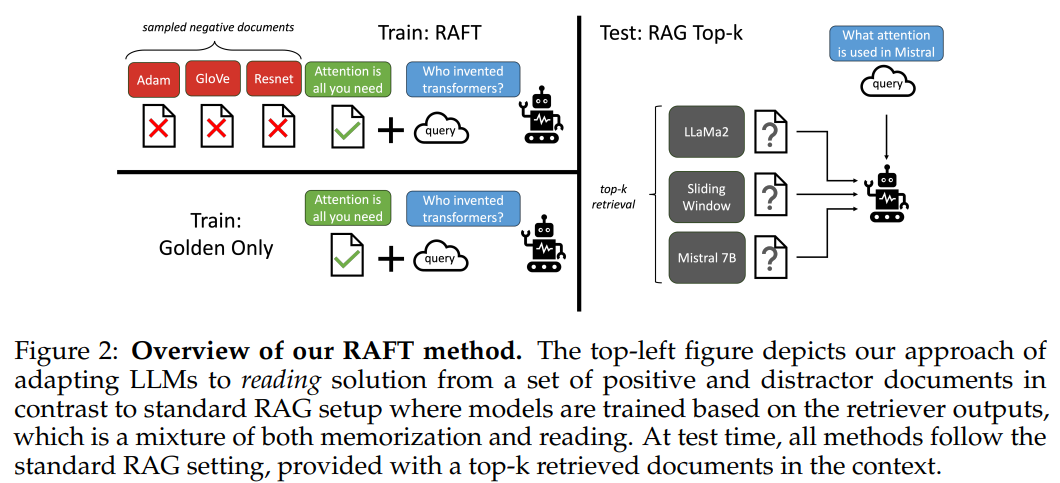
- Distractor 문서 필터링
- 검색된 문서 중 정답이 포함되지 않은 문서(잡음)를 무시하는 능력을 학습
- Chain-of-Thought(연쇄 추론) 적용
- 단순한 정답 생성이 아니라 단계별 추론 과정을 학습하여 신뢰성 향상
- RAG 학습을 위한 새로운 데이터 구성
- 일부 질문에는 정답이 포함된 문서 + 혼동되는 문서 제공
- 일부 질문에는 정답이 없는 문서만 제공하여 모델이 혼동을 줄이도록 설계
- 다양한 데이터셋에서 성능 향상
- PubMed, HotpotQA, Gorilla API Bench 등에서 기존 Fine-Tuning 기법 대비 높은 성능 달성
🤔 기존 Fine-Tuning과 RAG의 한계
기존 Fine-Tuning의 문제점
- 모델이 학습 데이터에 포함된 내용만 암기하는 경향
- 새로운 데이터가 추가되면 일반화가 어렵고 업데이트 비용이 큼
기존 RAG(Retrieval-Augmented Generation)의 문제점
- 검색된 문서를 그대로 사용하기 때문에 잘못된 문서(Distractor) 포함 가능성
- 모델이 신뢰할 수 있는 정보를 선택하는 능력이 부족
💡 RAFT는 이 두 가지 문제를 해결하는 새로운 접근법을 제안합니다.
📚 RAFT 학습 방법
1️⃣ RAFT의 데이터 구성
RAFT는 훈련 데이터를 구성할 때 의도적으로 잘못된 문서(Distractor)를 포함하여 모델이 적절한 정보를 선택할 수 있도록 학습합니다.
🔹 RAFT 훈련 데이터 구성
- P%의 데이터:
- (Q) 질문 + (D) 정답이 포함된 문서 + (D1, D2, …, Dk) Distractor 문서 → A (정답)
- (1-P)%의 데이터:
- (Q) 질문 + (D1, D2, …, Dk) Distractor 문서만 제공 → A* (정답 없음)
📌 이 방식의 장점
✔ 모델이 신뢰할 수 있는 문서를 스스로 필터링하는 법을 학습
✔ 잘못된 정보를 배제하고 정확한 정보만 활용하는 능력 향상
2️⃣ Chain-of-Thought(CoT) 적용
RAFT는 단순한 정답 제공이 아니라, 단계별 논리를 포함한 답변을 생성하도록 학습합니다.
🔹 예시 (HotPotQA 데이터셋)
질문: “Evolution” 영화를 집필한 각본가는 누구인가?
문서:
- “David Weissman은 ‘The Family Man’(2000), ‘Evolution’(2001), ‘When in Rome’(2010)을 집필함”
- “‘The Family Man’은 David Diamond와 David Weissman이 각본을 맡음”
RAFT 답변:
- ”##이유: 문서 ##begin_quote## ‘David Weissman은 Evolution을 집필’ ##end_quote##이 포함됨. 따라서, Evolution의 각본가는 David Weissman임.
- ##정답: David Weissman”
📌 이 방식의 장점
✔ 모델이 정확한 문서를 참조하는지 검증 가능
✔ 정답을 도출하는 과정을 명확히 설명 가능
📊 실험 결과
RAFT는 다양한 데이터셋에서 기존 Fine-Tuning 및 RAG 기반 방법보다 높은 성능을 보였습니다.
| 모델 | PubMed | HotPotQA | HuggingFace | Torch Hub | TensorFlow Hub |
|---|---|---|---|---|---|
| GPT-3.5 + RAG | 71.6 | 41.5 | 29.08 | 60.21 | 65.59 |
| LLaMA2-7B + RAG | 58.8 | 0.03 | 26.43 | 08.60 | 43.06 |
| Domain-Specific Fine-Tuning(DSF) + RAG | 71.6 | 4.41 | 42.59 | 82.80 | 60.29 |
| RAFT (LLaMA2-7B) | 73.3 | 35.28 | 74.00 | 84.95 | 86.86 |
📌 주요 결과
✔ HotPotQA 성능 +30.87% 증가
✔ HuggingFace 성능 +31.41% 증가
✔ Torch Hub 성능 +76.35% 증가
🔥 결론: RAFT의 미래
💡 왜 RAFT가 중요한가?
✔ 기존 Fine-Tuning과 RAG 기반 방법의 한계를 극복
✔ 도메인 특화 검색 환경에서 강력한 성능 향상
✔ 오픈북 시험 같은 RAG 환경에서도 정답을 잘 도출하는 모델을 학습 가능
🛠️ 향후 연구 방향
- 더 정교한 Distractor 문서 생성 방법 개발
- Multi-hop Reasoning(다중 단계 추론) 성능 향상
- 실시간 RAG 환경에서도 적용 가능하도록 최적화 연구