OmniParser: GUI 자동화를 위한 순수 비전 기반 에이전트
OmniParser: GUI 자동화를 위한 순수 비전 기반 에이전트
- 📖 논문: https://arxiv.org/abs/2408.00203v1
- 🖥️ 깃허브: https://github.com/microsoft/OmniParser
- 🤖 프로젝트: https://microsoft.github.io/OmniParser/
🔍 연구 기관: Microsoft Research, Microsoft Gen AI
✍️ 저자: Yadong Lu, Jianwei Yang, Yelong Shen, Ahmed Awadallah
📅 논문 발표: 2025년 2월 12일
🎯 OmniParser란?
OmniParser는 GUI(그래픽 사용자 인터페이스) 자동화를 위한 최첨단 AI 모델입니다.
최근 GPT-4V와 같은 대형 비전-언어 모델(VLM, Vision-Language Models)이 등장하면서 GUI 에이전트의 가능성이 확대되었지만, 기존 모델들은 GUI 요소를 신뢰성 있게 인식하고, 실제 동작을 수행하는 문제에서 어려움이 있었습니다.
OmniParser는 이러한 문제를 해결하기 위해 UI 스크린샷을 해석하고, 액션을 실행할 수 있도록 GUI 정보를 구조화된 데이터로 변환하는 기술을 제공합니다. 이를 통해 GPT-4V 및 기타 비전-언어 모델(VLM)이 실제 애플리케이션과 상호작용할 수 있도록 지원합니다.
🔹 OmniParser를 활용하면:
✔️ 웹, 모바일, 데스크톱 GUI 자동화 가능
✔️ AI가 UI를 이해하고 버튼을 클릭하거나 텍스트 입력 수행 가능
✔️ GPT-4V, LLaMA-3, Phi-3.5-V 등 다양한 비전-언어 모델과 결합 가능
🔥 OmniParser의 핵심 기술
1️⃣ 인터랙티브 UI 요소 감지 (Interactable Region Detection)
✅ UI에서 버튼, 아이콘, 입력 필드 등의 상호작용 가능한 요소를 감지하여 바운딩 박스(Bounding Box)로 제공합니다.
✅ YOLO 기반 감지 모델을 활용하여 웹, 모바일, 데스크톱 환경에서 DOM 트리 정보 없이 UI 요소를 탐지합니다.
✅ 67K+ 개의 UI 스크린샷을 학습 데이터로 활용하여 모델의 정밀도를 극대화하였습니다.
2️⃣ 로컬 의미 분석 (Local Semantics Analysis)
✅ 단순한 위치 정보뿐만 아니라 아이콘 및 버튼의 기능을 설명하여 GPT-4V와 같은 LLM이 UI를 정확히 이해하도록 지원합니다.
✅ GPT-4o를 활용한 7K+ 개의 아이콘-설명 데이터셋을 구축하고 BLIP-2 모델을 학습하여 기능 설명을 자동 생성합니다.
✅ OCR(광학 문자 인식) 기능을 포함하여 UI의 텍스트 요소도 분석합니다.
3️⃣ 순수 비전 기반 UI 분석
✅ 기존 연구들은 웹 브라우저의 DOM 트리 정보를 활용했지만, 이는 모바일 앱 및 데스크톱 애플리케이션에서는 사용이 불가능합니다.
✅ OmniParser는 HTML 없이도 완전한 비전 기반 UI 분석이 가능하여 다양한 운영체제 및 애플리케이션에서 활용할 수 있습니다.
🔍 기존 GPT-4V 기반 UI 에이전트와 OmniParser의 차이점
| 주요 기능 | 기존 GPT-4V | OmniParser + GPT-4V |
|---|---|---|
| UI 요소 좌표 예측 | 정확한 (x, y) 좌표 예측 불가 | Bounding Box 기반 ID 예측 |
| 로컬 문맥 이해 | 제한적 | 아이콘 기능 설명 추가 |
| HTML 의존성 | DOM 정보 필요 | 완전한 비전 기반 |
| 지원 플랫폼 | 웹 브라우저 중심 | 웹, 모바일, 데스크톱 모두 지원 |
📊 벤치마크 성능 평가
OmniParser는 ScreenSpot, Mind2Web, AITW 등 다양한 GUI 자동화 관련 벤치마크에서 성능을 검증하였습니다.
🔹 ScreenSpot 벤치마크 결과 (아이콘/위젯 인식 정확도)

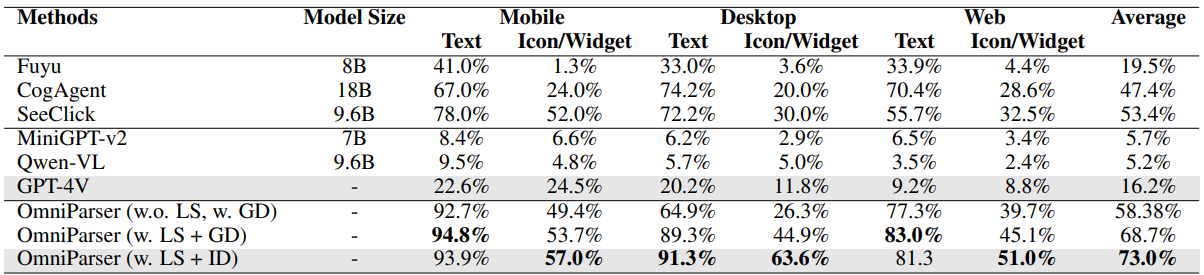
📌 OmniParser는 기존 GPT-4V 대비 평균 56.8% 성능 향상
🔹 Mind2Web 벤치마크 결과 (웹 탐색 정확도)
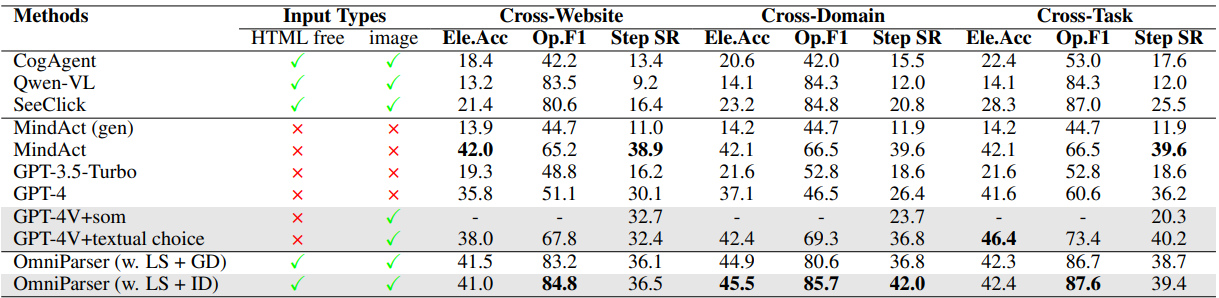
📌 HTML 정보를 사용하지 않고도 GPT-4V 대비 웹 탐색 성능이 6~8% 향상
🔹 AITW 벤치마크 결과 (GUI 자동화 정확도)

📌 OmniParser는 GPT-4V 대비 AITW 벤치마크에서 4.7% 향상된 전체 성능을 기록
🖥️ 실제 사용 사례 (Demo & Use Cases)
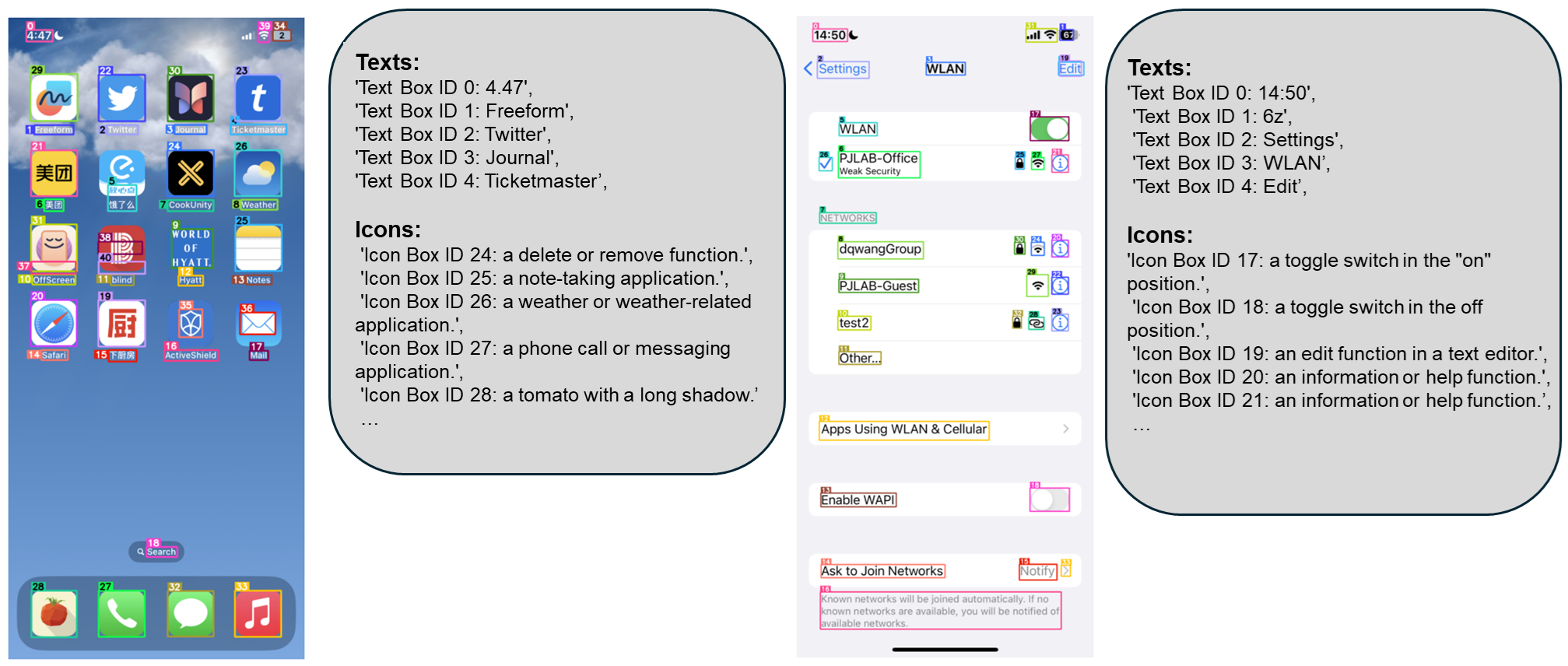
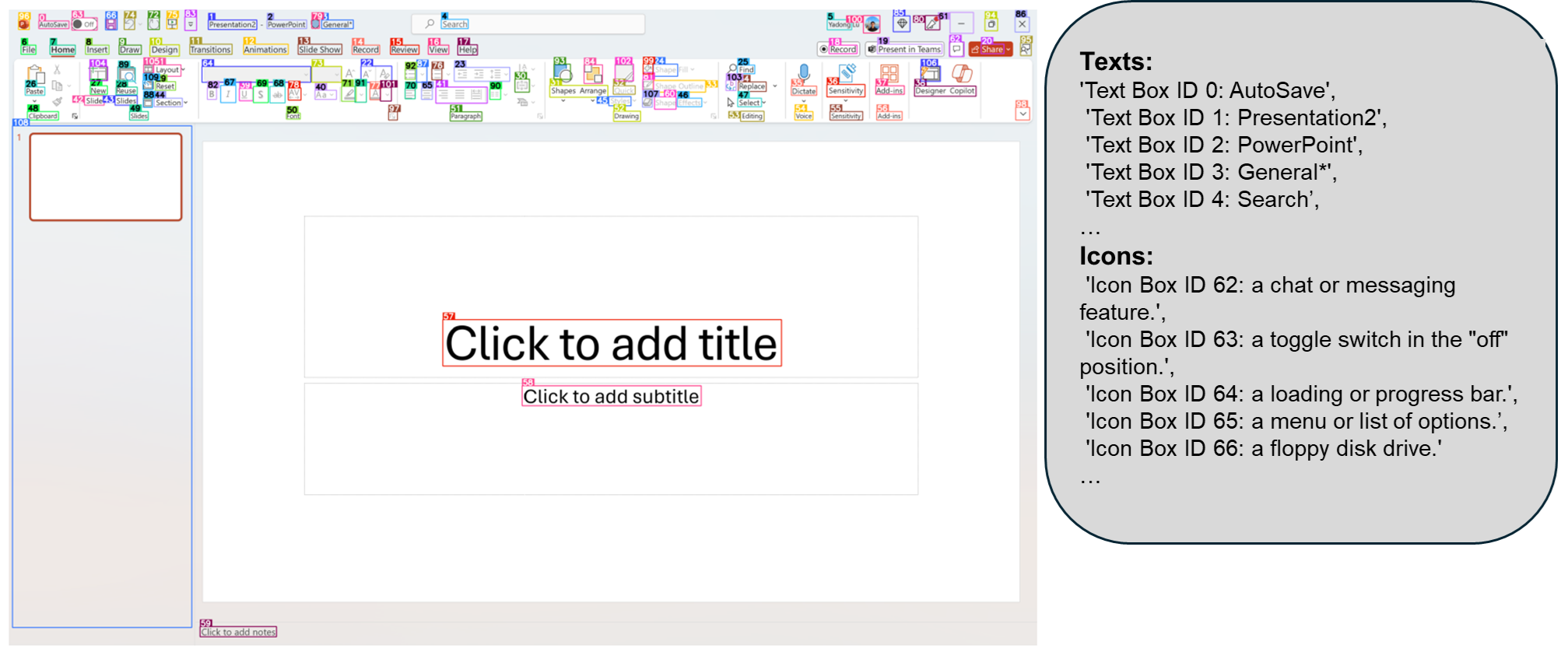
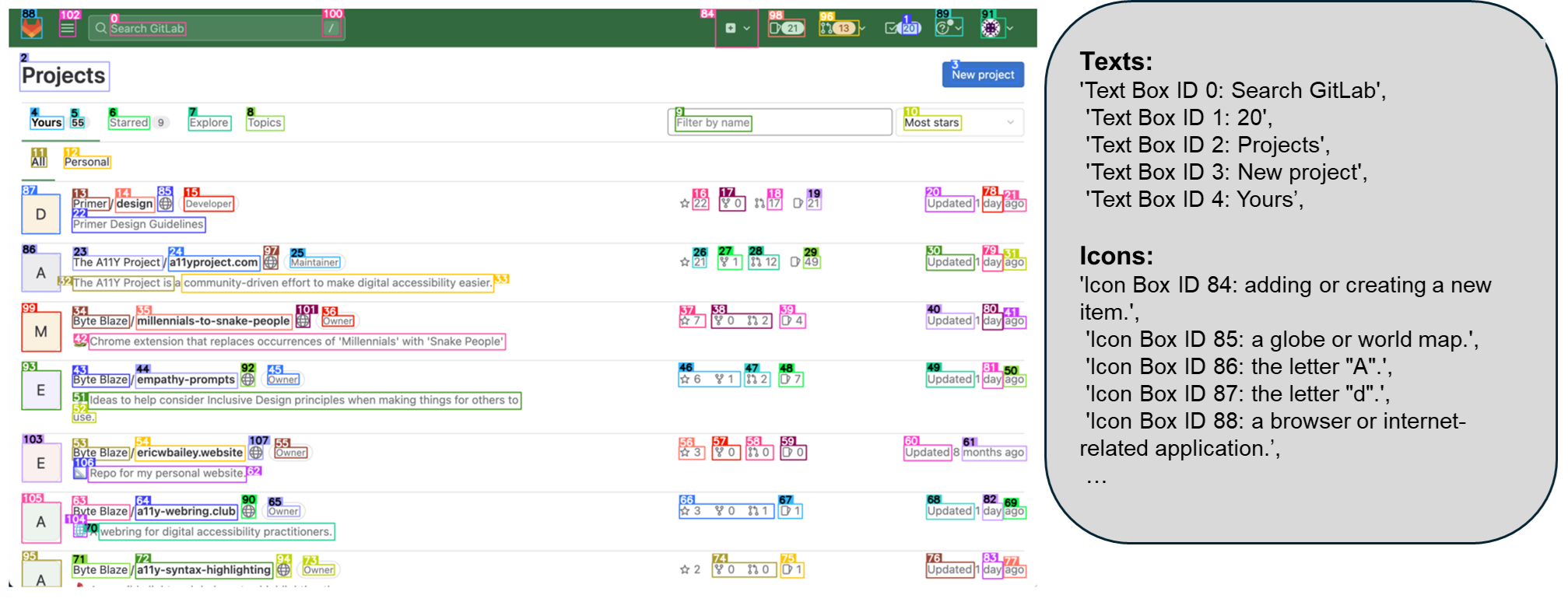
1️⃣ GUI 자동화 및 원격 조작
💡 “설정에서 Wi-Fi를 켜줘”
✅ OmniParser는 설정 화면에서 Wi-Fi 버튼을 인식
✅ 해당 버튼을 선택하고 활성화하는 액션을 실행
2️⃣ 웹 탐색 자동화
💡 “Amazon에서 노트북을 검색해줘”
✅ 검색창을 인식하고 “노트북” 입력
✅ 검색 버튼을 클릭하여 결과 페이지 이동
3️⃣ 앱 내 내비게이션 자동화
💡 “Gmail에서 새 이메일을 작성해줘”
✅ OmniParser는 Gmail UI에서 “작성하기” 버튼을 찾아 클릭
✅ 이메일 입력창을 선택하고 사용자 입력을 기다림
📌 결론: GUI 에이전트가 실제로 사용자의 명령을 이해하고, 자동으로 실행하는 단계로 발전하고 있습니다.
🛠️ 설치 및 사용법
![]()
📌 기본 환경 설정
1
2
3
4
cd OmniParser
conda create -n "omni" python==3.12
conda activate omni
pip install -r requirements.txt
📌 모델 다운로드
1
2
3
# download the model checkpoints to local directory OmniParser/weights/
for f in icon_detect/{train_args.yaml,model.pt,model.yaml} icon_caption/{config.json,generation_config.json,model.safetensors}; do huggingface-cli download microsoft/OmniParser-v2.0 "$f" --local-dir weights; done
mv weights/icon_caption weights/icon_caption_florence
📌 추론(Inference) 코드 예제
1
python gradio_demo.py
🔮 향후 발전 방향
1️⃣ 반복 요소 문제 해결
- 동일한 아이콘이 여러 개 존재할 경우 혼동 발생
- 위치 정보 추가하여 모델이 올바른 요소를 선택하도록 개선 예정
2️⃣ 바운딩 박스 예측 정밀도 향상
- OCR이 넓은 영역을 인식하는 문제 해결
- OCR과 UI 요소 감지 모델을 통합하여 학습 예정
3️⃣ 아이콘 문맥 이해 강화
- 같은 아이콘이라도 UI 문맥에 따라 의미가 달라질 수 있음
- 전체 화면 문맥을 고려하는 아이콘 설명 모델 개선 예정
🎯 결론
OmniParser는 HTML 없이 UI를 분석할 수 있는 강력한 순수 비전 기반 모델로, GPT-4V 등의 대형 모델과 결합 시 기존 모델 대비 20~60% 성능 향상을 제공합니다.
✅ 웹, 모바일, 데스크톱을 모두 지원하는 범용 UI 이해 모델
✅ 인터랙티브 요소 감지 + 로컬 의미 분석을 통한 문맥 이해 강화
✅ LLM의 UI 인식 및 액션 예측 성능을 극대화
📢 미래의 AI 에이전트는 더욱 정교하게 UI를 이해할 것입니다. OmniParser가 그 시작점이 될 것입니다! 🚀