Pytorch Multi GPU 잘써보자
Pytorch Multi GPU
요즘 단일 GPU로 학습시킬 수 있는 모델이 없을 정도로 모델 복잡도, 데이터 크기가 엄청나게 방대하다.. 그래서 대부분 Multi GPU를 사용하는데 어떻게 잘써야하는지는 알기 어렵다.
처음 Multi GPU를 사용하는 방법에 대해 설명해주는 좋은 자료는 많았지만 내가 쉽게 읽기 위해 여태 읽었던 글들을 바탕으로 Pytorch Multi GPU 꿀팁을 정리해보자
목적은 무엇이냐??
- GPU 메모리를 절약 -> Batch Size를 늘리자
- GPU 학습을 가속화하자
DataLoader Parameter
DataLoader를 사용하다보면 헷갈리는 부분이 두가지 있다.
- num_workers 몇으로 해야하지?
- pin_memory는 뭐하는거지?
num_workers 몇으로 해야하지?
num_workers는 무엇을 하는걸까??
간단하게 설명하면 데이터 로드할 때 몇개의 프로세스를 사용할래요? 라는 파라미터 이다.
위에 사이트는 num_workers를 몇으로해야 좋을지에 대한 토의를 하는 포스트인데 실험상 가장 좋았던 공식은 num_workers = 4 * num_of_gpus 라고 한다.
요즘은 CPU 코어수가 많으니 이 공식이 실용적이라고 한다.
하지만 너무 많은 num_workers를 할당하면 심각한 오버헤드가 발생하고 그렇다고 너무 적으면 좋은 성능을 기대하지 못한다.(즉, CPU와 GPU의 밸런스를 중요시 한다.)
하나하나 늘려서 해볼 시간이 없으므로 num_workers = 4 * num_of_gpus 이렇게 fix하자!
1
2
3
4
5
6
# code
import torch
num_workers = 4 * torch.cuda.device_count()
pin_memory를 왜 True로 해야 하는 것인가?
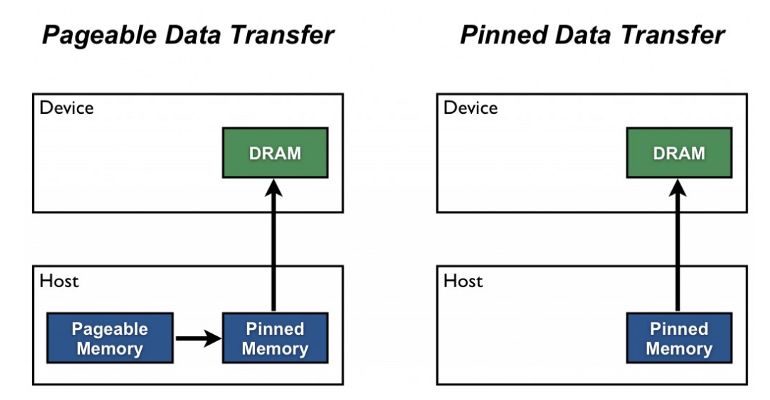
위에 그림은 NVIDIA blogpost에 언급되는 그림이다.
pin_memory는 위에 그림처럼 GPU에서 호스트에서 디바이스로 전송을 위한 staging area이고 pinned memory와 pageable memory의 전송 비용을 줄이기 위해 데이터를 pin memory에 고정시켜 전송하는 방법이다.
간단하게, 미리 불러놓고 학습한다는 의미이다. 그니까 큰 무리가 없다면 pin_memory=True로 고정하자
AMP
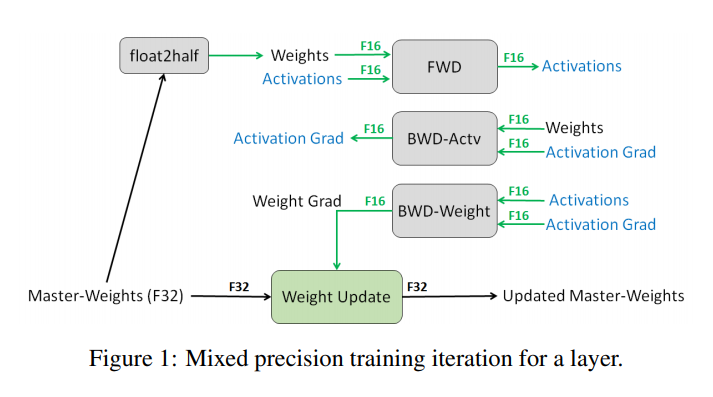
AMP(Automatic Mixed Precision)은 논문에 제안 된 알고리즘이다.
AMP는 우리가 딥러닝 연산을 할 때 부동 소수점 32bit 연산을 진행하는데 이를 16bit로 줄여서 연산하자는 아이디어다. 위에 그림이 설명을 다해준다.. loss scaler나 자세한 사항은 다른 분들이 잘 설명해 주셔서 생략한다.
기존에는 amp 라이브러리를 따로 설치해야 했는데 pytorch 1.6 version 부터 내장 함수로 지원해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import torch
scaler = torch.cuda.amp.GradScaler()
for i, (inputs, labels) in enumerate(loader):
self.optimizer.zero_grad()
with torch.cuda.amp.autocast(): # cast mixed precision
outputs = self.model(inputs)
loss = self.criterion(outputs, labels)
self.scaler.scale(loss).backward() # scaled gradients
self.scaler.step(self.optimizer) # unscaled gradients
self.scaler.update() # scaled update
너무 간단하다 !
이를 사용하면서 얻는 이득은 32bit -> 16bit로 줄이기에 메모리 사용량이 줄어들어 배치 크기를 늘릴수 있다. 성능은 오히려 더 좋아질 수도 있다는게 장점이다.
nn.DataParallel -> nn.DistributedDataParallel
크게 문제가 없어서 항상 nn.DataParallel을 사용하다가 실제 대용량의 데이터를 처리하는 작업을 하다보니.. 문제가 많다고 느껴져서 nn.DistributedDataParallel로 변경했다.
nn.DataParallel은 배치를 자동으로 쪼개주고 0번 gpu로 모든 연산된 값을 하나로 모으는데 처음에 작은 데이터를 사용하면 큰 문제가 없지만 모델 복잡도가 큰 모델이나 대용량 데이터를 처리하다보면 불균형이 너무 심해져서 Multi GPU의 장점을 확실하게 살릴 수 없다.
그래서 대부분 블로그는 nn.DistributedDataParallel을 권장한다. 코드는 nn.DataParallel 보다 복잡하지만 성능은 확실하다.
1
nn.DataParallel(model)
이게 끝이었던 코드가 조금 늘어날 뿐이다. 아래 코드는 이 곳에서 영감을 받았다.
- Github에서 확인 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
import torch
def setup(rank, world_size):
# initialize the process group
dist.init_process_group(
backend='nccl',
init_method='tcp://127.0.0.1:3456',
world_size=world_size,
rank=rank)
def cleanup():
dist.destroy_process_group()
def main():
n_gpus = torch.cuda.device_count()
torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus, ))
def main_worker(gpu, n_gpus):
image_size = 224
batch_size = 512
num_worker = 8
epochs = ...
batch_size = int(batch_size / n_gpus) # 각 GPU에 들어가니까 쪼개서 넣자
num_worker = int(num_worker / n_gpus) # 각 GPU에 들어가니까 쪼개서 넣자
torch.distributed.init_process_group(
backend='nccl',
init_method='tcp://127.0.0.1:3456',
world_size=n_gpus,
rank=gpu)
model = [YOUR MODEL]
torch.cuda.set_device(gpu)
model = model.cuda(gpu)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
dist.barrier()
if cfg['load_path']:
map_location = {'cuda:%d' % 0: 'cuda:%d' % gpu}
model.load_state_dict(torch.load(cfg['load_path'], map_location=map_location))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_datasets)
train_loader = torch.utils.data.DataLoader(... , shuffle=False, sampler=train_sampler)
optimizer = [YOUR OPTIMIZER]
criterion = [YOUR CRITERION]
for epoch in range(epochs):
train()
valid()
if gpu == 0:
save()
if __name__ == "__main__":
main()
정리하면 각 GPU에 데이터를 쪼개서 각각 동일한 조건으로 학습 되는 코드이다.
GPU 한개당 처리해줄 작업을 정의한다고 생각하면 이해가 편할 것이다.
모델을 저장하는 부분은 0번째 gpu에서만 모델을 저장하도록 처리했다. 만약 그렇게 처리하지 않으면 여러 프로세스에서 모델을 저장하기 때문에 로드가 안될 수도 있다..
모델을 로드하는 부분은 모든 프로세스에 모델을 로드하도록 작성했다.
dist.barrier(group): group 내의 모든 프로세스가 이 함수에 진입할 때까지 group 내의 모든 프로세스를 block 합니다.