Diffusion 톺아보기
인공지능을 공부하는 방법은 다양하지만, 저는 지금까지
1) Demo를 활용하여 인공지능을 체험하고,
2) 논문과 Github 코드를 함께 분석하면서,
3) 지속적으로 학습하고 반복하는
방식으로 많은 것을 배웠습니다.
이번 글에서는 Diffusion을 알아보도록 합시다.
Diffusion
Diffusion은 생성 모델입니다. 기존에 알고 있던 생성 방법과는 완전히 다릅니다. Diffusion은 이미지 생성, 이미지 노이즈 제거 등 다양한 생성 태스크에서 사용될 수 있습니다.
아래 그림은 Diffusion의 동작 방식을 잘 설명해주는 그림입니다.
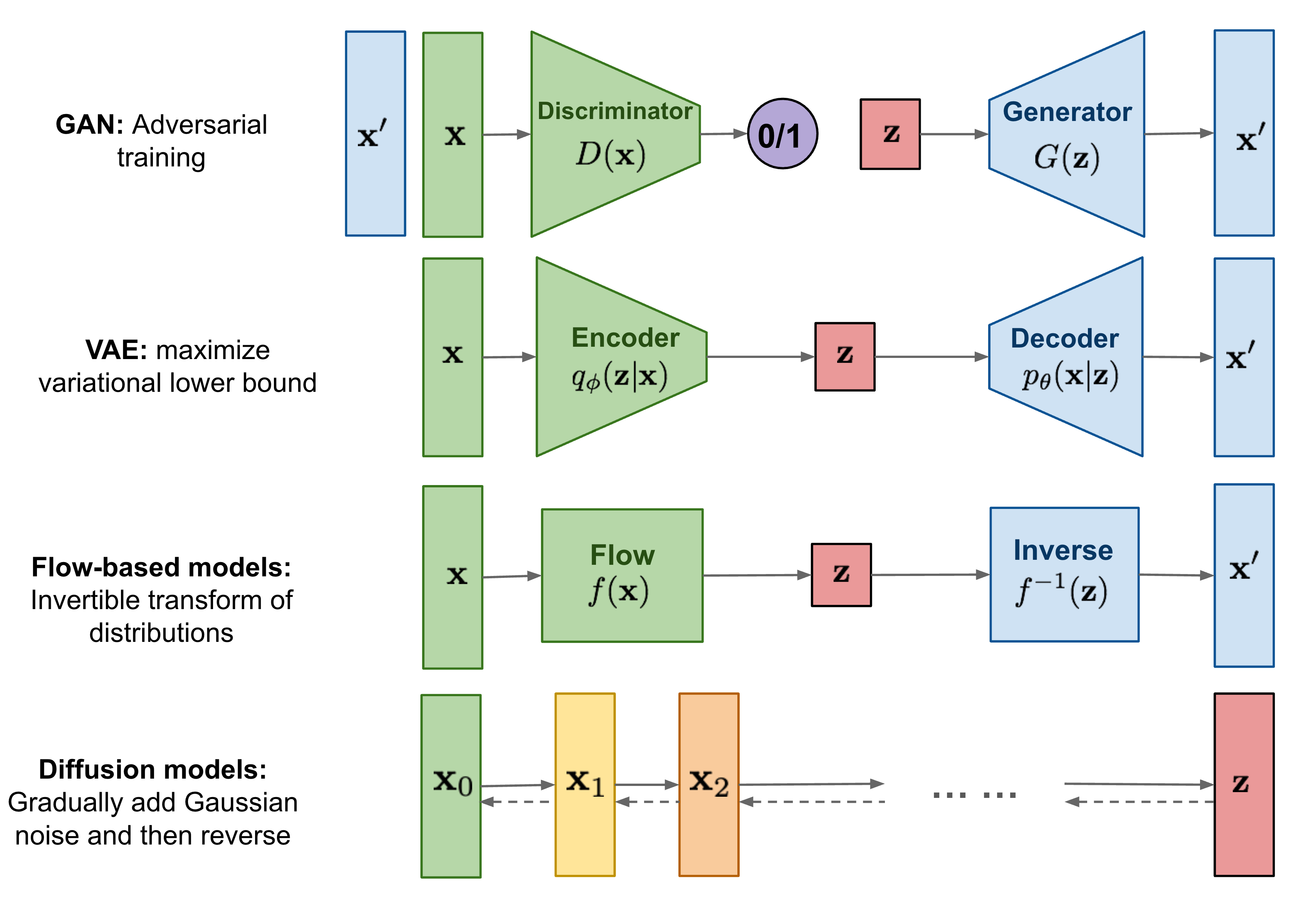
Diffusion은 확산이라는 뜻을 가지고 있습니다. 이는 흩어져 번지는 것이라는 의미를 가지고 있습니다.
아래 그림을 보면 Gradually add Gaussian noise and then reverse라고 적혀있습니다. 이는 점진적으로 가우시안 노이즈를 추가하고, 다시 이를 복원하는 작업을 하는 알고리즘입니다. 가우시안 노이즈를 점진적으로 추가한다는 것은 어떤 의미일까요?
가우시안 노이즈(Gaussian Noise)는 정규분포를 따르는 노이즈로, 실세계에서 발생하는 규칙이 없는 잡음을 모사합니다. 이를 이미지에 점진적으로 추가한다면, 점차적으로 노이즈가 증가하면서 이미지가 흐려지고 더 많은 정보를 잃어버리게 됩니다.
따라서 Diffusion은 이미지를 생성할 때, 가우시안 노이즈를 점진적으로 추가하여 이미지를 점차적으로 흐리게 만든 뒤, 이를 역으로 추적하여 노이즈를 제거하면서 원본 이미지를 생성하는 방식으로 작동합니다.

가우시안 노이즈를 점진적으로 추가한 이미지는 인간의 눈으로는 형태를 알아볼 수 없는 노이즈 형태가 됩니다. 하지만 여기에 인공지능 모델을 사용한다면 이러한 노이즈를 이용하여 이미지를 생성할 수 있습니다. 이때 인공지능 모델은 이미지의 특징을 파악하고, 노이즈를 제거하고 이미지를 복원하는 역할을 수행합니다. 이렇게 생성된 이미지는 노이즈가 제거된 고품질의 이미지가 됩니다. Diffusion은 이러한 방식으로 이미지를 생성하는 생성 모델 중 하나입니다.
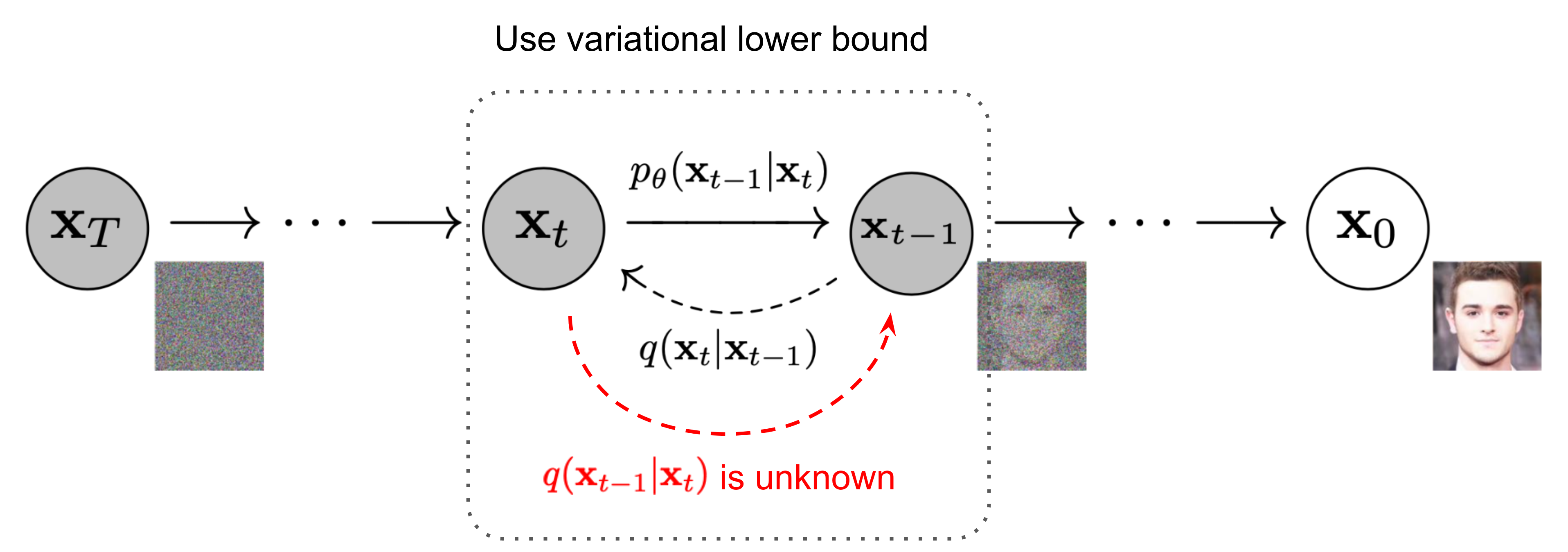
노이즈를 지워내는 방법을 학습하면 됩니다.
수식이 갑자기 등장했지만 당황하지않고 하나하나씩 꺼내서 풀어내봅시다.
\(x_{0}\) : 이미지
\(x_{t}\) : 가우시안 노이즈를 \(t\) 만큼 추가한 이미지 \(T\) 까지 반복한다는 의미
\(q(x_{t} \| x_{t-1}) : x_{t-1}\) 에 가우시안 노이즈를 추가하여 \(x_{t}\) 를 만들어낸다는 의미
\(p_{\theta} (x_{t-1} \| x_{t}) : x_{t}\) 의 노이즈를 지워내서 \(x_{t-1}\) 를 만들어내며 \(\theta\) 값을 가지는 인공지능 모델을 통해 진행한다는 의미
위에 \(q\)와 \(p\)는 코드와 수식을 통하여 한번 알아보도록 하면 좋을 것 같습니다.
DDPM(Denoising Diffusion Probabilistic Models)
복잡한 수식을 풀어내는 글은 찾아보시면 많기 때문에, 깊게 공부하고 싶으신 분들은 다른 문서들을 참조하시면 좋을 것 같습니다. 저는 실제로 어떻게 사용하는지에 관심이 많아 코드를 주로 읽는 것을 선호합니다.
Code: Here
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
def extract(a, t, x_shape):
"""
broadcasting을 위해서 shape을 맞추어 주는 함수 입니다.
"""
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
class GaussianDiffusion(nn.Module):
__doc__ = r"""Gaussian Diffusion model. Forwarding through the module returns diffusion reversal scalar loss tensor.
Input:
x: tensor of shape (N, img_channels, *img_size)
y: tensor of shape (N)
Output:
scalar loss tensor
Args:
model (nn.Module): model which estimates diffusion noise
img_size (tuple): image size tuple (H, W)
img_channels (int): number of image channels
betas (np.ndarray): numpy array of diffusion betas
loss_type (string): loss type, "l1" or "l2"
ema_decay (float): model weights exponential moving average decay
ema_start (int): number of steps before EMA
ema_update_rate (int): number of steps before each EMA update
"""
def __init__(
self,
model,
img_size,
img_channels,
num_classes,
betas,
loss_type="l2",
ema_decay=0.9999,
ema_start=5000,
ema_update_rate=1,
):
super().__init__()
self.model = model
self.ema_model = deepcopy(model)
self.ema = EMA(ema_decay)
self.ema_decay = ema_decay
self.ema_start = ema_start
self.ema_update_rate = ema_update_rate
self.step = 0
self.img_size = img_size
self.img_channels = img_channels
self.num_classes = num_classes
if loss_type not in ["l1", "l2"]:
raise ValueError("__init__() got unknown loss type")
self.loss_type = loss_type
self.num_timesteps = len(betas)
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas)
to_torch = partial(torch.tensor, dtype=torch.float32)
self.register_buffer("betas", to_torch(betas))
self.register_buffer("alphas", to_torch(alphas))
self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))
self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))
self.register_buffer("sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1 - alphas_cumprod)))
self.register_buffer("reciprocal_sqrt_alphas", to_torch(np.sqrt(1 / alphas)))
self.register_buffer("remove_noise_coeff", to_torch(betas / np.sqrt(1 - alphas_cumprod)))
self.register_buffer("sigma", to_torch(np.sqrt(betas)))
def update_ema(self):
self.step += 1
if self.step % self.ema_update_rate == 0:
if self.step < self.ema_start:
self.ema_model.load_state_dict(self.model.state_dict())
else:
self.ema.update_model_average(self.ema_model, self.model)
@torch.no_grad()
def remove_noise(self, x, t, y, use_ema=True):
if use_ema:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.ema_model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
else:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
@torch.no_grad()
def sample(self, batch_size, device, y=None, use_ema=True):
if y is not None and batch_size != len(y):
raise ValueError("sample batch size different from length of given y")
x = torch.randn(batch_size, self.img_channels, *self.img_size, device=device)
for t in range(self.num_timesteps - 1, -1, -1):
t_batch = torch.tensor([t], device=device).repeat(batch_size)
x = self.remove_noise(x, t_batch, y, use_ema)
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
return x.cpu().detach()
@torch.no_grad()
def sample_diffusion_sequence(self, batch_size, device, y=None, use_ema=True):
if y is not None and batch_size != len(y):
raise ValueError("sample batch size different from length of given y")
x = torch.randn(batch_size, self.img_channels, *self.img_size, device=device)
diffusion_sequence = [x.cpu().detach()]
for t in range(self.num_timesteps - 1, -1, -1):
t_batch = torch.tensor([t], device=device).repeat(batch_size)
x = self.remove_noise(x, t_batch, y, use_ema)
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
diffusion_sequence.append(x.cpu().detach())
return diffusion_sequence
def perturb_x(self, x, t, noise):
return (
extract(self.sqrt_alphas_cumprod, t, x.shape) * x +
extract(self.sqrt_one_minus_alphas_cumprod, t, x.shape) * noise
)
def get_losses(self, x, t, y):
noise = torch.randn_like(x)
perturbed_x = self.perturb_x(x, t, noise)
estimated_noise = self.model(perturbed_x, t, y)
if self.loss_type == "l1":
loss = F.l1_loss(estimated_noise, noise)
elif self.loss_type == "l2":
loss = F.mse_loss(estimated_noise, noise)
return loss
def forward(self, x, y=None):
b, c, h, w = x.shape
device = x.device
if h != self.img_size[0]:
raise ValueError("image height does not match diffusion parameters")
if w != self.img_size[0]:
raise ValueError("image width does not match diffusion parameters")
t = torch.randint(0, self.num_timesteps, (b,), device=device)
return self.get_losses(x, t, y)
diffusion = GaussianDiffusion(
model, (32, 32), 3, 10,
betas,
ema_decay=args.ema_decay,
ema_update_rate=args.ema_update_rate,
ema_start=2000,
loss_type=args.loss_type,
)
위에 코드의 구성이 가장 적합한 것 같아 가져왔습니다.
어떤 입력이 있다고 생각해봅시다.
학습은 어떻게 할까요?
forward함수를 통과합니다.get_losses함수를 통과합니다.noise를 만듭니다.noise를pertub_x에 통과시켜perturbed_x를 만듭니다.perturbed_x를model에 통과시켜estimated_noise를 만듭니다.noise와estimated_noise의 손실 값을 구합니다. (노이즈를 추정해서 연산을 통해 노이즈를 제거한다는 것을 예측해볼 수 있습니다.)- 손실 값을 통해 모델을 최적화를 합니다.
- 반복합니다.
라벨을 사용한다면 어떻게 학습할까요?
Unet 모델에 Embedding Layer를 추가하여 condition 값을 생성하고 중간중간에 더해주면 되겠죠?
1
2
3
4
5
6
7
8
9
10
class Layer:
def __init__(self, num_classes, out_channels):
...
self.class_bias = nn.Embedding(num_classes, out_channels)
...
def forward(self, x, y):
...
out += self.class_bias(y)[:, :, None, None]
...
자세한 건 위에 첨부한 Github에서 확인해보시면 더 쉽게 이해하실 수 있습니다. 저는 중간중간 기억이 안날 때 빠르게 들려서 볼 수 있도록 하기 위해 생략했습니다.
학습 된 모델이 생긴다면 추론은 어떻게 할까요?
만들어낼 이미지의 정보를 포함하여 sample 함수를 통과합니다.
DDPM 정리
노이즈를 순차적으로 추가하여 완전한 노이즈로 만들어주는 과정이 diffusion process이며 이것의 역변환을 inverse process라고 합니다. DDPM은 inverse process를 딥러닝 모델을 통해 학습하는 방법입니다.
이미지 생성할 때 순차적으로 노이즈를 지워내는 과정이 있기 때문에 추론 시간이 느리다는 단점이 있습니다.
Stable Diffusion
Stable Diffusion은 “Denoising Diffusion 방법을 사용한 새로운 모델”이라는 것을 알 수 있습니다. 위에서 알아보았던 DDPM은 이미지를 생성하는 모델입니다. 반면 Stable Diffusion은 Text2Img 모델로, 다양한 Task(Img2Img, Text2Img 등)에서 높은 품질로 동작하는 모델입니다. 또한 다양한 기관들이 협력하여 Stable Diffusion과 함께 사용할 수 있는 여러 가지 프로젝트들이 지속적으로 등장하고 있습니다. 이 중에서 Stable Diffusion Web UI 프로젝트는 최신 기술들을 전부 통합한 프로젝트로 평가받고 있습니다.
Stable Diffusion을 이해하기 위해서는 먼저 Latent Diffusion을 알아야 합니다. Stable Diffusion은 Latent Diffusion을 기반으로 만들어졌기 때문입니다. Latent Diffusion은 High-Resolution Image Synthesis with Latent Diffusion Models 논문에서 제안된 기술입니다.

Latent Diffusion 모델은 위와 같은 구조를 가지고 있습니다.
Imagen
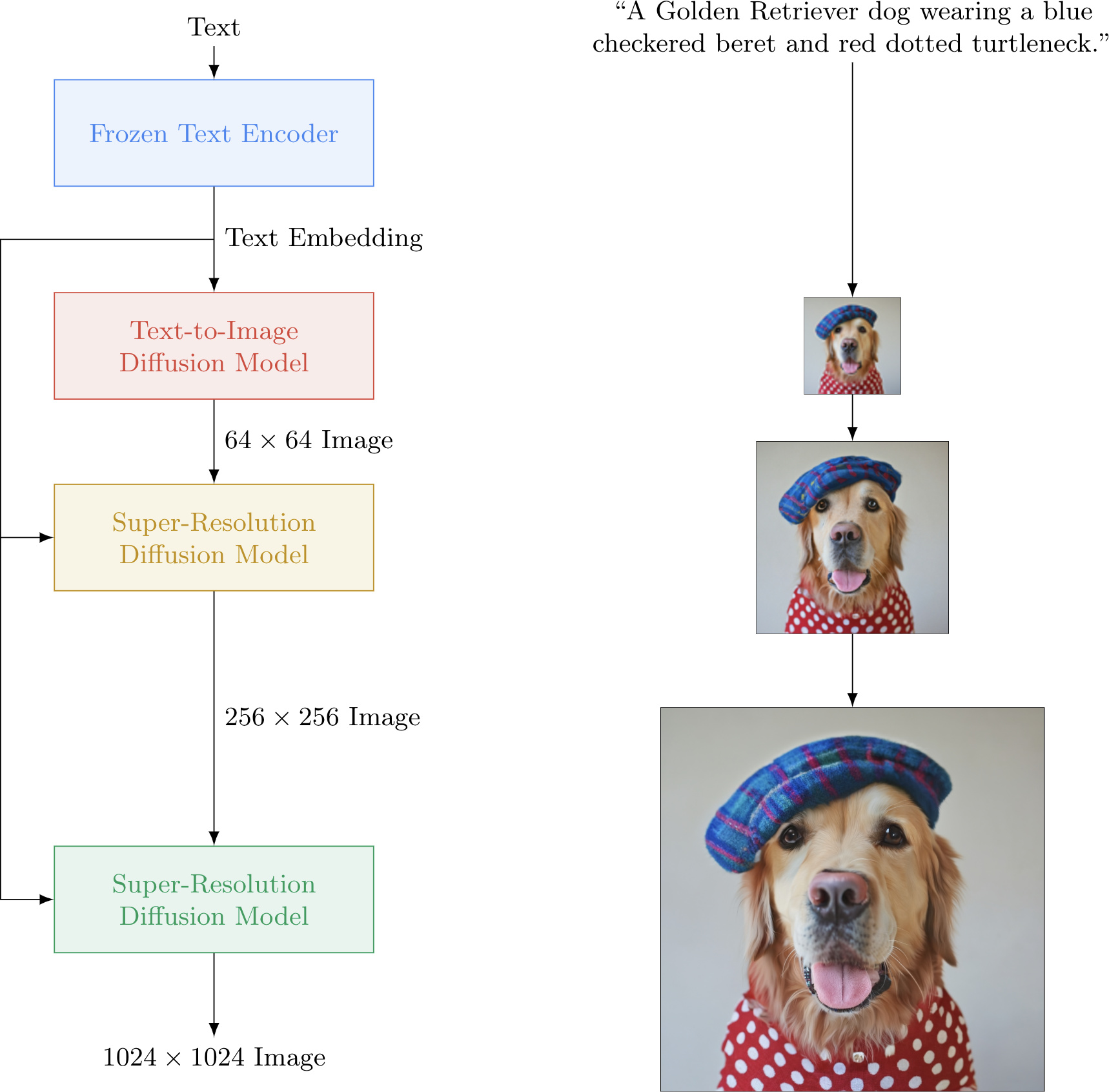
프로젝트 페이지를 보면 요약이 되어있습니다.
- 우리는 대규모 사전 훈련된 고정 텍스트 인코더가 텍스트-이미지 작업에 매우 효과적임을 보여줍니다.
- 사전 훈련된 텍스트 인코더 크기를 확장하는 것이 확산 모델 크기를 확장하는 것보다 더 중요하다는 것을 보여줍니다.
- 매우 큰 분류기 없는 가이드 가중치의 사용을 가능하게 하는 새로운 임계값 확산 샘플러를 소개합니다.
- 보다 계산 효율적이고 메모리 효율적이며 수렴 속도가 더 빠른 새로운 Efficient U-Net 아키텍처를 소개합니다.
- COCO에서 7.27의 새로운 최고 성능 COCO FID를 달성하며, 인간 평가자들은 Imagen 샘플이 이미지-텍스트 정렬 측면에서 참조 이미지와 동등함을 발견합니다.
기존 Diffusion 기술에 EfficientNet과 같은 구글의 기술을 잘 녹여낸 논문입니다.
Dreambooth

Dreambooth는 Imagen이 공개된 이후 발표된 논문입니다. 기존 Diffusion 모델은 고품질의 사실적 이미지 생성에 탁월하지만, 이미지 내부에 텍스트나 참조 이미지의 모양을 유지하지 못하는 문제가 있습니다. Dreambooth는 이를 해결하기 위해, 사용자가 제공한 이미지 개념을 이해하고 다양한 형태의 이미지를 생성할 수 있는 맞춤형 모델입니다. 기술 발전 속도가 빠르기 때문에 공부할 내용이 계속 많아지는 것은 재미있지만, 때로는 걱정이 될 수도 있습니다.
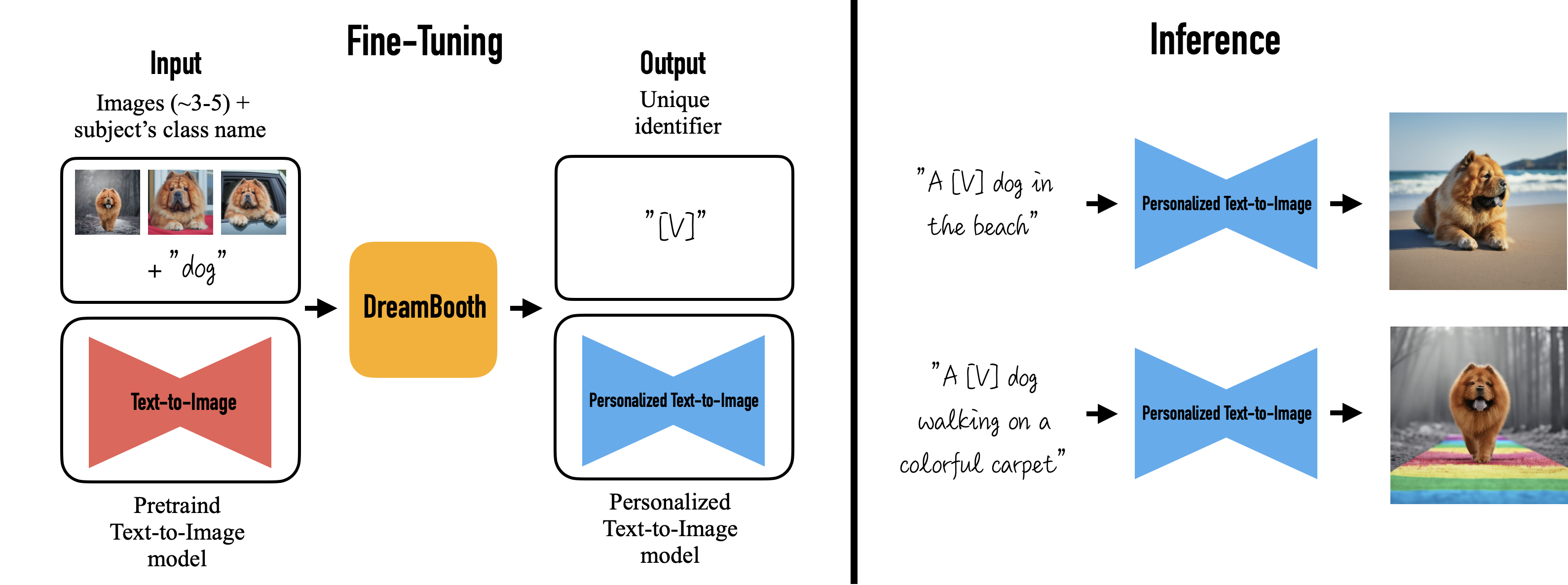
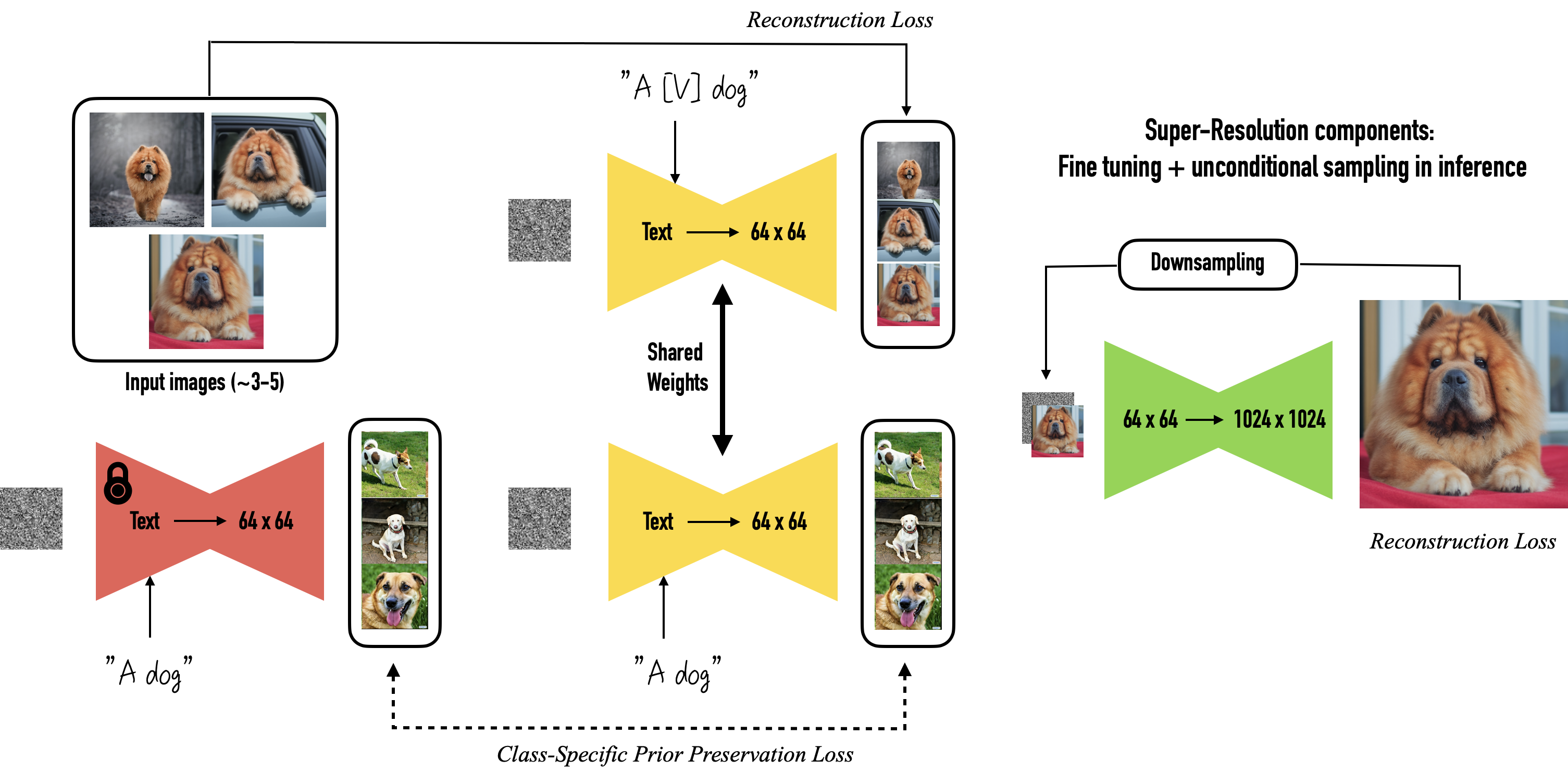
요즘 인공지능은 그림을 너무 잘 만들어내서, 그림만 봐도 무엇을 하려는지 쉽게 이해할 수 있게 되었습니다. 개인적으로 생각해보면, 인공지능 논문을 빠르게 읽고 이해하기 쉬워지는 경향이 있습니다. 하지만 논문을 이해하는 것뿐 아니라, 실제로 데이터의 흐름을 이해하고 이를 어떻게 활용하는 지가 더욱 중요하다고 생각합니다.
CLIP
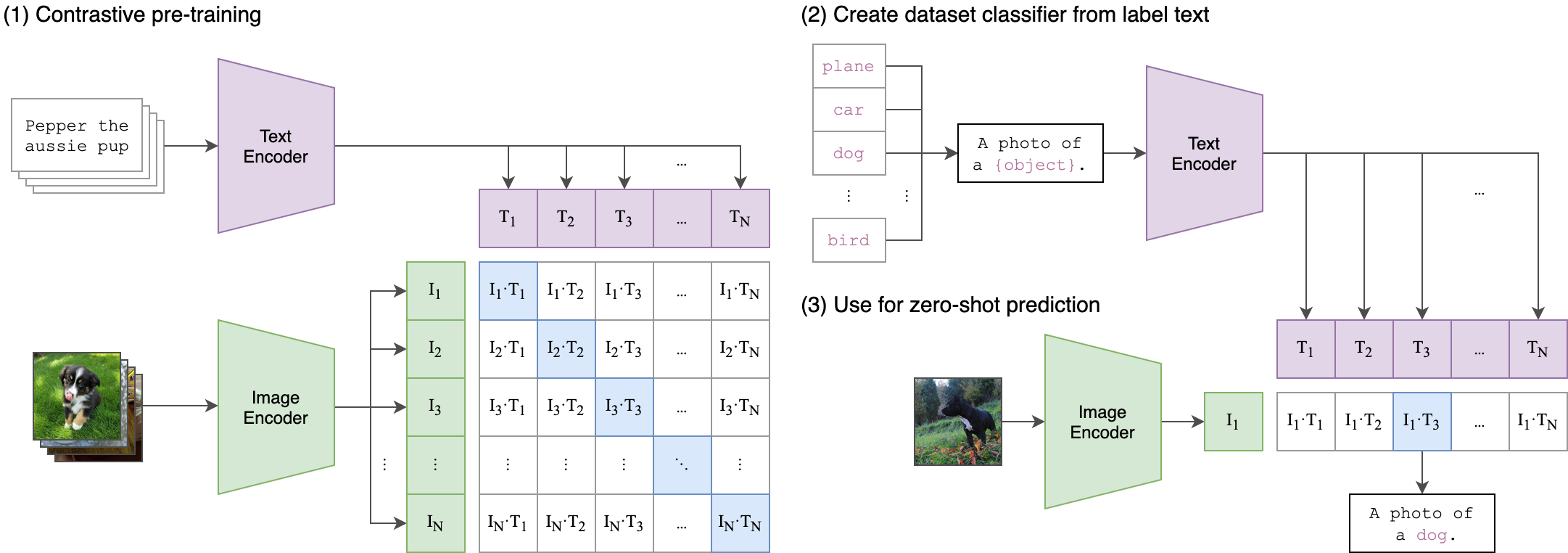
위에 자료를 보면서 함께 보면 좋을 것 같아 CLIP 그림도 첨부합니다. Text2Img 작업을 수행하기 위해서는 거의 필수로 사용되는 CLIP은 이미지와 해당 이미지에 달려있는 캡션을 연결한 데이터를 활용하여, 텍스트와 이미지의 올바른 연결 관계를 찾아내는 모델입니다. 이러한 작업은 품질 좋은 데이터가 많으면 많을수록 높은 성능을 발휘할 수 있기 때문에 학습 시간과 데이터 생성에 많은 시간이 소요됩니다. 그러나 한 번 만들어 놓으면 다양한 곳에서 활용할 수 있기 때문에, representational learning은 초반부터 수행해야 할 중요한 작업이라고 생각됩니다.
Reference
Paper
- Denoising Diffusion Probabilistic Models
- High-Resolution Image Synthesis with Latent Diffusion Models