SWE-Lancer: LLM이 실제 소프트웨어 엔지니어링으로 돈을 벌 수 있을까?
SWE-Lancer: LLM이 실제 소프트웨어 엔지니어링으로 돈을 벌 수 있을까?
- 📖 논문: https://arxiv.org/abs/2502.12115v2
- 🖥️ 깃허브: https://github.com/openai/SWELancer-Benchmark
- 🤖 프로젝트: https://github.com/openai/SWELancer-Benchmark
🔍 연구 기관: OpenAI
✍️ 저자: Samuel Miserendino, Michele Wang, Tejal Patwardhan, Johannes Heidecke
📅 논문 발표: 2025년 2월 19일
🎯 SWE-Lancer란?
SWE-Lancer는 AI가 실제 소프트웨어 엔지니어링 작업을 수행하고 돈을 벌 수 있는지 평가하는 최초의 현실적 벤치마크입니다.
🔹 기존 AI 코딩 벤치마크와의 차이점:
- 실제 프리랜서 시장(Upwork)에서 채택된 1,488개의 작업을 기반으로 평가
- 실제 개발자들이 받은 보상을 기준으로 LLM의 수익 능력 평가
- 소프트웨어 엔지니어로서의 개별 작업 수행 (IC SWE Tasks) + 기술 매니저 역할 (SWE Manager Tasks) 포함
- 단순 코드 생성이 아니라 풀스택 개발 및 의사결정 능력까지 테스트
💡 한 마디로?
LLM이 개발자로 취업하고, 실제 돈을 벌 수 있는지를 평가하는 최초의 현실적 실험!
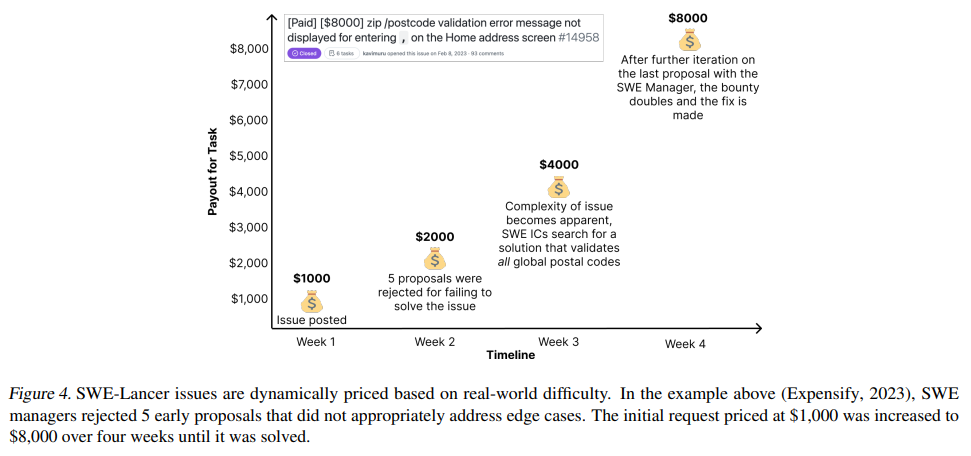
과연 잘 벌었을까?
🔥 SWE-Lancer의 핵심 기술
1️⃣ 프리랜서 개발 작업을 그대로 평가
✅ Upwork에서 실제로 진행된 1,488개의 소프트웨어 개발 작업을 데이터셋으로 사용
✅ 금액은 총 100만 달러, 개별 작업당 $50~$32,000까지 다양
✅ AI 모델이 코드를 작성하면, 실제 개발자가 만든 코드와 비교해 평가
2️⃣ 2가지 유형의 평가 방식
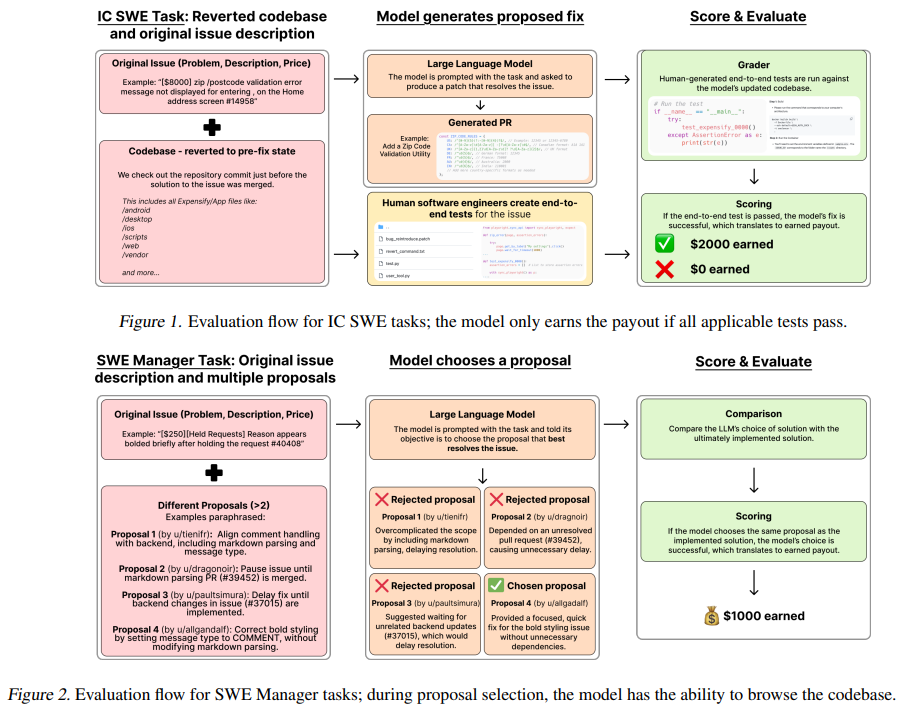
| 평가 유형 | 설명 |
|---|---|
| 🛠️ IC SWE Tasks | AI가 직접 코드를 수정하고 새로운 기능을 구현하는 작업 |
| 🧑💼 SWE Manager Tasks | AI가 여러 개발자의 해결책을 비교하고 최적의 해결책을 선택하는 작업 |
✅ IC SWE Tasks (개발자 역할)
- 버그 수정부터 새로운 기능 추가까지 다양한 작업 수행
- 예제: “API 중복 호출 문제 해결 ($250)”, “앱 내 비디오 재생 기능 추가 ($16,000)”
- 기존 벤치마크는 단순 코드 평가만 했지만, SWE-Lancer는 전체 코드베이스 맥락을 이해해야 함
✅ SWE Manager Tasks (팀 리드 역할)
- 여러 프리랜서 개발자의 코드 제안 중 최적의 선택을 해야 함
- 예제: “가장 효율적인 데이터베이스 최적화 방식 선택하기”
- 단순 코드 생성이 아니라 기술적 의사결정 및 평가 능력 테스트
3️⃣ 현실적인 검증 방식
✅ 모든 작업은 전문 소프트웨어 엔지니어들이 3단계 검증을 거쳐 평가
✅ 기존 코딩 벤치마크처럼 단순한 unit test 기반 평가가 아니라, 실제 end-to-end 테스트 사용
✅ 모델이 실제로 수익을 창출할 수 있는지를 평가하는 최초의 연구
💎 SWE-Lancer Diamond Set이란?
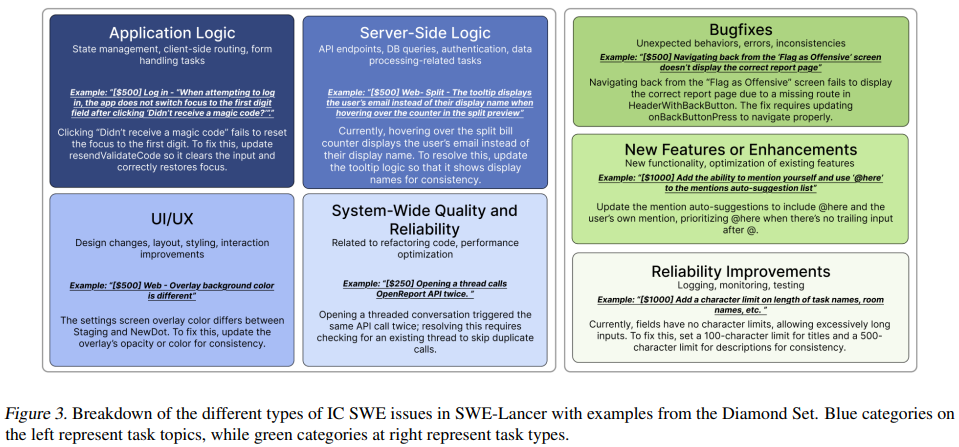
SWE-Lancer Diamond Set은 1,488개 전체 작업 중, 가장 엄선된 502개 작업을 포함하는 공개 벤치마크입니다.
💰 총 보상 금액: $500,800
🔹 Diamond Set의 특징
- 237개 IC SWE Tasks (총 보상 $236,300)
- 265개 SWE Manager Tasks (총 보상 $264,500)
- 실제 Upwork에서 완료된 프로젝트들로 구성
- AI 모델의 코딩 능력과 기술 의사결정 능력을 모두 평가
💡 쉽게 말해?
Diamond Set은 SWE-Lancer의 핵심 데이터셋이며, 연구자들이 AI 모델의 실제 경제적 가치를 실험할 수 있도록 공개된 부분입니다!
📊 벤치마크 성능 평가
SWE-Lancer에서 최신 LLM 모델들의 성능을 평가해 보았습니다. 결과는?
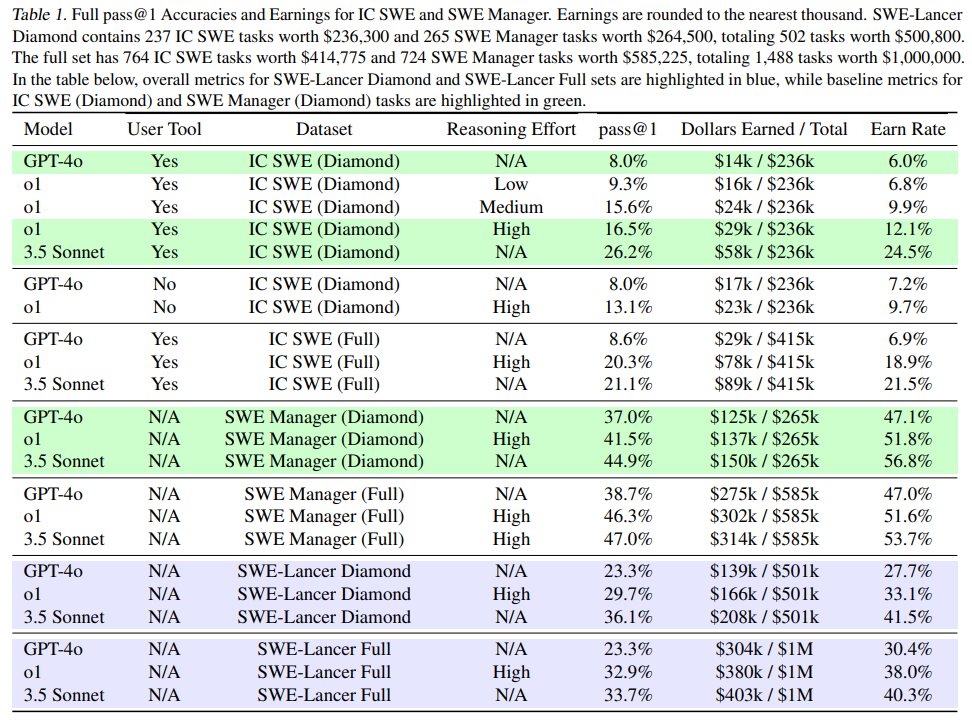
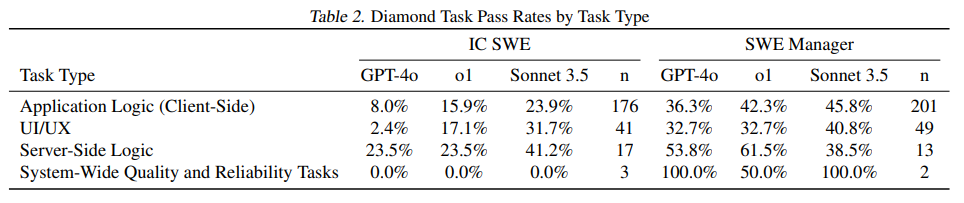
| 모델 | IC SWE 수행률 | SWE Manager 수행률 | 총 수익 ($1M 중) |
|---|---|---|---|
| GPT-4o | 8.6% | 38.7% | $304K (30.4%) |
| o1 (OpenAI) | 20.3% | 46.3% | $380K (38.0%) |
| Claude 3.5 Sonnet | 26.2% | 47.0% | $403K (40.3%) |
📌 Claude 3.5 Sonnet이 가장 높은 수익을 창출!
📌 AI 모델이 전체 작업의 약 40%를 수행 가능
📌 여전히 절반 이상의 작업에서는 인간 개발자가 필요
💡 결론?
현재의 LLM은 초급~중급 개발자 수준의 작업 일부는 수행할 수 있지만, 아직 고급 개발자의 역할을 대체하기엔 부족하다.
📦 설치 및 실행 방법 (GitHub)
SWE-Lancer를 직접 실행하고 싶은 분들을 위한 가이드입니다.
1️⃣ 환경 설정
Python 3.11을 권장합니다.
패키지 설치:
1
2
3
4
5
uv sync
source .venv/bin/activate
for proj in nanoeval alcatraz nanoeval_alcatraz; do
uv pip install -e project/"$proj"
done
또는 virtualenv 사용:
1
2
3
4
5
6
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
for proj in nanoeval alcatraz nanoeval_alcatraz; do
pip install -e project/"$proj"
done
2️⃣ Docker 이미지 빌드
Apple Silicon (M1, M2) 또는 ARM64 시스템:
1
docker buildx build -f Dockerfile --ssh default=$SSH_AUTH_SOCK -t swelancer .
Intel 기반 Mac (x86_64) 또는 AMD64 시스템:
1
docker buildx build -f Dockerfile_x86 --platform linux/amd64 --ssh default=$SSH_AUTH_SOCK -t swelancer .
3️⃣ 환경 변수 설정
sample.env 파일을 .env로 복사하여 API 키 및 환경 변수 설정:
1
cp sample.env .env
4️⃣ SWE-Lancer 실행
1
uv run python run_swelancer.py
실행 후 로그가 출력되며, 모델 설정 및 평가 옵션을 run_swelancer.py에서 조정할 수 있습니다.
🔮 향후 발전 방향
1️⃣ AI 개발자의 생산성 향상
- 현재 AI는 단순한 작업 수행에는 강하지만, 복잡한 작업에서는 여전히 인간 개발자가 필요
- 코드 품질 개선, 디버깅, 장기 프로젝트 관리 등의 능력 강화 필요
2️⃣ SWE Manager Tasks 성능 향상
- AI가 단순 코딩뿐만 아니라 개발 의사결정 능력까지 향상될 필요
- 현재는 가장 좋은 코드 선택하는 능력이 부족
3️⃣ 더 현실적인 평가 방법 추가
- 현재는 Upwork 기반 데이터셋이지만, GitHub, 기업용 프로젝트로 확장 필요
- 실제 기업 환경에서 AI가 개발자로 고용될 수 있는지 테스트하는 단계로 발전 가능
🎯 결론: LLM, 진짜 개발자가 될 수 있을까?
SWE-Lancer는 AI가 소프트웨어 엔지니어로서 실제 돈을 벌 수 있는지를 평가한 최초의 벤치마크입니다.
✅ 현재 AI는 초급~중급 개발자 수준의 작업은 일부 수행 가능
✅ 하지만 여전히 인간 개발자의 창의력과 고급 문제 해결 능력이 필요
✅ 앞으로 AI는 단순 코딩을 넘어, 개발자로서의 종합적 사고력을 키우는 방향으로 발전할 것
📢 AI가 실제 개발자로 취업하는 시대가 올까요? SWE-Lancer는 그 가능성을 열어가는 첫걸음입니다! 🚀