MoAI 톺아보기: 차세대 멀티모달 AI 모델
- 논문: MoAI: Mixture of All Intelligence for Large Language and Vision Models
- Github: https://github.com/ByungKwanLee/MoAI
🔍 MoAI란?
MoAI(Mixture of All Intelligence)는 기존 LLVM(Large Language and Vision Model)의 한계를 극복한 혁신적인 멀티모달 AI 모델입니다.
🎯 기존 LLVM의 문제점
GPT-4V, Gemini-Pro 같은 기존 LLVM들은 강력한 성능을 보이지만, 세부적인 장면 이해에서 한계가 있습니다.
- 객체 탐지(Object Detection) 오류 → 이미지 속 물체를 정확히 인식하지 못함
- 공간적 관계 이해 부족 → “사과가 테이블 위에 있다” 같은 관계 이해 실패
- OCR(광학 문자 인식) 오류 → 이미지 속 텍스트를 정확히 읽지 못함
💡 MoAI의 해결책
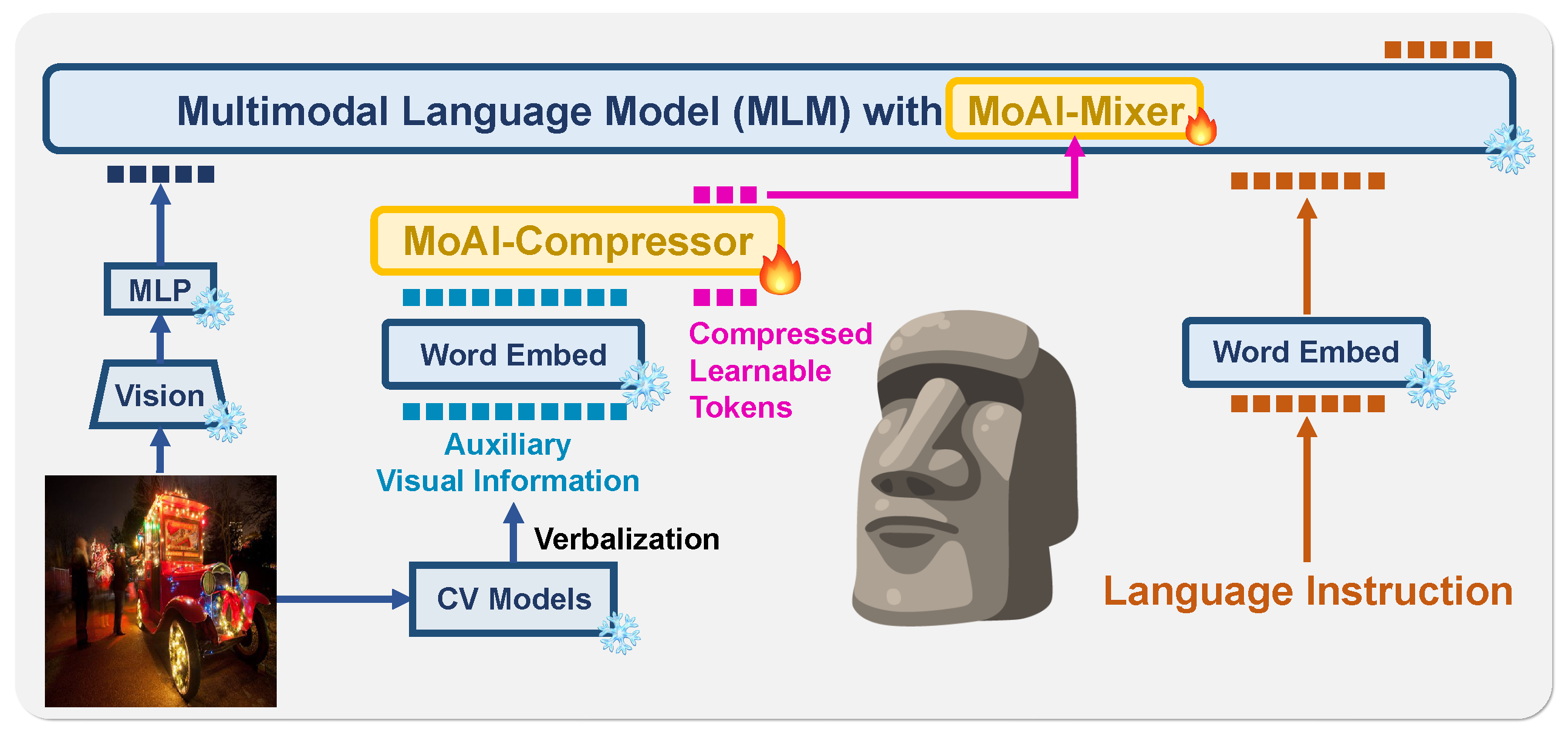
MoAI는 기존 LLVM의 한계를 극복하고, 보다 정밀한 장면 이해를 위해 외부 컴퓨터 비전(CV) 모델을 적극 활용합니다.
이를 위해 두 가지 핵심 기술을 새롭게 도입했습니다.
- MoAI-Compressor → 외부 CV 정보를 효과적으로 정리하여 모델이 활용할 수 있도록 함
- MoAI-Mixer → 각 정보를 최적의 비율로 조합하여 최상의 추론 성능을 제공
1️⃣ MoAI의 핵심 기술 1: MoAI-Compressor
기존 LLVM들은 이미지에서 시각적 특징을 추출하지만, 장면을 깊이 있게 분석하는 데 한계가 있습니다.
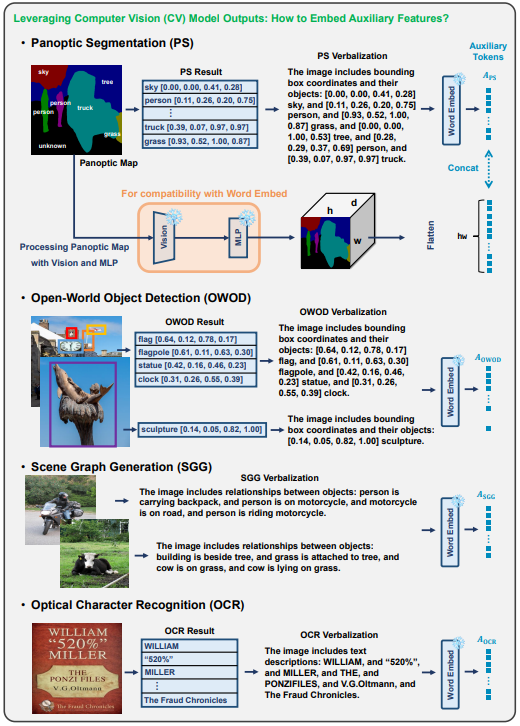
MoAI는 이를 해결하기 위해 4가지 외부 CV 모델을 활용합니다.
🔹 MoAI가 활용하는 외부 CV 모델
- Panoptic Segmentation → 이미지 내 객체와 배경을 구분
- Open-World Object Detection (OWOD) → 알려진 객체뿐만 아니라 미리 학습되지 않은 객체도 탐지
- Scene Graph Generation (SGG) → 객체 간 관계(예: “사람이 책을 읽고 있다”) 이해
- Optical Character Recognition (OCR) → 이미지 속 텍스트를 인식
이렇게 외부 CV 모델의 정보를 언어 모델이 해석할 수 있도록 변환하는 것이 MoAI-Compressor의 역할입니다.
🔹 MoAI-Compressor의 효과
✔ 객체 탐지·OCR 정확도 향상 → 기존 LLVM보다 높은 장면 이해력
✔ 추가 데이터 없이 성능 개선 → 대규모 데이터 없이도 학습 가능
✔ 연산 비용 최소화 → 모델 크기를 키우지 않고도 성능 개선
2️⃣ MoAI의 핵심 기술 2: MoAI-Mixer
MoAI-Compressor가 정보를 정리했다면, 이제 이 정보를 어떻게 조합할 것인가?
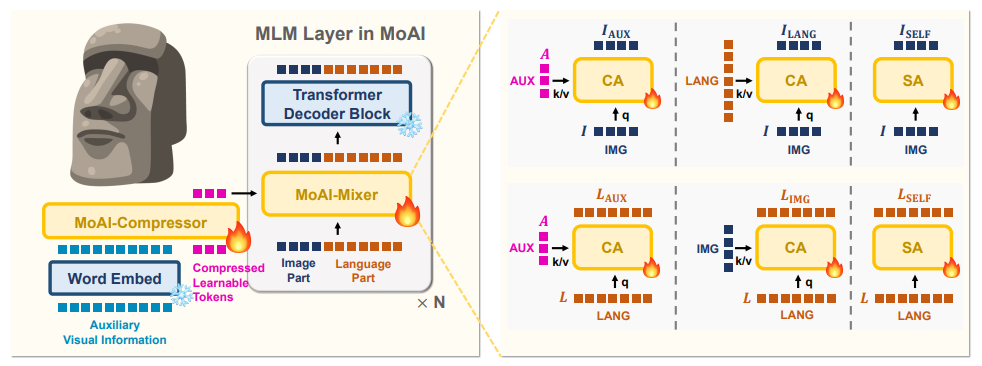
MoAI는 이를 위해 Mixture of Experts(MoE) 개념을 적용한 MoAI-Mixer를 활용합니다.
🔹 기존 LLVM의 문제점
- 기존 모델들은 시각·언어 정보만 단순 결합 → 최적의 정보 조합 어려움
- 보조 정보(외부 CV 모델 결과)를 고려하지 않아 세부 장면 이해 부족
🔹 MoAI-Mixer의 혁신적인 접근법
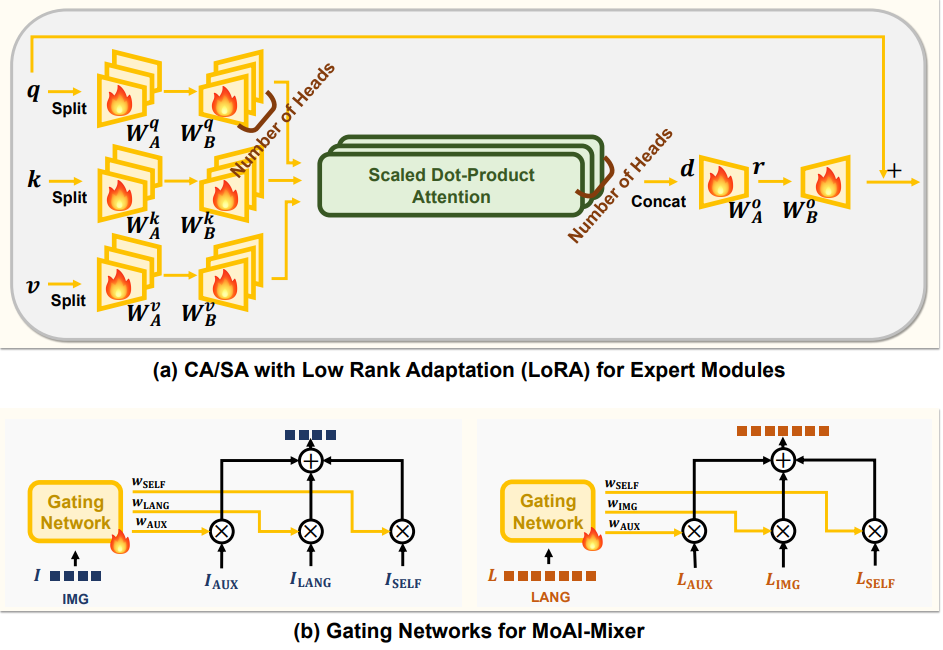
MoAI-Mixer는 3가지 종류의 정보(시각, 보조, 언어)를 각각 담당하는 전문가(Expert) 모듈을 구성하고, 이를 효율적으로 결합합니다.
- 시각 전문가 → CLIP 기반 이미지 정보 활용
- 보조 전문가 → CV 모델의 정보(객체 탐지, OCR 등) 활용
- 언어 전문가 → 텍스트 이해 및 논리적 추론 수행
MoAI는 가중치 조정(Gating Network) 을 통해 현재 상황에서 가장 중요한 정보에 가중치를 부여하여 최적의 결과를 도출합니다.
🔥 MoAI vs 기존 LLVM, 차이점은?
| 모델 | Zero-shot 성능(Q-Bench) | Zero-shot OCR(TextVQA) | 추가 학습 필요 여부 |
|---|---|---|---|
| GPT-4V | 63.8 | 58.2 | ✅ 필요 |
| LLaVA1.5 | 58.7 | 50.1 | ✅ 필요 |
| MoAI | 70.2 | 67.8 | ❌ 불필요 |
📌 핵심 차이점
- GPT-4V, LLaVA1.5 → 대규모 데이터셋으로 학습해야 성능 유지
- MoAI → 외부 CV 모델 활용으로 추가 데이터 없이 성능 개선
- MoAI의 MoAI-Compressor & Mixer 도입 → 세부 장면 이해 능력 향상
📊 실험 결과 분석: 왜 MoAI가 더 뛰어날까?
- MoAI-Compressor를 적용하면?
- 객체 탐지·OCR 정확도 향상 → 기존 LLVM보다 높은 장면 이해력
- 추가 데이터 없이도 모델 성능 개선 가능
- MoAI-Mixer를 활용하면?
- 각 정보 간 최적의 조합 → Zero-shot 성능 대폭 증가
- 모델 크기 증가 없이도 뛰어난 성능 유지
- 결과적으로 MoAI는 기존 LLVM보다 더 빠르고 정확한 장면 이해가 가능
🏆 결론: MoAI, LLVM의 새로운 기준!
💡 MoAI가 기존 LLVM보다 뛰어난 이유
✔ Zero-shot VL 성능 최대 20% 향상 (MoAI-Compressor)
✔ 객체 탐지·OCR·관계 인식 정확도 증가 (MoAI-Mixer)
✔ 추가 데이터 없이도 강력한 성능 발휘
👉 MoAI는 멀티모달 AI의 새로운 패러다임을 제시하는 모델로, 향후 LLVM 연구의 방향성을 바꿀 가능성이 큽니다.
😃 언어화(Verbalization)