LLaVA 톺아보기
LLaVA 톺아보기
- LLaVA: https://github.com/haotian-liu/LLaVA
- LLaVA Page: https://llava-vl.github.io/
- LLaVA NeXT: https://github.com/LLaVA-VL/LLaVA-NeXT/
- LLaVA Plus: https://github.com/LLaVA-VL/LLaVA-Plus-Codebase
본 논문은 시각적 명령 조정(Visual Instruction Tuning) 을 탐구하며, 기존 대규모 언어 모델(LLM)의 명령 조정(Instruct-Tuning) 을 멀티모달(언어-이미지) 학습으로 확장하는 방법을 연구한다. LLaVA (Large Language and Vision Assistant) 라는 종합적인 시각-언어 모델을 제안한다.

기존 연구와의 차별성 (Positioning)
- 기존 연구:
- 멀티모달 모델: CLIP, BLIP-2, Flamingo 등은 이미지-언어 학습을 활용.
- 명령 조정: ChatGPT, GPT-4, LLaMA, Alpaca, Vicuna 등은 텍스트 기반 명령 학습에 집중.
- 비전-언어 작업: 이미지 분류, 객체 검출, 세분화, 캡셔닝 및 시각적 질문 응답(VQA).
- 차별점:
- 기존 모델들은 고정된 인터페이스로만 이미지 정보를 처리하며 유연한 사용자 명령 수행 능력 부족.
- 본 연구는 LLM의 명령 수행 능력을 시각적 명령 학습으로 확장하여 일반 목적 멀티모달 AI 구축을 시도.
연구 방법
(1) 데이터 생성 (Visual Instruction Data Generation)
- GPT-4를 활용하여 멀티모달 명령 데이터 생성:
- 기존 이미지-텍스트 쌍(Image-Text Pairs) 을 명령 기반 데이터(Instruct Data) 로 변환.
- 세 가지 유형의 데이터 생성:
- 대화형 데이터 (Conversation): 이미지에 대한 질문-응답(Q&A)
- 상세 설명 (Detailed Description): 이미지의 포괄적인 서술
- 복잡한 추론 (Complex Reasoning): 논리적 추론이 필요한 질문
(2) 모델 개발 (LLaVA Architecture)
- LLaVA 모델 구조:
- 비전 인코더(Vision Encoder): CLIP (ViT-L/14) 활용하여 이미지 특징 추출.
- 언어 모델(Language Model, LLM): Vicuna (LLaMA 기반) 사용.
- 이미지 특징을 언어 임베딩으로 변환하기 위한 선형 변환 (Linear Projection) 적용.
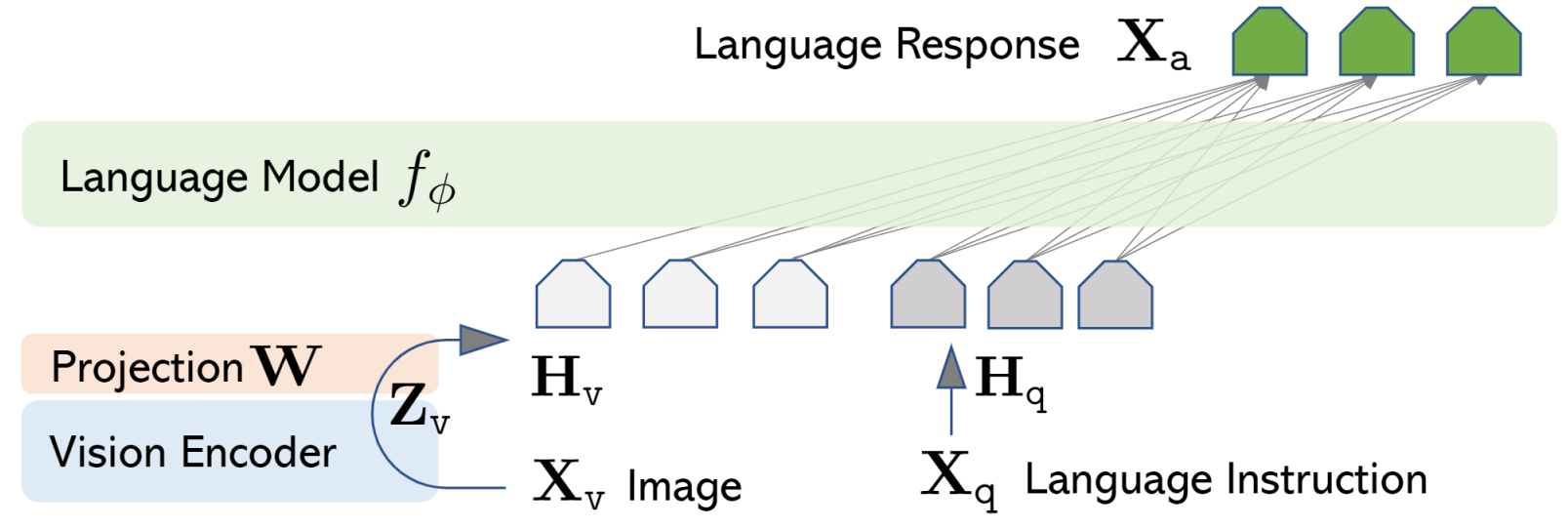
(3) 네트워크 구조 (LLaVA Model Architecture)
- LLaVA의 핵심 수식:
이미지 특징 추출:
\[Z_v = g(X_v)\]- 여기서 $X_v$는 입력 이미지, $g(\cdot)$는 CLIP의 비전 인코더.
이미지 특징을 언어 모델 입력에 맞게 변환:
\[H_v = W \cdot Z_v\]- $W$는 학습 가능한 선형 투영 행렬 (Trainable Projection Matrix).
멀티모달 명령 데이터로 학습하는 자기회귀(auto-regressive) 방식: \(p(X_{\alpha}|X_v, X_{instruct}) = p_{\theta}(x_i|X_v,X_{instruct,<i}, X_{\alpha,<i})\)
- 여기서 $X_{\alpha}$는 모델이 생성할 응답, $X_{instruct}$

(4) 모델 학습 (Training Process)
- 2단계 학습 방식 (Two-stage Instruction-Tuning)
- 사전 학습 (Pre-training for Feature Alignment)
- 59.5만 개의 CC3M 이미지-텍스트 데이터를 활용하여 이미지 특징과 언어 모델을 정렬(alignment).
- LLM은 고정(Frozen), 투영 행렬 $W$만 학습.
- 사전 학습 (Pre-training for Feature Alignment)
- 미세 조정 (Fine-tuning on Instruction Data)
- GPT-4가 생성한 15.8만 개의 명령 데이터로 LLM과 투영 행렬을 동시 학습.
주요 실험 결과 (Key Findings)
(1) 멀티모달 챗봇 평가 (Multimodal Chatbot Evaluation)
- LLaVA는 GPT-4와 유사한 수준의 이미지 이해 및 대화 능력을 보임.
- 기존 BLIP-2 및 OpenFlamingo보다 더 정확한 시각적 명령 수행 가능.
(2) 정량적 평가 (Quantitative Results)
- LLaVA는 GPT-4 대비 85.1% 수준의 성능을 달성.
- Instruction Tuning이 없을 경우 성능이 63.6% 감소, 즉 필수적인 학습 과정임을 입증.
(3) ScienceQA 벤치마크 평가
- 과학 지식 기반 멀티모달 QA 데이터셋(ScienceQA) 에서 최고 성능 기록:
- 단독 LLaVA 모델: 90.92% 정확도.
- LLaVA + GPT-4 조합 (Judge Model): 92.53% → State-of-the-Art 달성.
향후 연구 방향 (Future Work)
- 더 강력한 아키텍처 설계
- 현재 단순한 선형 투영을 크로스 어텐션(Cross-Attention) 기법으로 대체 가능.
- 더 다양한 학습 데이터 추가
- 멀티모달 이해도를 높이기 위해 비디오, 3D 환경 학습 데이터 도입 필요.
- 강화 학습(RL) 기반 명령 조정 연구
- GPT-4처럼 사용자 피드백을 반영하는 명령 수행 최적화 연구.
결론
- 본 연구는 시각적 명령 조정(Visual Instruction Tuning)의 가능성을 입증하며,
- 멀티모달 명령을 따를 수 있는 대규모 모델(LLaVA)을 제안.
- GPT-4를 활용한 명령 데이터 생성이 효과적임을 실험적으로 확인.
- ScienceQA 및 멀티모달 대화 평가에서 최고 성능(State-of-the-Art)을 기록.
- 향후 더 다양한 응용 사례 및 개선된 모델 구조 연구 필요.
This post is licensed under CC BY 4.0 by the author.