HunyuanVideo 톺아보기: 오픈소스 비디오 생성 모델의 새로운 기준
- 논문: HunyuanVideo: A Systematic Framework for Large Video Generative Models
- GitHub: https://github.com/Tencent/HunyuanVideo
- Demo: HunyuanVideo Playground
- Hugging Face 모델: HunyuanVideo on Hugging Face
🎥 HunyuanVideo란?
HunyuanVideo는 130억 개의 파라미터를 갖춘 오픈소스 비디오 생성 모델입니다.
Runway Gen-3, Luma 1.6 등 최신 폐쇄형 모델과 경쟁할 수 있는 성능을 제공합니다.
📌 HunyuanVideo의 특징
✔ 130억 개의 파라미터 → 최대 규모 오픈소스 비디오 생성 모델
✔ 최적화된 데이터 전처리 → 고품질 데이터 필터링 적용
✔ 효율적인 학습 기법 → 기존 대비 5배 적은 연산 자원으로 학습
✔ 고품질 비디오 생성 → 더 정교한 모션 & 해상도 지원
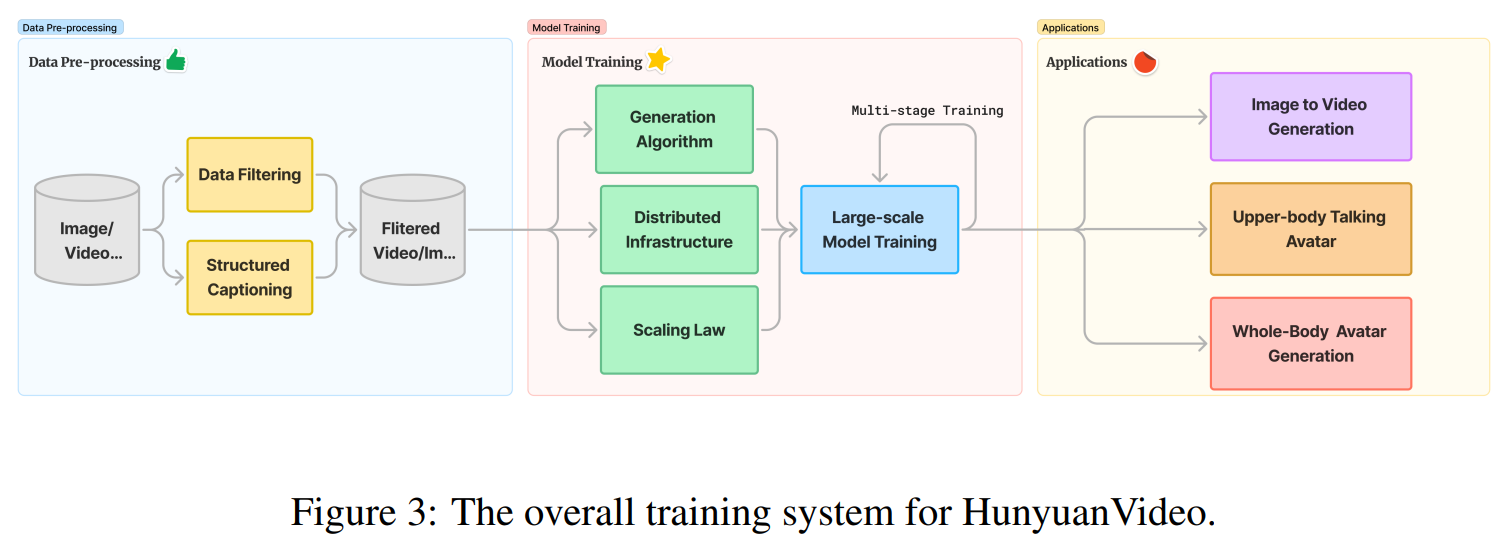

📂 데이터 전처리 (Data Preprocessing)
HunyuanVideo의 성능을 극대화하기 위해, 다단계 데이터 필터링을 적용합니다.

1️⃣ 계층적 데이터 필터링 시스템
HunyuanVideo는 저품질 데이터를 제거하고, 학습 데이터의 질을 극대화하기 위해 여러 단계의 필터링을 수행합니다.
🔹 영상 품질 필터링
✔ 해상도 기반 필터링: 256p → 360p → 540p → 720p → 수작업 검수(SFT)
✔ OpenCV Laplacian Operator로 흐림(Blur) 검출
✔ YOLOX를 활용해 워터마크, 로고 제거
✔ OCR 모델로 과도한 텍스트 포함된 영상 필터링
🔹 텍스트-비디오 정렬 개선
✔ Vision-Language Model(VLM) 기반 자동 캡션 생성
✔ JSON 형식의 구조화된 캡션 활용 (장면 설명, 스타일, 촬영 기법 포함)
🛠️ 모델 아키텍처 (Architecture)
HunyuanVideo는 효율적인 데이터 압축, 강력한 텍스트 인코딩, 최적화된 Diffusion 모델을 조합하여 고품질 비디오 생성을 가능하게 합니다.
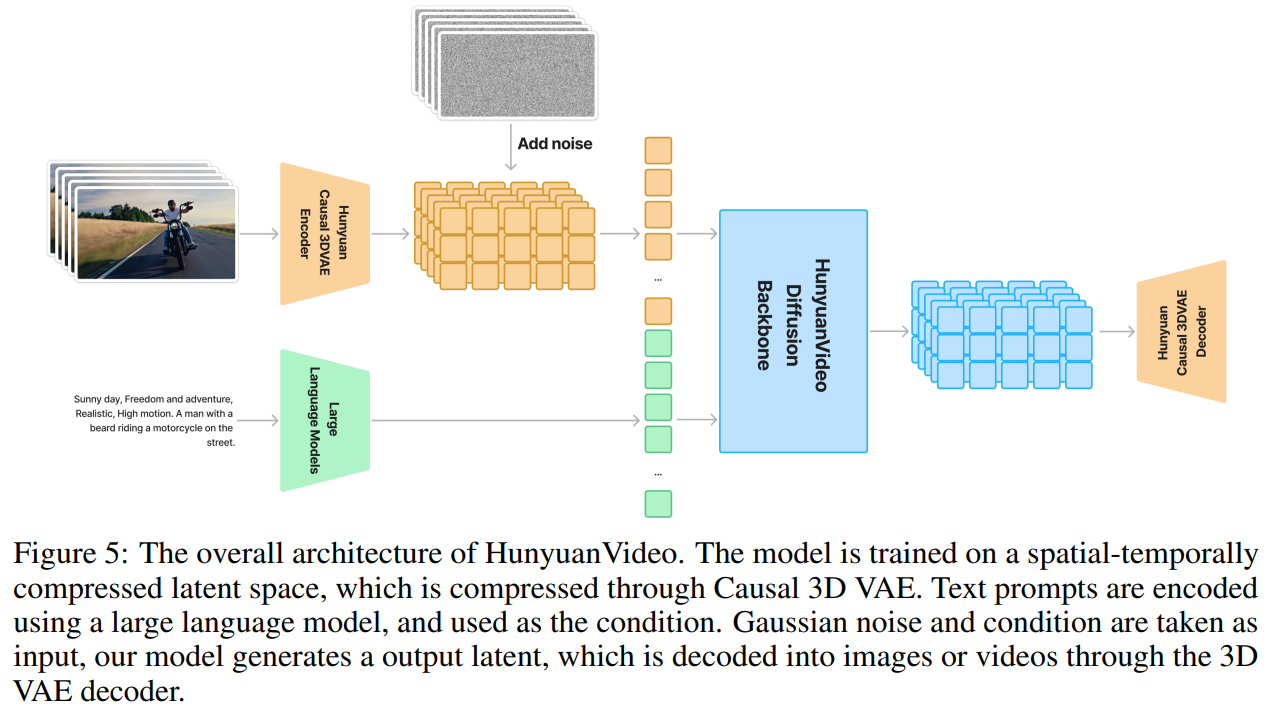
1️⃣ 3D VAE 기반의 효율적인 데이터 압축
HunyuanVideo는 Causal 3D Variational Autoencoder (VAE) 를 사용하여 고해상도 비디오를 압축합니다.
🎯 왜 압축이 중요한가?
- 원본 비디오 데이터는 용량이 매우 큼 → 처리 비용이 증가
- 3D VAE를 사용하면 → 비디오의 핵심 정보를 유지하면서 4×(시간), 8×(공간), 16×(채널)로 압축
- Perceptual Loss & GAN Loss 적용 → 원본 품질을 유지하며 복원 성능 강화
2️⃣ Transformer 기반 Diffusion 모델 적용
- 텍스트 인코딩: MLLM (Multimodal Large Language Model) 사용
- Full Attention 기법 적용 → 비디오 & 이미지 생성 성능 향상
- RoPE (Rotary Position Embedding) 확장 → 시간-공간 정보를 효과적으로 반영
📈 학습 과정 (Training Process)
HunyuanVideo는 점진적 학습 전략 (Progressive Training) 을 적용하여 학습합니다.
🔹 단계별 학습 과정
1️⃣ 256px 이미지 사전학습 → 저해상도 이미지 학습
2️⃣ 512px 혼합 학습 → 해상도 증가
3️⃣ 비디오-이미지 공동 학습 → 장면의 연속적 흐름 학습
4️⃣ 고해상도 장시간 비디오 학습 → 세밀한 장면 표현 능력 강화
🚀 성능 평가 (Performance Evaluation)
HunyuanVideo는 다양한 기준에서 기존 폐쇄형 모델을 능가하는 성능을 보였습니다.
| 모델 | 텍스트 정렬 (Text Alignment) | 모션 품질 (Motion Quality) | 영상 품질 (Visual Quality) | 종합 점수 |
|---|---|---|---|---|
| HunyuanVideo (Ours) | 61.8% | 66.5% | 95.7% | 1위 🏆 |
| CNTopA | 62.6% | 61.7% | 95.6% | 2위 |
| CNTopB | 60.1% | 62.9% | 97.7% | 3위 |
| Gen-3 Alpha | 47.7% | 54.7% | 97.5% | 4위 |
| Luma 1.6 | 57.6% | 44.2% | 94.1% | 5위 |
🔥 주요 성능 개선 포인트
✔ 텍스트-비디오 정렬 개선 → AI가 주어진 프롬프트를 더 정확히 해석
✔ 더 자연스러운 모션 표현 → 캐릭터 움직임 및 장면 전환 품질 상승
✔ 고해상도 비디오 지원 → 720p, 1080p 해상도에서도 탁월한 결과
📝 주요 기능 (Key Features)
1️⃣ 텍스트-비디오 생성 (Text-to-Video)
- 자연어 프롬프트를 입력하면 AI가 영상 생성
- 예제:
"A cat walks on the grass, cinematic style."
2️⃣ 이미지-비디오 변환 (Image-to-Video)
- 한 장의 이미지를 기반으로 연속적인 비디오 생성
- 하이브리드 조건 지원 (예: 첫 프레임 고정 후 나머지 생성)
3️⃣ 아바타 애니메이션 (Avatar Animation)
- AI가 목소리 & 표정 분석하여 캐릭터 애니메이션 자동 생성
- 실시간 가상 인간(Virtual Human) 생성 가능
📌 설치 및 실행 방법 (Installation & Usage)
🔧 설치 (Installation)
1
2
3
4
5
git clone https://github.com/Tencent/HunyuanVideo
cd HunyuanVideo
conda create -n hunyuanvideo python=3.10
conda activate hunyuanvideo
pip install -r requirements.txt
🎬 비디오 생성 (Generating Videos)
1
2
3
4
5
6
python3 sample_video.py \
--video-size 720 1280 \
--video-length 129 \
--infer-steps 50 \
--prompt "A beautiful sunset over the ocean, cinematic style." \
--save-path ./results
🖥️ Gradio 웹 UI 실행 (Web UI)
1
python3 gradio_server.py
실행 후 웹 브라우저에서 localhost:8080 접속
📈 결론: HunyuanVideo, 차세대 비디오 생성 모델!
💡 HunyuanVideo가 특별한 이유.
✔ 오픈소스 최초의 130억 파라미터 비디오 생성 모델,
✔ 텍스트 & 이미지 기반 고품질 영상 생성 가능,
✔ 추가 학습 없이 최적의 성능 제공,
✔ Runway Gen-3, Luma 1.6과 경쟁할 수 있는 품질