FSAF 톺아보기
FSAF
(Feature Selective Anchor-Free Module for Single-Shot Object Detection)
- FSAF Paper : Here

Abstract
Feature Selective Anchor-Free 모듈을 제안하는 논문이고 피라미드 구조의 single object detector에 연결할수 있다. FSAF 모듈은 anchor-based object detection의 두가지 한계를 해결한다.
- 1 직접 선택해야 한다.(heuristic)
- 2 overlap 기반으로 anchor를 sampling한다.
anchor-free는 feature pyramids의 각 level에 붙어있기 때문에 임의의 level에서 box encoding과 decoding이 가능하다. 추론시 FSAF 모듈은 예측을 병렬로 처리해서 anchor-based와 공동으로 작업할 수 있다. 모든 single object detector보다 성능이 우수하고 빠르다.
- 성능 : COCO 44.6% mAP(state-of-the-art)
Introduction
object detection에서 한 가지 어려운 문제는 스케일의 변화 다. 스케일의 변화에 대응하기 위해서 최첨단 detector는 feature pyramids 또는 multi-level feature tower를 구성한다. anchor box는 가능한 모든 box의 연속 공간을 미리 정의된 위치, 크기 및 종횡비를 가진 유한한 박스로 분리하기 위해 설계되었다. 그리고 instance box를 IOU overlap을 기반으로 anchor box와 매칭시킨다.
그러나 anchor-based에는 두가지 약점이 있다.
- 1 직접 선택(heuristic)
- 2 IOU overlap 기반으로 가장 가까운 anchor를 일치시킨다.
예를 들어, 크기가 50x50 pixel인 자동차 instance와 크기가 60x60 pixel인 자동차 instance는 두 개의 서로 다른 level에 할당 될 수 있는 반면, 또 다른 40x40 pixel 자동차 instance는 동일한 level에 할당 될 수 있다.
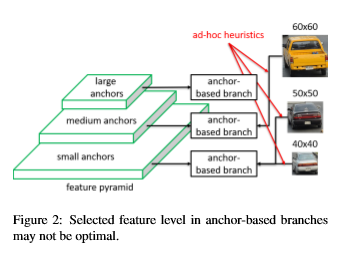
FSAF 모듈은 이러한 한계를 동시에 해결한다.
FSAF의 목표는 각 instance가 네트워크를 최적화하기 위해 최상위 수준의 feature를 자유롭게 선택할 수 있도록 하는 것이므로 모듈에서 feature 선택을 제한할 anchor box가 없어야 한다는 것 이다.
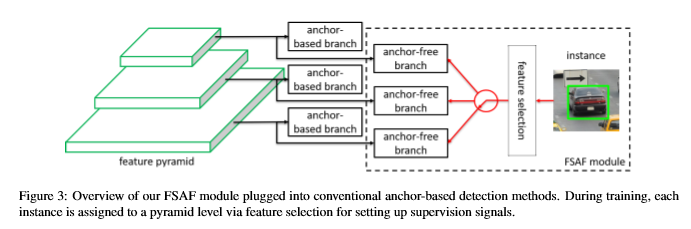
anchor-based와 독립적으로 feature pyramid level 마다 구축된다.
anchor-based와 유사하게 classification / regression subnet 으로 구성된다.
학습시, instance box를 detection하는 방법을 학습
추론시, FSAF 모듈은 anchor-based와 독립적으로 또는 공동으로 실행될 수 있다.
Related Work
| Name | Content |
|---|---|
SSD | multi scale feature map |
FPN,DSSD | semantic feature maps으로 low-level 기능 향상 |
RetinaNet | focal loss로 class 불균형 해결 |
DetNet | high-level pyramid 에서 높은 공간 해상도를 유지하기 위해 backbone network 설계 |
Zhuetal | 작은 object를 위한 anchor design을 향상 |
He et al | bounding box를 localization 향상을 위한 Gussian distribution로 모델링 |
DenseBox | 먼저 경계 상자를 직접 예측 |
UnitBox | bounding box offset을 위한 IOU loss 제안 |
CornerNet | bounding box를 한쌍의 모서리로 감지하여 최상의 single detector를 제안 |
SFace | anchor-based, anchor-free 통합 |
FSAF Module
1 네트워크에서 anchor-free branch를 만드는 방법.
2 anchor-free에 대한 supervision signal를 생성하는 방법
3 각각의 instance에 대한 feature level을 동적으로 선택하는 방법
4 anchor-free , anchor-based를 동시에 훈련하고 추론하는 방법
Network Architecture
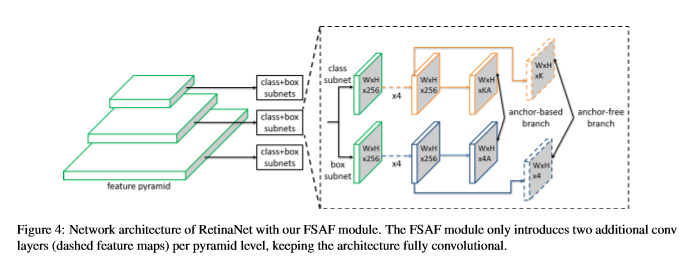
- Backbone : RetinaNet
- pyramid : P3 ~ P7
- l : pyramid level
- \(P^l\) : pyramid,입력 이미지에 \(1/2^l\) 해상도
classification subnet(class probability)regression subnet(box offset)
- A : anchor
- K : object class
- pyramid level 당 2개의 convolution layer만을 추가한다.
- classification : 3x3 conv, sigmoid
- regression : 3x3 conv, relu
Ground-truth and Loss
object instance가 주어지면
- k : class
- b : bounding box 좌표(x,y,w,h)
를 알수 있다. 그리고 훈련 중에 instance를 임의의 \(P^l\)(feature level)에 할당 할 수있다.
\(b_{p}^{l} = [x_{p}^{l},y_{p}^{l},w_{p}^{l},h_{p}^{l}]\) : 논문에서 직접 projected box 이라고 정의 하였고 feature pyramid \(P^l\)에 대한 b의 projection
즉, \(b_{p}^{l} = b / 2^l\) (예측할 bounding box, feature pyramid에 투영된 bounding box)
\(b_{e}^{l} = [x_{e}^{l},y_{e}^{l},w_{e}^{l},h_{e}^{l}]\) : effective box
\(b_{i}^{l} = [x_{i}^{l},y_{i}^{l},w_{i}^{l},h_{i}^{l}]\) : ignoreing box
\(\epsilon _{i}\),\(\epsilon _{e}\) : 일정한 scale factor(각각 0.5 , 0.2)
\[x_{e}^{l} = x_{p}^{l}, y_{e}^{l} = y_{p}^{l}, w_{e}^{l} = \epsilon _{e}w_{p}^{l}, h_{e}^{l} = \epsilon _{e}h_{p}^{l} x_{i}^{l} = x_{p}^{l}, y_{i}^{l} = y_{p}^{l} w_{i}^{l} = \epsilon _{i}w_{p}^{l}, h_{i}^{l} = \epsilon _{i}h_{p}^{l}\]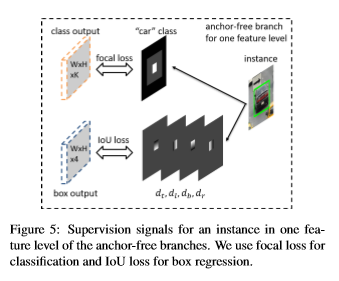
Classification Output
- 먼저,
effective box영역은 위에 그림처럼 흰색 상자로 표현된 영역이다. instance의 존재를 나타낸다.
- 두번째,
effective box를 제외한ignoring box는 회색 영역으로 표현된ignoring region이다. 역전파를 시키지 않는다.
세번째, 인접한 feature level(\(b_{i-1}^{l} , b_{e+1}^{l}\))의
ignoring box도 존재하는 경우 무시한다.두개의 instance box가 겹치면 더 작은 instance box의 우선순위가 높다. 그리고 나머지 검은색 영역은 object가 없다는 것을 나타낸다.
Focal loss는 \(α = 0.25 , γ = 2.0\) 모든 ignoreing 영역이 아닌 모든 영역의Focal loss합
Box Regression Output
\(b_{e}^{l}\) 내부의 각 픽셀 위치 \((i,j)\)에 대해서 \(b_{p}^{l}\)(projected box) 를 4차원 벡터
\[d_{i,j}^{l} = [d_{t_{i,j}}^{l},d_{l_{i,j}}^{l},d_{b_{i,j}}^{l},d_{r_{i,j}}^{l}]\]로 표현한다. 각각 현재 픽셀 위치 \((i, j)\) 와 \(b_{p}^{l}\) 의 상하 좌우 경계 사이의 거리 이다. 그리고 각각의 맵이 1차원에 대응하여 \(d_{i,j}^{l}/S\)로 설정 된다. \(S\)는 정규화 상수고 0.4로 선택한다.
이미지에 대한 anchor-free의 총 regression loss는 모든 effective box영역에 대한 IOU loss의 평균이다.
추론하는 동안 예측 된 상자를 decoding 하는 것이 간단하다. 각 픽셀의 위치 (\(i,j\))에서 예측된 offset을 아래라고 가정하에
\[[\hat{o}_{t_{i,j}}^{l},\hat{o}_{l_{i,j}}^{l},\hat{o}_{b_{i,j}}^{l},\hat{o}_{r_{i,j}}^{l}]\]예측된 거리
\[[S_(\hat{o}_{t_{i,j}}^{l}),S_(\hat{o}_{l_{i,j}}^{l}),S_(\hat{o}_{b_{i,j}}^{l}),S_(\hat{o}_{r_{i,j}}^{l})]\]왼쪽 상단과 오른쪽 상단
\((i-S_(\hat{o}_{t_{i,j}}^{l}),j-S_(\hat{o}_{l_{i,j}}^{l}))\) 과 \((i + S_(\hat{o}_{b_{i,j}}^{l}),j + S_(\hat{o}_{r_{i,j}}^{l}))\)
- 이미지 평면에서 최종 box를 얻기 위해 projected box를 \(2^l\) 더 확장한다. box에 대한 confidence score와 class는 classification out의 위치 \((i,j)\) 에서 K-dimension vector의 최대 점수와 대응하는 class에 의해 결정 될 수 있다.
Online Feature Selection
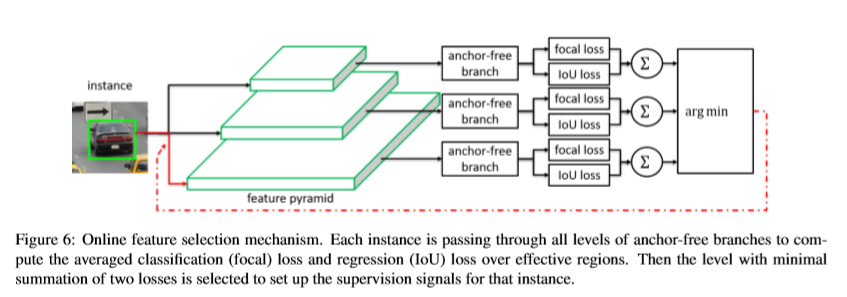
anchor-free branch의 설계를 통해서 임의의 pyramid level \(P^l\)의 feature를 사용해서 각 instance를 학습 할 수 있다. instance box 대신 instance content를 기반으로 최적의 \(P^l\)을 선택한다.
instance I가 주어지면
\[L^{I}_{FL},L^{I}_{IOU}\]로 classification loss와 regression loss를 정의한다.
\[L^{I}_{FL} = \frac{1}{N(b^{l}_{e})} \sum_{i,j \in b^{l}_{e}} FL(l,i,j)\] \[L^{I}_{IOU} = \frac{1}{N(b^{l}_{e})} \sum_{i,j \in b^{l}_{e}} IOU(l,i,j)\]\((b^{l}_{e})\)는 \(b^{l}_{e}\)영역 내부의 픽셀수이고 \(FL(l,i,j),IOU(l,i,j)\)는 \(P^l\)의 \((i,j)\)위치에서의 loss다.
- 1 먼저 instance는 모든 level의 feature pyramid를 통해 전달된다.
- 2 \(L^{I}_{FL}(l),L^{I}_{IOU}(l)\)는 방정식을 사용하여 모든 anchor-free branch를 계산한다.
- 3 최종적으로 loss의 최소 합계를 산출하는 최적의 pyramid level \(P_{l^*}\)가 instance를 학습하기 위해 선택이 된다.
Joint Inference and Training
RetinaNet에 연결하면 FSAF모듈과 anchor-based branch가 함께 동작한다. anchor-based branch는 원본과 동일하게 동작하고 모든 하이퍼 파라미터는 학습과 추론에서 변경되지 않는다.
anchor-free branch의 경우 confidence score를 0.05로 임계값을 정한 후 각 피라미드 level에서 최대 1k 최고 점수 위치의 box 예측만 decoding 한다.
모든 level의 최상위 box 예측은 anchor-based branch의 box 예측과 합쳐지고 threshold가 0.5인 nms를 통해 최종 detection이 이루어진다.
Initialization
backbone은 ImageNet 1k로 pre-training
- FSAF 모듈의 classification layer의 경우
bias: \(-log((1-\pi)/\pi)\)weight: Gaussian weight (\(\sigma = 0.01\))
학습시 모든 픽셀 위치에서 약 \(\pi\) 의 objectness score를 출력하도록 정한다.(\(\pi= 0.01\))
- 모든 경험으로 부터 box regression layer는 bias b(b = 0.1), Gaussian weight (\(\sigma = 0.01\))로 초기화 된다.
Optimization
\[L = L_{ab} + \lambda (L_{cls}^{af} + L_{reg}^{af})\]- \(L_{ab}\) : original anchor-based RetinaNet 의 total loss
\(\lambda\) : anchor-free 의 weight를 제어(\(\lambda = 0.5\))
SGD: 90K,lr=0.01 -> 60K,lr=0.001 -> 80K,lr=0.0001augmentation: Horizontal Flipweight decay: 0.0001momentum: 0.9
Experiments
- dataset : COCO
- All :85K(train : 35K, val : 40K, minival : 5K)
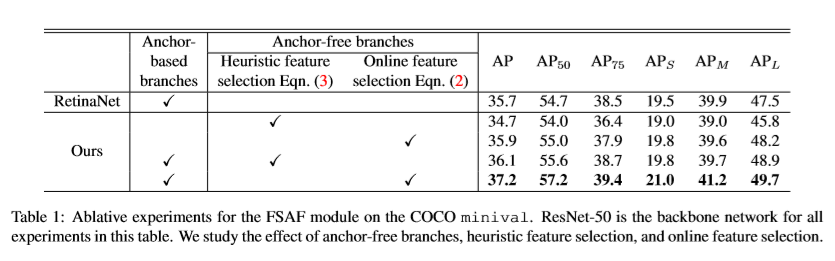
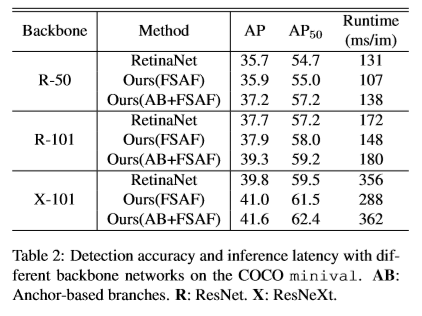
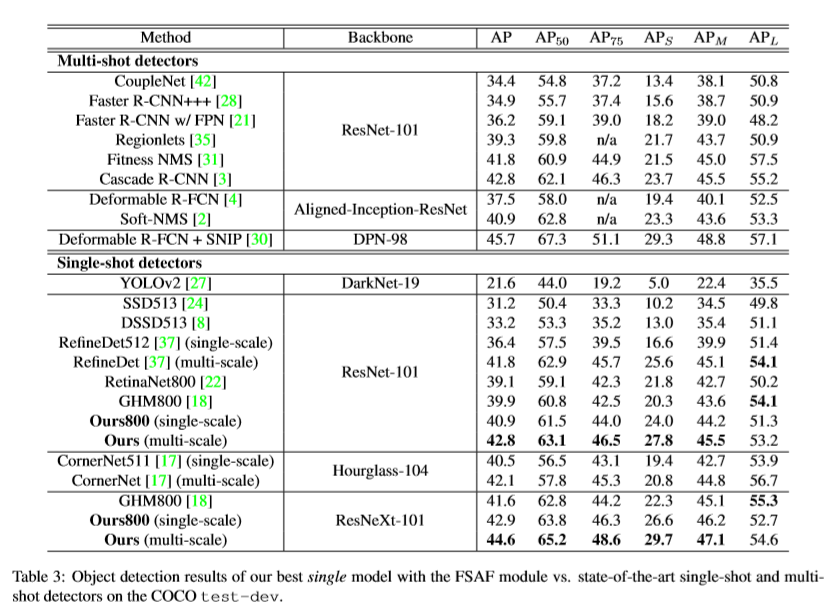
Benchmark
Conclusions
anchor-based의 한계를 극복하기 위해 FSAF 모듈을 제안하였고 작은것을 추론하는 것을 크게 개선하고 최신 detector보다 성능이 뛰어나다.