DarkNet 시리즈 - YOLOv2
YOLOv2
- Paper : https://arxiv.org/abs/1612.08242
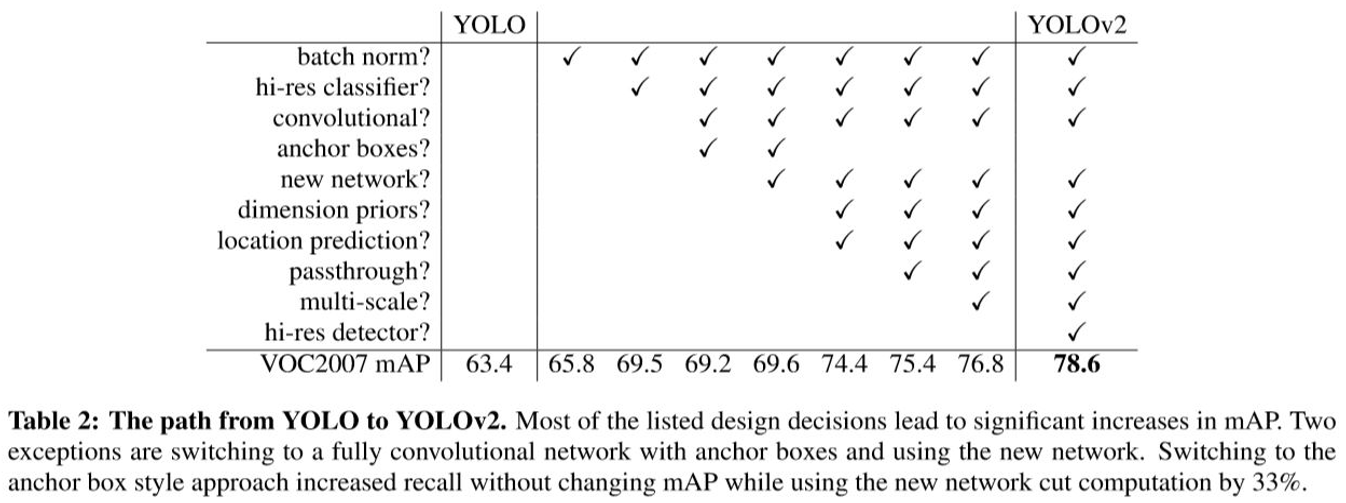
기존 YOLO의 낮은 검출율과 상당 수의 localization error를 해결하기 위해 여러가지 실험을 진행한 논문입니다.
Better
YOLOv2
Batch Normalization
모든 Convolution Layer에 기존에 사용한 Dropout을 제거하고 Batch Normalization을 추가함으로 mAP가 2% 향상됩니다.
High Resolution Classifier
먼저 Classifier Network를 448x448 해상도로 10 epoch동안 fine-tuning 시킵니다. 그리고 마지막 Convolutional Layer와 Avgpooling Layer, Softmax Layer를 없애고 Detectionㅇ을 위한 Layer 4개를 추가함으로 mAP가 4% 향상됩니다.
Convolutional
기존의 Yolo는 마지막 Layer로 Fully Connected Layer를 사용하여 Bounding Box를 예측합니다. 이것을 Convolutional Layer로 바꾸었습니다.
최종 Feature Map을 홀수로 만들기 위해서 448x448 입력 이미지를 416x416으로 만듭니다. 이렇게 홀수로 만듦으로 인해서 중심점은 하나만 존재합니다.(짝수인 경우 중심점이 4개 입니다.) 중심점이 여러개라면 작은 Object의 검출이 어려울 수 있습니다. 최종적으로 13x13의 크기를 갖는 Feature Map을 얻습니다.
Anchor Boxes
기존 YOLO와 다르게(objectness, x, y, w, h, c, x, y, w, h, c) YOLOv2에서는 Anchor Box의 개수만큼(objectness, x, y, w, h, c, objectness, x, y, w, h, c, …) 클래스, 객체의 유무를 예측합니다.
Anchor box를 사용함으로써 mAP는 살짝 감소하지만 recall이 높아져서 예측을 더 많이 할 수 있습니다.
no anchor box = mAP : 69.5 recall : 81% anchor box = mAP : 69.2 recall : 88%
New Network
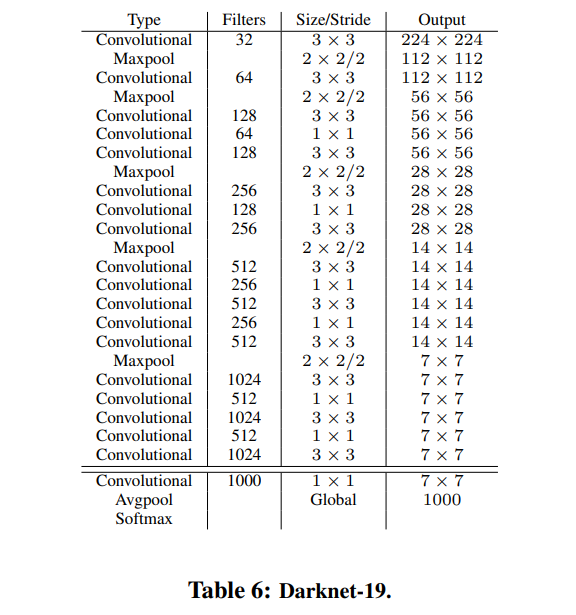
DarkNet 19를 새롭게 제안합니다.
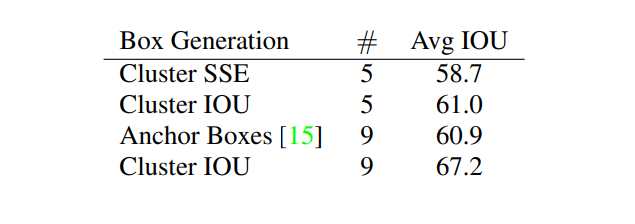
Dimension Clusters
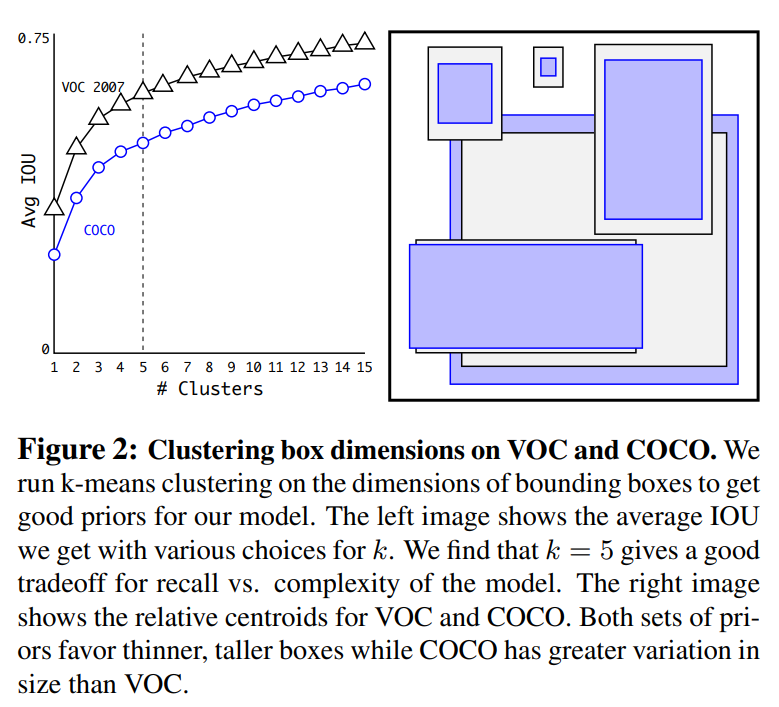
자동적으로 Anchor Box를 선택하기 위해서 K-means Clustering 알고리즘을 사용합니다. 그리고 K-means Clustering에서 유클리디안 거리를 사용하지 않고 아래와 같은 거리를 사용합니다.
d(box, centroid) = 1 - IOU(box, centroid)
k가 커지면 clustering의 결과와 label사이의 IOU가 커지기 때문에 recall이 상승하지만 모델의 복잡도가 상승하는 trade-off 관계를 가지기 때문에 k를 5로 선택합니다.
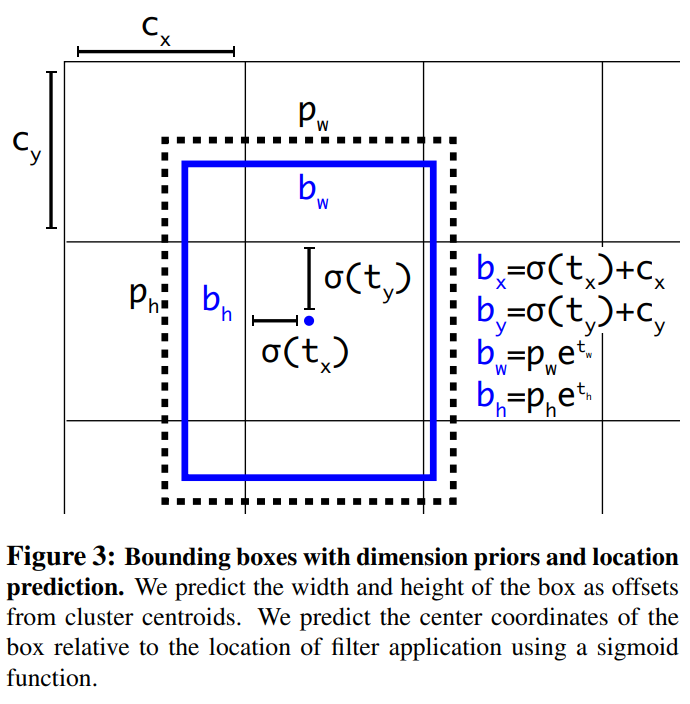
Direct location prediction
Anchor Box를 사용하면 학습 초기에 모델이 불안정해지는 문제를 해결할 수 있었는데 그 원인은 Box의 좌표가 랜덤하게 예측되기 때문입니다. 그래서 RPN종류의 모델은 \(t_x, t_y\)를 예측하고 중심 좌표를 아래와 같이 계산합니다.
\[x = (t_x * w_a) - x_a\] \[y = (t_y * h_a) - y_a\]예를 들어서 \(t_x = 1\)인 경우 box를 오른쪽으로 이동시킬 것이고 \(tx=-1\)인 경우 box를 왼쪽으로 이동시킬 것 입니다. 이 공식은 제약이 없기 때문에 box를 예측한 위치에 관계 없이 Anchor Box의 위치가 어디에도 나올 수 있다는 문제점 을 가지고 있습니다.
YOLOv2는 위에 문제점을 해결하기 위해서 제약조건을 줍니다. YOLOv2에서는 grid cell에 상대적인 좌표를 유추하도록 하였습니다. x, y의 위치가 grid cell 내부에만 존재하도록 제약을 주기 때문에 0 ~ 1사이의 값을 갖게 됩니다.
- \(c_x, c_y\) : 각 grid cell의 좌상단 끝에 offset
- \(p_x, p_y, p_w, p_h\) : 우선 순위 anchor box의 x, y, w, h
- \(t_x, t_y, t_w, t_h\) : 예측한 bounding box의 x, y, w, h
- \(b_x, b_y, b_w, b_h\) : 예측한 bounding box의 값을 조정해 Ground Truth와 IOU를 계산하기 위한 bounding box
- \(t_o\) : object인지 아닌지
\(t_x, t_y\)는 0의 값을 가져 \(b_x, b_y\)가 중심 좌표(0.5)가 되기를 원하고 \(t_w, t_h\)도 0의 값을 가져 \(p_w, p_h\)가 \(b_w, b_h\)와 같아지기를 원합니다. exp 함수의 특성상 음수가 나오면 양수가 되고 양수면 더 큰 값이 나오게 하기 떄문에 학습에 조금 더 긍정적인 영향을 미칠 수 있습니다.
Dimension Cluster, Direct location prediction을 적용하는 경우 mAP가 5% 상승합니다.
Fine-Grained Feature
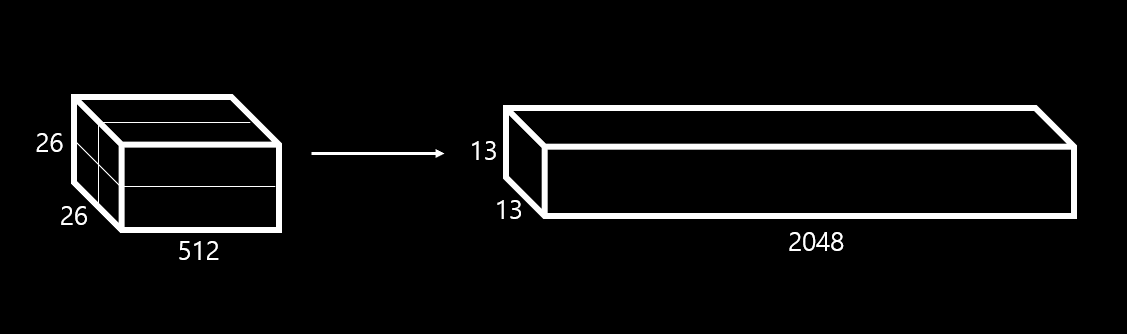
Yolov2는 13x13 feature map을 예측하는데 13x13은 큰 object를 검출하는데 충분하지만 작은 object를 검출하는데 좀 더 세밀한 특징을 원합니다. 이러한 문제를 해결하기 위해서 SSD같은 경우는 여러 level의 특징 맵에서 검출을 합니다. YOLOv2의 경우 26x26 feature map을 그대로 가져오는 방법을 사용합니다.
1
26 x 26 x 512 --> 13 x 13 x 2048
이를 통해서 mAP가 1% 상승합니다.
Multi-Scale Training
- 416x416 입력 이미지를 사용합니다. fully connected layer를 제거했기 때문에 입력 크기는 어떤 것이 들어와도 문제가 없습니다.
- 다양한 해상도를 가지는 이미지에서 동작하기 원하기 때문에 다양한 해상도를 학습시킵니다. 10번 배치마다 32배수로 resize 됩니다.(320, 352, 608) 가장 작은 때는 320x320이고 가장 클 때는 608x608입니다.
- 낮은 해상도의 경우 성능이 꽤 좋습니다. 228x228 입력 이미지의 경우 초당 90 프레임이 나오며 mAP는 Fast R-CNN과 비슷합니다.
Faster
Darknet
- 3x3 filter를 사용하고 모든 pooling 이후 channel 수를 2배로 합니다.
- 19개의 convolutional layer
- 5개의 maxpooling layer
- batch normalization
- Imagenet Top-1 : 72.9% Top-5 : 91.2%
Training for classification
- 160 epoch
- SGD(learning rate = 0.1)
- polynomial rate decay : a power of 4
- weight decay : 0.00005
- momentum : 0.9
- 처음에 224x224로 finetuning하고 448x448 fine tuning
Training for detection
- 마지막 convolutional layer를 제거하고 3x3x1024 convolutional layer 추가
- 그 뒤에 1x1 convolutional layer 추가
- 5개의 bounding box를 예측
- 125개의 예측값 = 5 x (5(objectness, x, y, w, h) + 20(class))
- 160 epoch
- weight decay : 0.00005
- momentum : 0.9
Stronger
YOLO9000
- Detection과 Classification 데이터 셋을 섞어서 학습 합니다.
- Detection문제를 다루는 Pascal VOC, COCO 데이터 셋은 개, 고양이, 자동차와 같이 포괄적인 라벨링을 합니다.
- Classification문제를 다루는 ImageNet 데이터 셋은 개(Norfolk terrier, Yorkshire terrier, …)과 같이 세밀한 라벨링을 합니다.
위와 같이 Detection, Classification 데이터 셋을 합치기 위해서는 일관적인 라벨링이 필요합니다.
보통 Classification을 하는 경우에는 Softmax를 사용하는데 Softmax는 각 클래스가 상호 배타적이라고 가정합니다. 하지만 Norfolk terrier, Yorkshire terrier는 개로 분류되야 합니다. 그래서 YOLO9000을 만들기 위해서 라벨이 상호 배타적이지 않다는 가정을 한 Multi-label model을 사용합니다.
Hierachical classification
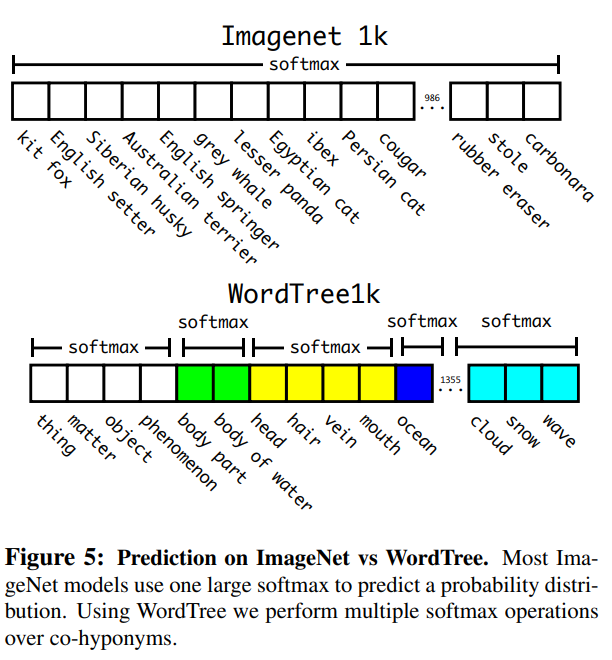
ImageNet의 라벨은 WordNet기반으로 구성됩니다. WordNet은 Language Dataset로 개념과 단어 사이의 관계를 표현합니다. 예를 들어 Yorkshire terrier는 terrier의 하의어고 terrier는 hunting dog 타입이며 hunting dog는 dog 타입입니다. YOLO9000은 ImageNet이 가지는 개념으로부터 계층적 트리(WordTree)를 만들어서 문제를 단순화 시킵니다.

terrier노드에서는 위와 같이 계산됩니다. 만약 Norfolk terrior라는 것을 알고 싶다면 아래와 같이 계산됩니다.

분류 문제로 모든 이미지에는 obejct가 존재한다고 가정합니다. 즉, \(Pr(physical object) = 1\)
WordTree를 만들기 위해서 1000개의 클래스를 가지고 있는 ImageNet을 사용해 DarkNet-19 모델을 학습시킵니다. WordTree를 만들기 위해서는 중간 중간 노드를 추가 해야하기 때문에 1369개가 되고 실제 label을 역추적해서 Norfolk terrier는 개, 포유류라는 라벨도 같이 얻게 됩니다. 결국 조건부 확률을 계산하기 위해서 1369개의 class확률을 예측해야합니다.
하의어에 대해서 Softmax를 계산합니다.
- top-1 : 71.9%
- top-5 : 90.4%
Classification의 경우 개의 종류가 불분명하다면 개에 대해서는 높은 신뢰도를 전파하지만 하의어에는 낮은 신뢰도를 전파합니다. Detection의 경우 bounding box에 있는 object가 무엇인지 높은 신뢰도를 갖는 경로를 따라가고 threshold가 나오기 전까지 계속 내려갑니다.
Dataset combination with WordTree

COCO와 ImageNet을 합쳐서 WordTree를 만듭니다.
Joint classification and detection
- COCO와 ImageNet의 상위 9000개의 클래스 데이터 셋을 조합해 매우 큰 Detector를 학습시켰습니다.
- WordTree는 총 9418개의 클래스를 갖고 ImageNet의 데이터 수가 COCO보다 많기 때문에 COCO를 4배 over sampling합니다.
- 학습할 떄 classification과 detection을 섞어서 사용 합니다.
- Detection image의 경우 기존 loss를 역전파를 합니다.
- Classification loss는 label이 dog라면 WordTree의 상위 노드는 알 수 있지만 하위 노드는 알 수 없기 때문에 하위 노드에 에러를 할당하고 상위 노드에만 역전파를 진행합니다.
- Classification image의 경우 classification loss만 역전파를 합니다. 이렇게 하면 bounding box를 검출시 classification 확률이 높아집니다. bounding box도 ground truth와 0.3 IOU 이상인 경우만 objectness loss를 역전파 합니다.
- Detection 성능(mAP) : 19.7%, 전혀 본적없는 label 추가 성능(mAP) : 16.0%
- 동물 데이터는 학습을 잘하지만 의류 데이터는 학습을 잘 못합니다.