D-FINE 톺아보기
- Paper: D-FINE: REDEFINE REGRESSION TASK IN DETRS AS FINE-GRAINED DISTRIBUTION REFINEMENT
- Github: https://github.com/Peterande/D-FINE
D-FINE은 Fine-grained Distribution Refinement (FDR) 및 Global Optimal Localization Self-Distillation (GO-LSD) 두 가지 핵심 기술을 도입하여 기존 DETR 모델을 개선한 객체 탐지 모델이다.
Fine-grained Distribution Refinement (FDR)

기존 객체 탐지 모델들은 경계 상자를 고정된 좌표로 직접 예측하는 방식을 사용하지만, 이 방법은 작은 변화에도 취약하며, 모델이 위치 불확실성을 반영하지 못하는 단점이 있다. FDR은 이러한 문제를 해결하기 위해 확률 분포 기반의 위치 정제 방식을 도입한다.
FDR에서는 각 박스의 경계를 단일 값이 아닌 확률 분포로 모델링하며, 이를 반복적으로 정제하여 최종 위치를 결정한다. 이를 수식으로 표현하면 다음과 같다.
\[d_l = d_0 + \{ H, H, W, W \} \cdot \sum_{n=0}^{N} W(n) Pr^l(n) , l \in \{ 1, 2, . . . , L \},\]여기서, $d_l$은 $l$ 번째 디코더 레이어에서 정제된 경계 상자 좌표를 의미하며, $d_0$은 초기 예측된 경계 상자이다. $W(n)$은 비균일 가중치 함수로, 특정 구간에서 더 높은 영향력을 부여하여 세밀한 조정을 가능하게 한다. $Pr^l(n)$은 $n$ 번째 경계 후보에 대한 확률 분포로, 이는 softmax를 통해 정규화된다.
이를 통해 모델이 점진적으로 위치 정밀도를 향상시킬 수 있으며, 다음과 같은 반복적인 정제 과정을 거친다.
\[Pr^l(n) = \text{Softmax}\left( \Delta \text{logits}^l(n) + \text{logits}^{l-1}(n) \right)\]여기서, $\Delta \text{logits}^l(n)$은 이전 단계에서 학습된 분포의 보정 값이며, 이를 누적하여 점진적으로 더 정교한 예측이 이루어진다.
Global Optimal Localization Self-Distillation (GO-LSD)
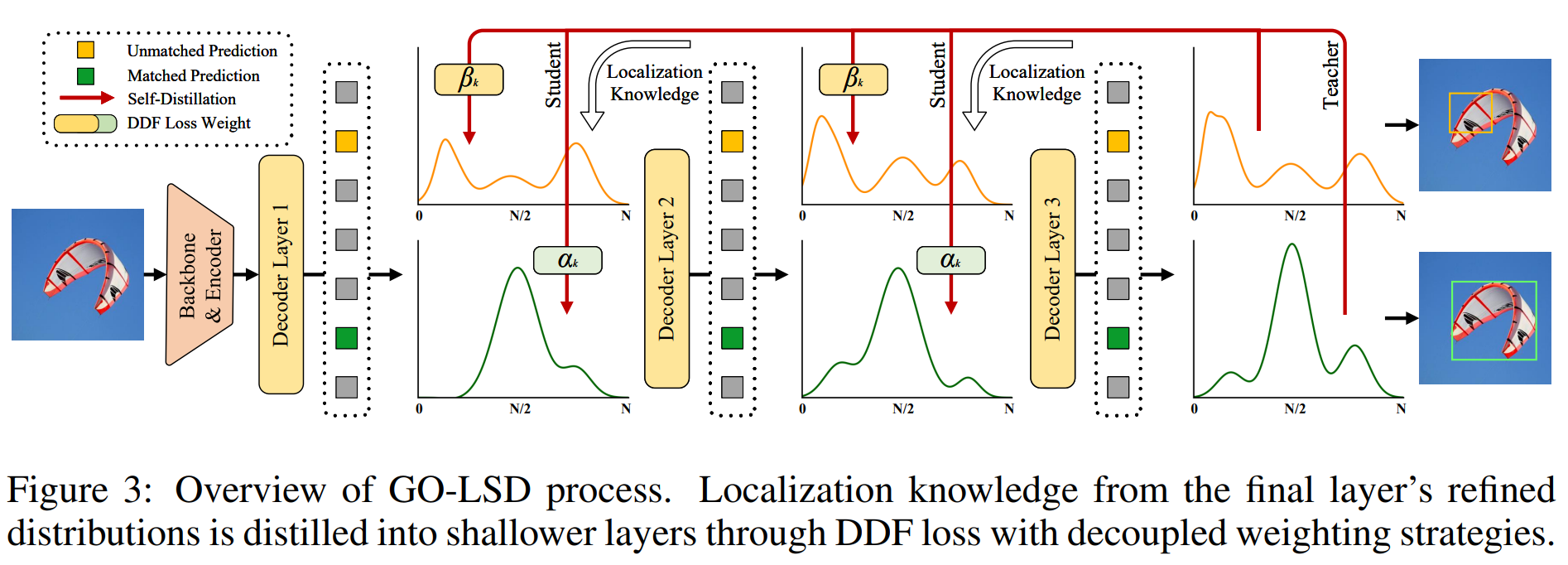
GO-LSD는 깊은 층에서 생성된 위치 정보를 얕은 층으로 전달하는 자기 증류(self-distillation) 기법이다. 이는 모델이 초기 단계에서부터 올바른 경계 상자를 학습할 수 있도록 도와준다.
\[L_{DDF} = T^2 \sum_{l=1}^{L-1} (\sum_{k=1}^{K_m} \alpha_k \cdot \text{KL}(Pr^l(n)_k, Pr^L(n)_k) + \sum_{k=1}^{K_u} \beta_k \cdot \text{KL}(Pr^l(n)_k, Pr^L(n)_k))\]여기서, $\text{KL}(P, Q)$는 Kullback-Leibler divergence (KL 손실)이며, 분포 간 차이를 최소화하는 역할을 수행한다. $\alpha_k$, $\beta_k$는 정합 및 비정합 예측의 가중치이며, $\alpha_k = \text{IoU}_k \cdot \frac{\sqrt{K_m}}{\sqrt{K_m} + \sqrt{K_u}}$이고, $\beta_k = \text{Conf}_k \cdot \frac{\sqrt{K_u}}{\sqrt{K_m} + \sqrt{K_u}}$이다. $Pr^L(n)$은 최종 레이어에서의 확률 분포로, 모델의 최적화 목표로 사용된다. 마지막으로, $T$는 logits을 부드럽게 하기 위해 사용되는 온도(temperature) 파라미터이다.
이 방식은 특정 레이어에서 예측한 박스의 정제된 결과를 얕은 층에서 참조하도록 유도하여 성능을 향상시킨다. 이를 통해 모델은 초기 학습 단계에서부터 정확한 위치 예측을 수행할 수 있도록 최적화된다.
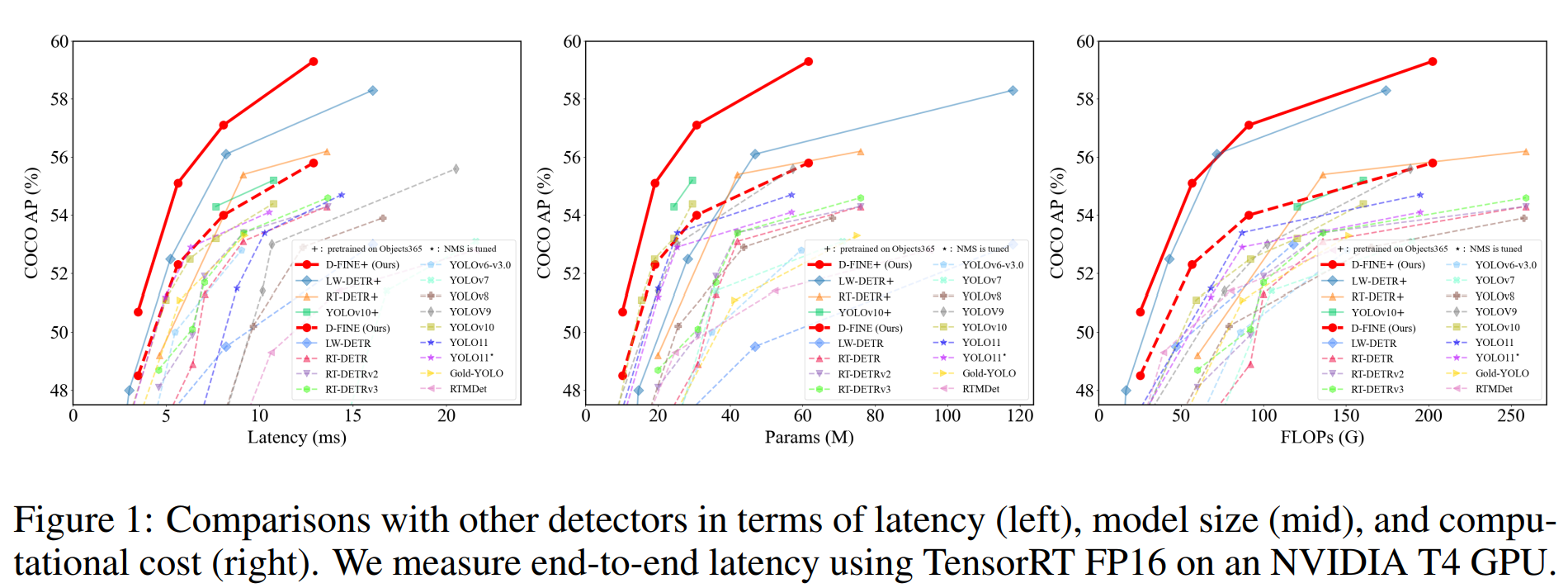
D-FINE은 COCO 데이터셋에서 기존 모델보다 뛰어난 성능을 보였다. D-FINE-L 모델은 54.0%의 AP를 기록하며 124 FPS를, D-FINE-X 모델은 55.8%의 AP를 기록하며 78 FPS를 달성했다. Objects365로 사전 학습한 경우, D-FINE-L 모델은 57.1% AP, D-FINE-X 모델은 59.3% AP를 기록했다.