CenterNet 톺아보기
이 당시에 초당 142 프레임에 28.1 AP
- AP : recall 값들에 대응하는 precision 값들의 average
CenterNet
(Object as Point)
요약
대부분의 모델은 이미지의
axis aligned box로 object를 식별한다. 대부분의 성공적인 object detetor들은 모든 잠재적 object 위치를 찾고 각각을 분류한다. 이러한 일은 낭비가 많고 비효율적고 추가적인 post-processing이 필요하다. 그래서 이 논문에서는 다른 접근법을 취한다.이 논문은 bounding box의 중심점인 단일점 으로 모델링한다. 이 논문의 detector는 keypoint estimation를 사용해서 중심점을 찾고 크기, 3D 위치, 방향, 자세와 같은 모든 다른 object의 속성으로 회귀한다.
- MS COCO 데이터셋에
Resnet18: 142FPS에서 28.1 APDLA34: 52FPS에서 37.4 APHourglass-104: 1.4FPS에서 45.1 AP
- KITTI 벤치마크에서 3D bounding box를 추정하고 COCO keypoint 데이터셋에서 사람의 자세를 계산하기 위해 동일한 접근법을 사용한다.
소개
one stage detector는 이미지 위에 anchor를 옮기면서 box의 내용을 지정하지 않고 직접 분류한다.
two stage detector는 bounding box 각각에 대해 이미지의 특징을 다시 계산한 다음 해당 특징을 분류한다.
post-processing를 할 때 구별하기 어렵고 훈련이 어렵다. 그런데도 좋은 성공을 거두었다. Sliding window 기반의 object detector는 가능한 모든 object의 위치를 찾아야하기 때문에 자원이 낭비가 된다. 그래서 그에 따른 대안을 이 논문이 설명한다.
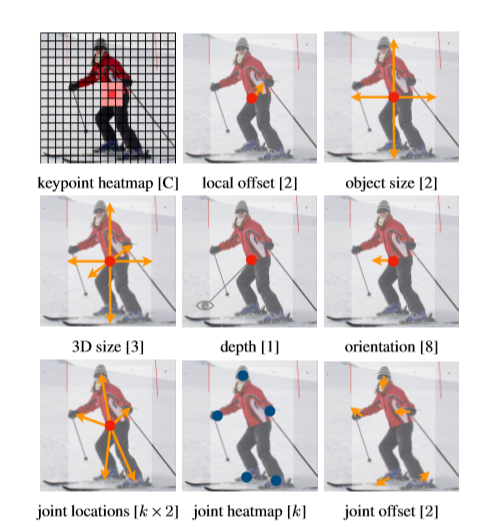
object detection은 표준 key point estimation 문제라고 정의했다. 히트맵을 생성하는 convolution network에 이미지를 넣어주기만 하면 된다. 이 히트맵의 peaks는 물체 중심에 해당하고 각 peaks의 image feature는 bounding box의 높이 및 두께를 예측한다.
이 논문은 각 중심점에서 추가적인 출력을 예측하여 3D object detection 및 다중 사람 자세 추정에 대한 실험을 제공한다. 3차원 bounding box를 추정하기 위해서 object의 깊이, 3D bounding box의 크기, object의 방향을 회귀한다.

Related work
Object detection by region classification
가장 먼저 성공적인 object detectors 중 하나인 RCNN은 많은 region 후보들로 부터 대상 위치를 찾고 각각을 deep network를 사용하여 분류한다. 그러나 성능이 좋지않은 region proposal 방법에 의존한다.
Object detection with implicit anchors
Faster RCNN는 region proposal을 생성한다. 저해상도 이미지 격자 주위에 고정된 모양의 bounding box(anchor box)를 sampling하고 각각을 foreground background로 분류한다. anchor는 모든 ground truth에서 0.7보다 크면 foreground로 표시되며 0.3보다 작으면 background로 표시되거나 무시된다.
1
2
3
Anchor shape priors : YOLOv2,YOLOv3
Different feature resolution : SSD
Loss re-weighting : Focal loss for dense object detection
이 논문 또한 anchor기반 1단계 검출기와 밀접하게 연관이 되어 있지만 몇가지 중요한 차이점이 있다.
CenterNet은 box의 겹침이 아닌 위치에 기반하여 “anchor”를 할당한다. foreground와 background에 대한 임계값이 없다.
object당 하나의 anchor만 있기에 NMS(NonMaximum Suppression)가 필요하지 않다. 단순히 keypoint 히트맵에서 peak를 추출한다.
CenterNet은 기존의 object detector과 비교해서 더 큰 출력 해상도를 사용한다. 이것이 다중 anchor의 필요성을 제거한다.
Object detection by keypoint extimation
object detection을 위해서 keypoint 추정방법을 사용하는 것이 처음은 아니다.
CornerNet은 두 개의 bounding box의 모서리를 keypoint로 detection을 한다.ExtremeNet은 모든 object의 상단,좌측,하단,우측 및 중심점을 detection한다. 이 두가지 방법 모두 CenterNet과 동일한 keypoint 추정 네트워크를 기반으로 한다. 그러나 keypoint 추정후 그룹화 단계가 필요하고 그에 따라서 알고리즘 속도가 현저히 줄어든다. 반면 CenterNet은 그룹화 또는 후처리 작업 없이도 object당 하나의 중심점만 추출한다.
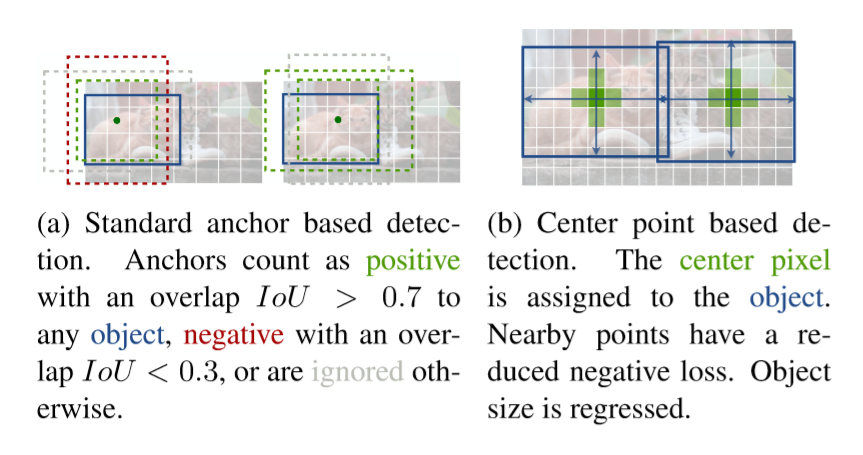
Preliminary
- W인 폭과 H인 높이를 가진 이미지 : \(I \in R^{(W*H*3)}\)
- keypoint heatmap : \(\hat{Y} \in [0, 1]^{(\frac{W}{R} * \frac{H}{R} * C)}\)
- R : output stride
- C : keypoint 유형의 수
- keypoint의 유형(사람의 자세를 추정) : C=17(사람 관절)
- object detection : C=80 범주를 포함한다.
- 기본적으로 R=4이다.
\(\hat{Y} \mid x,y,z = 1\) : keypoint
\(\hat{Y} \mid x,y,z = 0\) : background
이미지 \(I\)로부터 \(\hat{Y}\)를 예측하기 위해
Hourglass Network를 사용한다.ground truth keypoint : \(p \in R^{2}\)
저해상도 : \(\hat{p} = [\frac{p}{R}]\)
- gaussian kernel
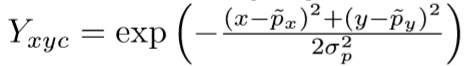
gaussian kernel을 사용하여 히트맵 \(\hat{Y} \in [0, 1]^{(\frac{W}{R} * \frac{H}{R} * C)}\)에 모든 ground truth keypoint를 둔다. 여기서 σ(p)는 object size-adaptive 표준편차이다.
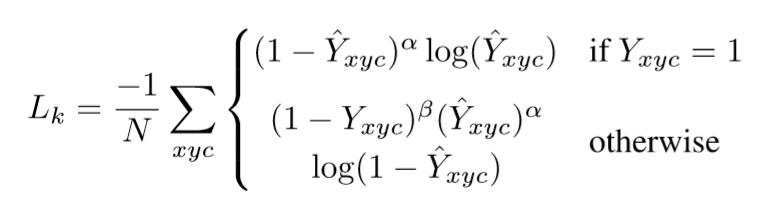
- \(\alpha, \beta\) : focal loss의 hyper parameter
- \(N\) : 이미지 I의 keypoint의 수이다. 모든 양수의 focal loss를 1로 정규화하기 위해 선택된다.
- Law and Deng을 따라서 \(\alpha\) = 2, \(\beta\) = 4 로 정했다.
- output stride에 의해 발생된 수학적 오류를 복구하기 위해서 local offset을 각 중심점마다 추가로 예측한다. : \(\hat{O} \in R^{(\frac{W}{R} * \frac{H}{R} * 2)}\)
모든 클래스 c는 동일한 offset 예측을 사용하는데 offset은 L1 loss로 훈련된다.
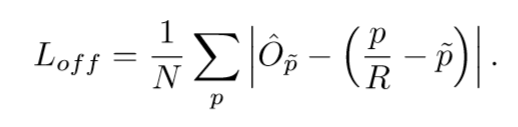
Objects as Points
범주 C(k)를 갖는 대상 k의 bounding box가 \(x1,y1,x2,y2\) 라고 하자.
- 중심점 : \(p(k) = (\frac{x1+x2}{2},\frac{y1+y2}{2})\)
- 예측 keypoint \(\hat{Y}\)을 사용해서 모든 중심점을 예측
- 각 object k에 대해 \(s(k) = (x2-x1,y2-y1)\)로 회귀
- 계산적인 부담을 줄이기 위해 모든 object 범주에 대해 단일 크기 예측 \(\hat{S} \in R^{(\frac{W}{R} * \frac{H}{R} * 2)}\)을 사용한다.
- L1 loss를 사용
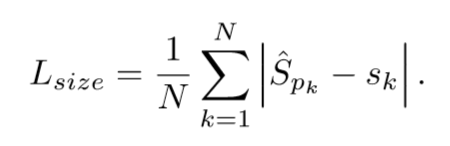
scale을 표준화하지 않고 원본 픽셀 좌표를 직접 사용한다. 대신 loss를 일정한 λsize로 조정한다.
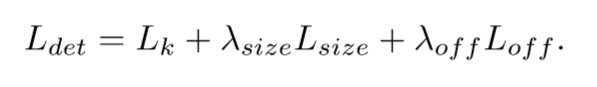
논문에서 달리 명시하지 않는이상 모든 실험에서 \(\lambda size = 0.1\) 와 \(\lambda off = 1\)로 설정했다.
keypoint \(\hat{Y}\), offset \(\hat{O}\), 크기 \(\hat{S}\)를 예측한다. 즉, 네트워크는 각 위치에서 총 C+4개의 output을 예측한다. 각 형태에 대해서 backbone의 특징은 별도의 3x3 convolution, relu와 다른 1x1 convolution을 통과한다.
From points to bounding boxes
추론을 할때, 먼저 각 범주에 대한 히트맵의 peaks를 추출한다. 값이 8개의 연결된 이웃들 보다 크거나 같은 모든 응답을 detection하고 최고 100개의 peaks를 유지한다. \(\hat{P}(c)\)는 클래스 c의 n개의 검출된 중심점 \(\hat{P} = {(\hat{xi},\hat{yi})}(i = 1~n)\) 의 집합이라고 하자. 각 keypoint의 위치는 정수 좌표 (xi,yi)로 표시된다. keypoint 값 \(\hat{Y}\mid x,y,z\)를 신뢰도와 동일하게 사용하고 위치에 bounding box를 생성한다.
- offset 예측 : \((\hat{\delta }(xi) , \hat{\delta }(yi)) = \hat{O}(\hat{xi},\hat{yi})\)
- 크기 예측 : \((\hat{wi},\hat{hi}) = \hat{S}(\hat{xi},\hat{yi})\)
- keypoint 예측의 모든 출력은 IoU기반 NMS(Non Maximum Suppression) 또는 기타 후처리가 필요없다.
Implementation details
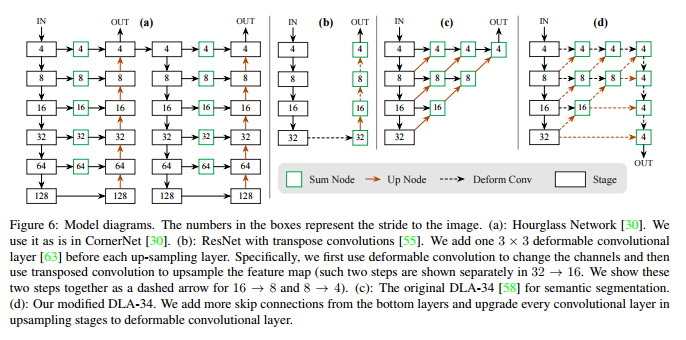
이 논문은 ResNet-18, ResNet101, DLA-34, Hourglass-104의 4 가지 아키텍처를 실험한다. deformable convolution layer를 사용하여 ResNet과 DLA-34를 수정하고 Hourglass network를 그대로 사용한다.
Hourglass
Hourglass Network는 input을 4배씩 downsampling하고 순차적인 두개의 Hourglass modules을 따른다. 각 Hourglass modules는 skip connection을 사용하는 대칭 5 layer down- and up-convolution network다. 이 네트워크는 꽤 큰 모델이지만 일반적으로 최상의 keypoint 추정 성능을 가지고 있다.
ResNet
고해상도 출력을 하기 위해서 3개의 up-convolution network를 사용하여 residual network을 강화했다. 계산을 저장하기 위해 먼저 3개의 upsampling layer의 채널을 각각 256,128,64로 변경한다. 그런 다음 각각 up-convolution 전에 3x3 deformable convolution layer를 추가한다. up-convolution kernel은 선형 보간으로 초기화된다.
DLA
DLA(Deep Layer Aggregation)는 hierarchical skip connection을 사용하는 이미지 분류 네트워크다. 밀도 예측을 위해 DLA의 fully convolution upsampling 버전을 사용하며 feature map의 해상도를 높이기 위해 반복적으로 deep aggregation을 사용한다. low layer 에서 output까지 deformable convolution layer를 사용해서 skip connection을 강화한다. 구체적으로 원래 convolution을 모든 upsampling layer에서 3x3 deformable convolution layer으로 바꾼다.
Training
input: 512x512 /output: 128x128data argument: random flip, random scaling, cropping, color jiteringoptimize: Adam
cropping, scaling이 3D 측정값을 변경시키기 때문에 argumentation을 사용하지 않는다.
residual network와 DLA-34
batch size가 128(8 GPU)이고learning rate가 140 epoch 동안 5e-4 이며 90과 120 epoch에서는 각각 10배씩 줄인다.downsampling layer는 image Net의 pretrain으로 초기화되고 upsampling layer는 무작위로 초기화 된다.
Hourglass-104
ExtremeNet을 따르고 배치 크기를 29(5 GPU), 40 epoch에서 10배 줄이고 50 epoch에서 학습 속도 2.5e-4를 사용한다. detection 하기 위해 ExtremeNet에서 Hourglass-104를 계산해 계산량을 절약한다.
Inference
3 가지 등급의 test argumentation을 사용한다 :
no argumentation,flip argumentation,multi scale(0.5,0.75,1.25,1.5)flip의 경우 bounding box를 decoding 하기 전에 네트워크의 output의 평균을 구한다.
multi scale의 경우 NMS를 사용하여 결과를 합친다.
Experiments
- train image : 118K
- validation image : 5k
- test image : 20k
- IOU thresholds : 0.5
성능이 출력이 적어지고 box의 decoding 방식이 단순해짐으로 인해서 속도가 높다.
Additional experiments
운이 안좋은 환경에서는 두개의 서로 다른 물체가 완벽히 정렬해서 같은 중심을 공유 할 수 있다. 이런 시나리오가 발생하면 그 중 하나만 검색한다.
Center point collision
COCO 훈련 데이터셋에서 stride 4 에 동일한 중심점에 충돌하는 614쌍의 물체가 있다. 총 860001 개의 물체가 있으므로 0.1 % 미만의 물체를 검출할 수 없다. RCNN보다 좋다.
NMS
CenterNet에서는 NMS가 필요하지 않아서 후처리를 이용했다. 성능은 조금더 좋거나 거기서 거기다.
Train and Testing resolution
훈련동안 input의 해상도는 512x512로 고정된다. CenterNet을 사용해 원본 이미지의 해상도를 유지하고 네트워크의 최대 stride에 대해서 input에 zero padding을 적용시킨다. ResNet이나 DLA의 경우 최대 32픽셀 Hourglass의 경우 128픽셀을 사용한다. 원래의 해상도를 유지 시키지 않고 저해상도를 사용할 경우 속도는 높아지지만 정확성은 떨어진다.
Regression loss
vanilla L1 loss를 Smooth L1에 비교한다. L1보다 Smooth L1이 좋다.
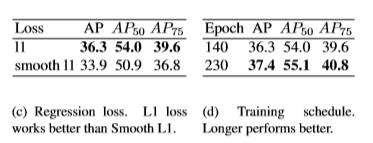
Bounding box size weight
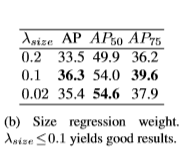
0.1이 좋은 결과이며 더 큰값의 경우 AP는 0~1 대신 출력 크기 W/R 또는 H/R 범위로 인해 크게 저하된다.
Training schedule
기본적으로 keypoint estimation network를 훈련하는 140 epochs 동안 90 epochs에서 learning rate이 감소한다. learning rate를 떨어뜨리기 전에 훈련을 두배로 늘리면 성능은 1.1 AP 만큼 오른다.
3Ddetection
- KITTI 데이터셋
KITTI는 7841개의 훈련 이미지를 포함하고 있다. 2D 경계상자, 방향, Bird-eye-view bounding box를 기반으로 IOU를 평가한다. 훈련과 테스트를 위해 원본 이미지의 해상도는 1280x384로 유지한다. 훈련은 70 epochs로 수렴하고 45와 60 epoch마다 learning rate가 떨어진다. DLA-34 backbone을 사용해 깊이, 방향, 면적에 대한 loss weight를 1로 설정한다. recall thresholds 의 수가 매우 적어서 validation AP는 최대 10% AP 만큼 변한다. 다른 RCNN 보다 BEV(bird eye view)가 더 좋고 속도가 빠르다.
pose estimation
- MS COCO 데이터셋
bounding box AP와 유사하지만 bounding box IOU를 object의 keypoint 유사성으로 대체하는 keypoint AP를 평가한다. 먼저 DLA-34와 Hourglass-104를 중심점 검출에서 fine-tuning 해서 실험한다. DLA-34는 320 epochs로 수렴하고 Hourglass-104는 150 epochs로 수렴한다. 모든 추가적인 loss weight를 1로 설정한다. keypoint의 직접 회귀는 합리적으로 수행되지만 최첨단에서는 수행이 안된다. 가장 가까운 관절 detection으로 결과물을 투사하면 전반적으로 결과가 개선되고 최첨단 기술자들과 경쟁할 수 있다. CenterNet이 일반적이며 새로운 작업에 쉽게 적응할 수 있다는 사실을 확신 할 수 있다.

결론
object에 대한 새로운 표현을 포인트로 제시한다. object의 center를 찾아내어 box크기를 regression한다. 이 알고리즘은 NMS 후처리 과정없이 간단하고 빠르고 정확하다.
MODEL
용어 정리
axis aligned bounding box
줄여서 AABB라고도 불리는 축에 정렬된 경계 상자이다.
물체가 회전을 해도 경계 상자는 회전하지 않고 box의 최소점과 최대점을 가지고 충돌 비교를 한다.
2D가 아니고 3D의 개념이다.
NMS
후처리 단계이다. 그것은 object detection 에서 각각의 검출된 object에 대해 하나의 bounding box에 있는 많은 부정확한 물체 window hypotheses를 유발하는 smooth response map을 변환하는데 사용한다. 이상적으로 각 object에 하나의 bounding box가 있어야한다.
heatmap
열분포 형태의 지도
outstride
우리가 기본적으로 필터가 얼마만큼 이동할지에 대해서 말할때 stride라고 하는데 그것은 input stride이고 output stride라는 말은 예를 들어 이미지가 224 * 224이고 마지막 특징맵이 7 * 7이면 output stride는 32이다. 즉, downsampling이 얼마나 되었는지에 대한 근사치이다.
backbone
backbone이란 등뼈라는 뜻을 가지고 있다. 등뼈는 뇌와 몸의 각 부위의 신경을 이어주는 역할을 한다. backbone은 입력이 처음 들어와서 출력에 관련된 모듈에 처리된 입력을 보내주는 역할이라고 생각할 수 있다. 결국 object를 검출하거나 영역을 나누던가 신경망 네트워크는 입력 이미지로 부터 다양한 feature를 추출해야하고 그 역할을 backbone이 한다.
bin
히스토그램의 한 cell
Hourglass Network
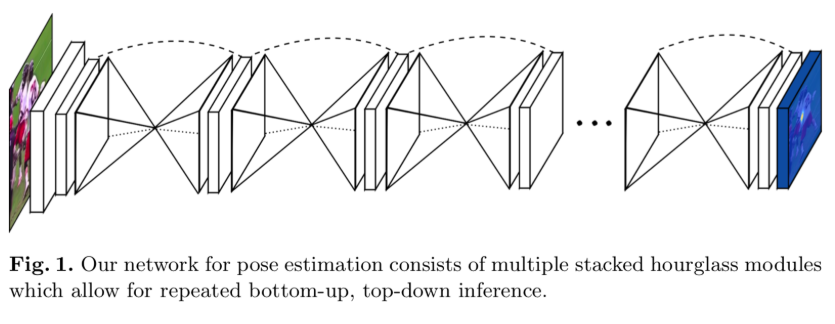
dimension을 축소/증가를 시키면서 마치 모래시계와 같은 구조의 네트워크다.
선형 보간
끝과 끝의 값이 있을 때 그 사이에 위치한 값을 추정하기 위해 직선 거리에 따라 선형적으로 계산하는 방법으로 이미지를 복구하고 부족한 부분을 채우는데 많이 사용된다.
DLA
- Deep Layer Aggregation
layer를 집계하여서 output을 추출하는 네트워크다.
deformable convolution layer
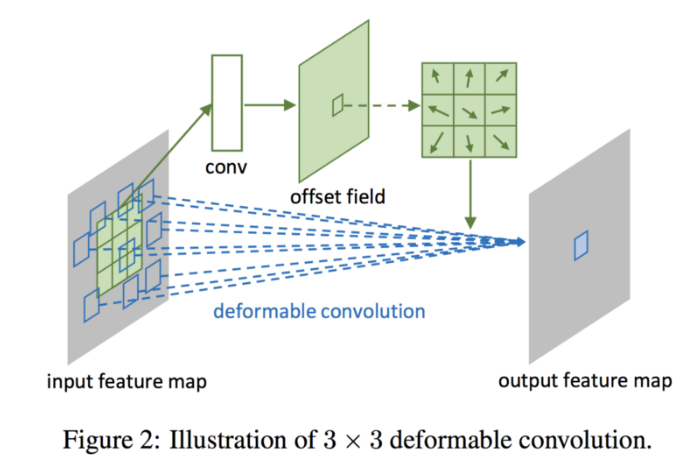
일정한 CNN의 패턴의 한계를 극복하려고 만든 네트워크다. 2D offset을 다양하게 더해서 convolution layer를 동적이게 변형시키는 것
color jitering
이미지의 채도를 랜덤하게 노이즈를 주는 data argumentation 방식 중 하나
참조
- Hourglass image : https://arxiv.org/abs/1603.06937
- CenterNet image : https://arxiv.org/abs/1904.07850
- deformable convolution layer : https://arxiv.org/abs/1703.06211
- CenterNet code : https://github.com/xingyizhou/CenterNet